

서론
화석 연료 고갈에 대비한 대체에너지를 개발하고 지구온난화를 유발하는 메탄가스 등 온실가스를 저감할 필요성이 전 세계적으로 제기되고 있으며, 우리나라는 기후변화협약 당사국으로 국가 온실가스 배출량을 산정하고 국가보고서의 형태로 보고하여야 할 의무를 부여받고 있다(Ministry of Environment, 2006). 한국은 2030년 온실가스 배출전망치 대비(BAU) 37% 감축 목표를 제출했으며, 유럽연합은 2030년까지 절대량 40% 감축을 목표로 제출 했으며, 중국은 2030년까지 국내총생산(GDP) 대비 배출량 기준 60~65% 감축을 목표로 하고 있다(Korea Energy Economics Institute, 2016).
우리나라는 전 세계가 주목하고 있는 OECD 회원국으로 파리협정 이후 온실가스저감 대비가 긴요한 상황이므로, 온실가스를 제거할 수 있는 방안을 찾아야 한다. 기후변화 협약은 세계 각국이 지속가능한 성장을 위해 공동의 노력을 기울여 대기 중의 온실가스 농도를 안정화시킴으로써 지구의 환경변화를 최소화하는 목표를 가지고 있다. 이러한 온실가스 감축 목표를 달성하기 위해서는 국내 각 부문별 전략이 필요한 상황이다. 지구 온난화를 유발하는 메탄가스 등 온실가스를 저감할 필요성이 제기되고 있는 가운데 태양광, 풍력, 폐기물 등을 이용한 신재생 에너지원은 현실적으로 무한한 개발 잠재력을 갖고 있고 실질적인 부가가치를 창출하는 자원으로 각광 받고 있다. 특히 매립가스 자원화는 이미 선진국에서 오래 전부터 진행해 왔던 사업이며 국내에서도 매립가스를 이용한 발전시설이 운영되고 있다.
2016년 전 세계의 이목을 집중시킨 구글 딥마인드의 인공지능 바둑 프로그램인 알파고(AlphaGo)의 등장은 인공지능과 이를 구현하는 기계학습, 딥러닝 기법에 대한 관심을 급속도로 확산시킨 계기가 되었다. 인공지능(Artificial Intelligence, AI)이란 사고나 학습 등 인간이 가진 지적 능력을 컴퓨터를 통해 구현하는 기술이며(Won et al., 2016) 인간처럼 생각하고 행동하며 이성적으로 생각하며 행동하는 시스템으로 정의하였다(Russell et al., 2003). 인공지능을 구현하기 위해서는 데이터가 필요하며, 양질의 많은 데이터를 보유할수록 인공지능은 우수해질 수 있다(LeCun et al., 2015). 신재생에너지 분야도 이러한 변화의 물결 속에 데이터 및 인공지능을 활용한 매립가스 발전소 서비스 개발 요구가 증대되고 있다. 그러나 W시 매립장 매립가스 발전소에서 기록되고 있는 메탄가스 농도, 이산화탄소 농도, 황화수소 농도, 전력생산량, 가스 소모량, 온도, 강우량 데이터를 이용하여 기계학습 또는 딥러닝 분석을 한 연구는 거의 없는 실정이다.
본 연구에서는 매립가스 발전소 운영에 필요한 빅데이터 · 인공지능 모델 개발의 일환으로 매립장 매립가스 발전소를 대상으로 발전소 운영 데이터들을 검토하여 데이터들 간의 관계를 알아보고, 딥러닝 기법을 적용하여 이러한 관계를 학습 · 추정하는 인공지능 모델을 구축하는 것을 목표로 한다. 현재, IPCC(Intergovernmental Panel on Climate Change)에서는 매립장에서 발생하는 메탄발생량 산정방법의 일관성을 유지하기 위해 전 매립지에 대해 동일한 방법을 적용하도록 권고하고 있으며(IPCC, 1997), 매립장에서 발생되는 매립가스를 포집하기 위해서는 포집공을 통하여 포집하게 된다. 포집공은 발전기 시설에 설치된 루츠 브로워(Roots Blower)를 통해 매립가스를 강제포집하게 되며, 폐기물층에서 발생하는 매립가스 뿐만 아니라 대기중의 공기도 복토층을 통해 유입된다. 포집공에 전달되는 흡입압력, 복토층의 투과성, 폐기물 층의 수평 및 수직 투가속도 등 여러 요소들은 포집공별로 각각 다르게 작용한다(Fabbricino, M, 2007). 아직 국내에서는 포집공별로 온도, 강수량, 포집량 변동에 따른 포집공 농도 변화 분석이 거의 없는 상황이며, 매립가스 농도가 포집공별로 상이하기 때문에 이러한 자료에 대한 분석이 매우 중요하다. 포집공 조절을 잘 못할 경우 저농도의 메탄가스 유입과 고농도의 산소가 유입하게 되면 매립가스 발전기 출력이 일정하지 못하고 부하 변동이 크게 움직이게 되는 헌팅 증상(Hunting)이 발생하여 가동을 중단하게 된다. 또한, 이렇게 충격을 받은 포집공은 폐쇄하여 정적한 메탄가스 농도를 유지할 수 있는 시점까지 사용을 못하게 된다.
특히 포집공의 메탄가스 농도는 계절 및 시간, 대기 조건 및 환경에 따라 변동이 심하기 때문에 메탄가스 농도 변화 추정이 시급하다. 따라서 본 연구는 W시 매립장의 2017년 1월부터 11월 중 88일간의 매립가스 데이터를 이용하여, 딥러닝 기법을 적용하였다. 그리고 포집공별 매립가스 11개월간 데이터를 이용하여 메탄가스 농도를 추정하고 그 결과를 비교하였다. 본 연구 결과를 바탕으로 인공지능 융합기술로 발전시켜나간다면 향후 발전소 운영에 많은 부분이 예측 될 수 있을 것으로 예상한다.
연구 내용 및 방법
본 논문은 딥러닝 이론, W시 매립장 특징, 수직포집공의 매립가스 성분 분석 순으로 진행된다. 각 단계별 연구내용을 정리하면 딥러닝 이론에서는 딥러닝의 개요 및 이론과 적용 방법에 대해 검토하며, 실험 대상 매립장의 특징에서는 매립장 구성과 특징을 조사한다. 딥러닝 기반 추정 모형에서는 모델링한 딥러닝 모형 및 파라미터, 데이터셋 설명, 정확도 측정 방법에 대해 살펴본다. 그 후, 포집공별 매립가스 변화 추정 실험결과 및 고찰에서 실험결과에 대해 종합한다.
본 연구는 2017년 1월~11월중 88일에 대한 23개의 수직포집공을 통해 입수된 데이터를 이용하여 실험하였다. 딥러닝 DNN(Deep Neural Network) 구조를 구현하여 매립가스의 실제 측정값과 딥러닝 기법을 통해 산출된 메탄가스 농도를 비교하였다. 딥러닝 프레임워크는 구글의 오픈소스 라이브러리인 텐서플로우(Tensorflow)를 사용했다. 텐서플로우는 기계 학습과 딥러닝을 위해 구글에서 만든 오픈소스 소프트웨어 라이브러리로서, 데이터 플로우 그래프(Data Flow Graph)를 사용하여 수치 연산을 하게 된다(Kim, 2015). 텐서플로우는 딥러닝뿐만 아니라 강화학습의 각종 알고리즘도 동시 지원하며, 텐서보드(TensorBoard)라는 시각화 도구를 제공하여 사용자가 딥러닝 모델의 구성 및 텐서의 흐름을 볼 수 있게 하였다. 텐서플로우 외의 딥러닝 프레임워크로는 시아노(Theano), 카페(Caffe), 토치(Torch), 딥러닝포제이(DeepLearning4J)등이 있다(Abadi et al., 2016).
딥러닝 이론
인공지능(Artificial Intelligence, AI)이란 사고나 학습 등 인간이 가진 능력을 컴퓨터를 통해 구현하는 기술이다(Won et al., 2016). Russel and Norvig(2003)은 인공지능을 “인간처럼 생각하는 시스템, 인간처럼 행동하는 시스템, 이성적으로 생각하는 시스템, 이성적으로 행동하는 시스템”으로 정의하였다(Russell et al., 2003). 인공지능은 1956년 다트머스 대학에서 열린 컨퍼런스에서 처음 불리었으며, 이후로 인공신경망 이론의 발전과 궤를 같이 하다가 기계학습(Machine Learning)으로의 파생, 최근의 딥러닝으로 이어져 오고 있다.
딥러닝은 기계학습의 하나인 인공신경망이 발전된 형태의 인공지능이다. 인경신망이란 인간의 뇌를 모델로 하여 신경세포를 뉴런(Neuron)이라 하며, 뉴런은 신경세포체, 수상돌기, 축색돌기, 축색종말로 구성되어 있으며, 이러한 원리로 동작하는 뇌세포를 McCulloch-Pitt 뉴런(McCulloch et al., 1943)이라 부르며, Fig. 1과 같다.
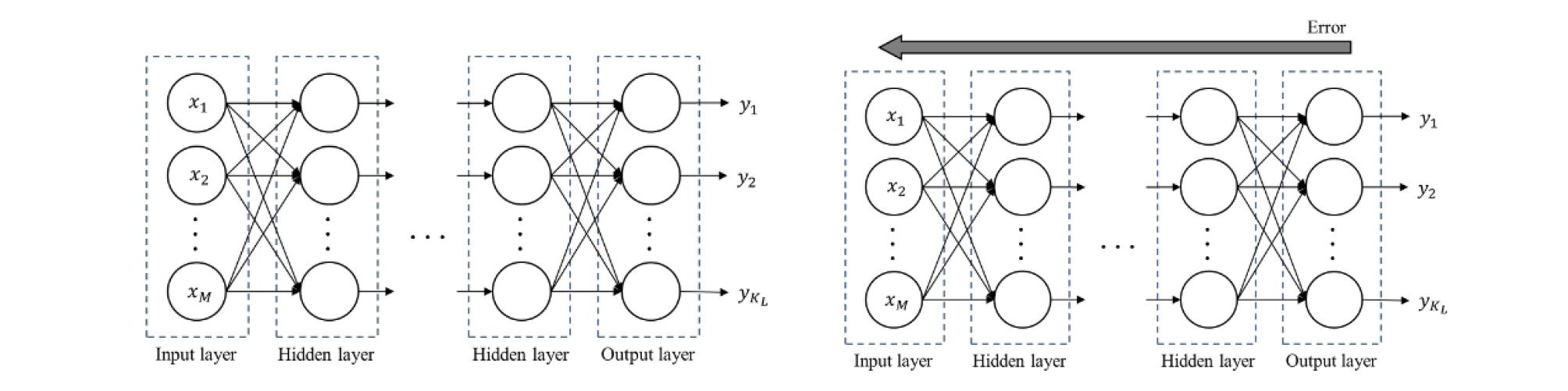
Rosenblatt은 MCP 뉴런모델과 가중치 개념을 바탕으로 퍼셉트론 모델을 제시하였고, 하나의 뉴런이 입력값에 가중치를 자동으로 학습하는 알고리즘이라고 소개하였다(Rosenblatt, 1958). 입력층(Input Layer)과 출력층(Output Layer)만으로 구성돼 있는 것을 단층 퍼셉트론(Single-Layer Perceptron, SLP)라 한다. 단층 퍼셉트론은 선형적인 분리는 가능하지만 비선형적으로 분리되는 데이터는 적용할 수 없다는 단점이 있었다. 이를 극복하기 위한 방안으로 입력층과 출력층 사이에 하나 이상의 은닉층을 두어 비선형적으로 분리되는 데이터에 대해서 학습이 가능한 다층 퍼셉트론(Multy-Layer Preceptron, MLP) 모델(Minsky et al., 1969)이 제시되었으며 Fig. 2와 같다.
실험 대상 매립장의 특징
W시 매립장은 1995년~2014년까지 약 20년간 생활폐기물이 매립되었고, 매립면적 163,780 m2, 매립용량 3,410천m3(약 250만톤)으로 1일 쓰레기 매립량은 388톤으로 cell 방식에 의한 준호기성 위생매립장이다(Ministry of Environment, 2014). 매립된 쓰레기는 분해되면서 메탄(CH4), 이산화탄소(CO2), 암모니아(NH3), 수소(H2), 황화수소(H2S)와 산소(O2) 등이 있고, 매립가스 중에 가장 많이 발생하는 메탄과 이산화탄소는 도시고형폐기물의 생분해성 유기물질의 혐기성 분해과정에서 발생되는 주요가스이다(Christensen et al., 1989).
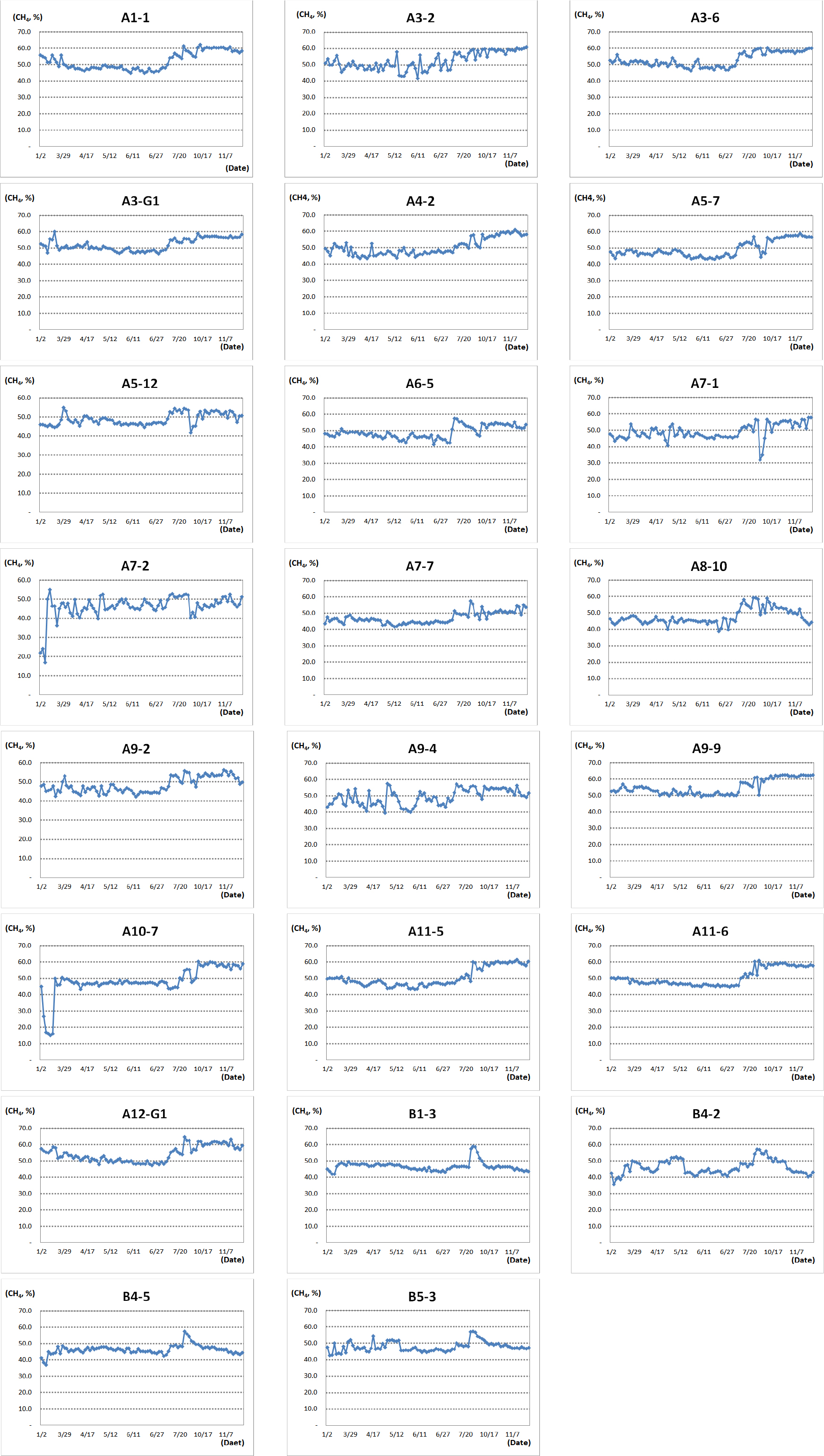
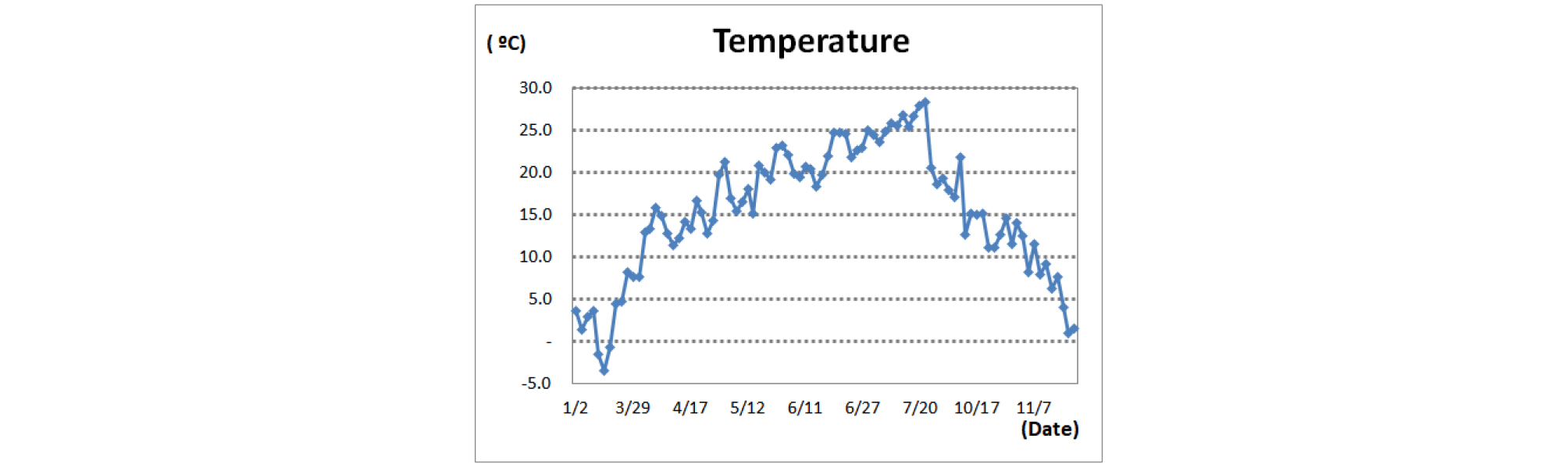
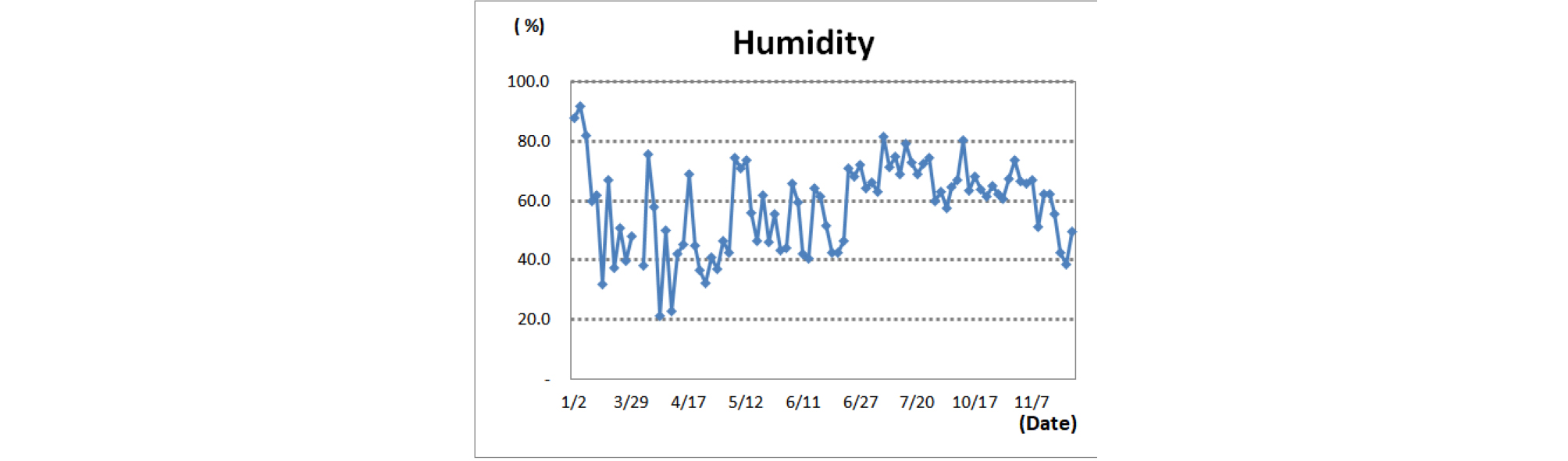
실험대상 매립장은 깊이 30 m의 계곡매립지 형태로 바닥 차수 및 침출수 차집관거가 매립지 전체에 설치되어 있다. W시 매립장은 제1매립장과 제2매립장으로 구분되어 있으며, 제1매립장은 2014년 매립이 종료되어 W시로 들어오는 쓰레기는 가연성 쓰레기를 제외하고는 제2매립장에 매립된다. 제1매립장에 포집공 128개를 설치하여 매립장에서 발생하는 매립가스를 포집하고 있다. 이중에서 지속적으로 사용하고 있는 23개 포집공의 메탄(CH4) 농도, 이산화탄소(CO2) 농도, 황화수소 농도 등을 2017년도 1월부터 11월까지 중에서 88일치 측정하였다. 측정 장비 및 측정 장소는 Fig. 3과 같다. 메탄(CH4) 농도 변화는 최대 64.7%, 최소 15%, 평균 49.6%로 측정되었으며 23개 포집공별 메탄(CH4) 농도 변화는 Fig. 4와 같다. 조사기간 동안 W시 매립장의 기온은 최대 28.3°C, 최소 -3.4°C, 평균 15.4°C로 Fig. 5와 같으며, 습도는 최대 92.0%, 최소 21.1%, 평균 58.1%로 Fig. 6과 같다.

딥러닝 기반 추정 모형
W시 매립장에 설치된 128개의 포집공 중에서 2017년 1월~11월 중 88일간 조사된 23개의 포집공의 데이터를 이용하여 딥러닝 메탄가스 농도 추정 모형을 제시하였다. 딥러닝 기반 추정 모형 개발은 공통적으로 4단계로 구성되며, Fig. 7과 같이 입력변수 설정, 모델링, 학습 및 평가, 최적모형 선정 순으로 수행된다.

입력변수는 매립장에서 측정하고 있는 온도, 습도, 이산화탄소, 산소, 황화수소, 밸브개폐정도 6개이며 Table 1과 같다. 학습 전 변수들의 영향력을 일정하게 맞추기 위해서 0~1범위의 최대-최소 정규화를 실시하였다. 은닉층은 2개이며 각각 12개, 5개의 노드로 구성하였다. 또한 은닉층 활성화 함수로는 relu함수를 썼으며 출력층에는 sigmoid 함수를 사용하였다. 손실함수로는 MSE를 사용해서 MSE를 최소화 하는 방향으로 학습을 진행하였다. 학습 최적화를 위해서는 adam 함수를 사용하였다. 학습은 총 150회 반복 수행하였다. Table 2와 같이 딥러닝 분석에 이용된 총 자료는 2,024개로 추정모형 개발을 위한 학습자료에 80% (1,620개)가 사용되고, 나머지 20%(404개)는 추정 모형 검증을 위한 자료로 사용되었다.
Table 1. Input variable
| Item | Input variable |
| Link | CO2(1), O2(2), H2S(3), Valve gage level(4), Temperature(5), Humidity(6) |
Table 2. Training and Test Data (Unit : 1 data)
| Training data (80%) | Test data (20%) | Total |
| 1,620 | 404 | 2,024 |
예측의 정도를 평가하는 척도는 MAE(Mean Absolute Error), MAPE(Mean Absolute Percentage Error)를 예로 들 수 있다. 각 척도는 모델이 예측한 값과 실제 환경에서 관찰되는 값의 차이를 다룰 때 흔히 사용되는 척도들이다. MAE는 예측한 값과 실제 값과의 차이의 절대값 합을 산술평균한 값이며 식 (1)과 같다. MAPE는 실제값과의 차이를 실제값으로 나눈 절대값합을 산술평균한 값이다. 절대적 퍼센트로 나오기 때문에 서로 다른 단위로 학습된 모델들을 비교할 때 용이하며 식 (2)와 같다.
| $$\mathrm{MAE}=\sqrt{\frac1{\mathrm n}\sum_{\mathrm i=1}^{\mathrm n}\left|{\mathrm y}_{\mathrm i}-{\widehat{\mathrm y}}_{\mathrm i}\right|}$$ | (1) |
여기서, MAE = 평균절대오차
yi = 예측값
= 실제값
n = 횟수
| $$\mathrm{MAPE}=\sqrt{\frac{100\%}{\mathrm n}\sum_{\mathrm i=1}^{\mathrm n}\left|\frac{{\mathrm y}_{\mathrm i}-{\widehat{\mathrm y}}_{\mathrm i}}{{\mathrm y}_{\mathrm i}}\right|}$$ | (2) |
여기서, RMSE = 제곱근 평균오차
yi = 예측값
= 실제값
n = 횟수
딥러닝의 신경망 학습을 하기 위해서는 23개의 포집공별에서 수집한 2,024개의 데이터 중에서 훈련(Train)에 필요한 80%의 데이터를 이용하여 최적 모형을 개발하고, 나머지 20%의 데이터를 이용하여 시험(Test)을 수행하였다. 딥러닝 모델의 실제치와 예측치의 오차의 크기를 평가하였다. 오차 값은 0에 가까울수록 실제 값과 차이가 없다는 뜻이며 23개의 수집가스포집공별 훈련과 시험의 값은 Table 3과 같다.
Table 3. Error in estimation model by pipe line
포집공별 매립가스 변화 추정 실험결과 및 고찰
본 연구에서는 매립장에 설치된 23개의 포집공의 2017년 1월부터~11월까지 데이터 중에서 88일간 메탄가스, 황화수소, 산소, 이산화탄소, 날씨, 기온 등의 데이터를 수집하였다. 본 연구에서는 실제 수집된 데이터를 이용해서 딥러닝 기반의 포집공별 매립가스 변화 추정 모형을 제시하였고, 이 추정 모형을 이용하여 실증데이터를 입력하고 추정결과 데이터의 정확성을 검토하였다. 23개 포집공의 실제 최대 메탄농도는 59.1%이며 딥러닝 추정 최대 메탄농도는 57.0%로 2.1%의 차이가 있었으며, 실제 최저 메탄농도는 39.8%이며 딥러닝 추정 최저 메탄농도는 41.3%로 1.5%의 차이가 있었으며, 실제 평균 메탄농도는 49.6%이며 딥러닝 추정 평균 메탄농도는 49.7%로 0.1%가 차이가 있었다. 실제 값과 그에 대한 딥러닝 모델 추정 값 간의 오차율을 MAE와 MAPE를 통해 산출하였다. 산출된 모든 MAE와 MAPE값을 평균적으로 알아보기 위해 산술평균으로 계산하니 전체 평균 MAE는 2.24%였으며, 전체 평균 MAPE는 4.61%로 산출되었다. 평균 메탄농도는 오차율이 0.1%로 실제 측정한 메탄가스 농도와 유사하게 추정되었다. 포집공별 메탄가스 농도 및 그 추정 결과 전체 데이터셋은 Fig. 8과 같으며, 메탄가스 최대, 최소, 평균 농도 및 평균 MAE, MAPE는 Table 4와 같다.
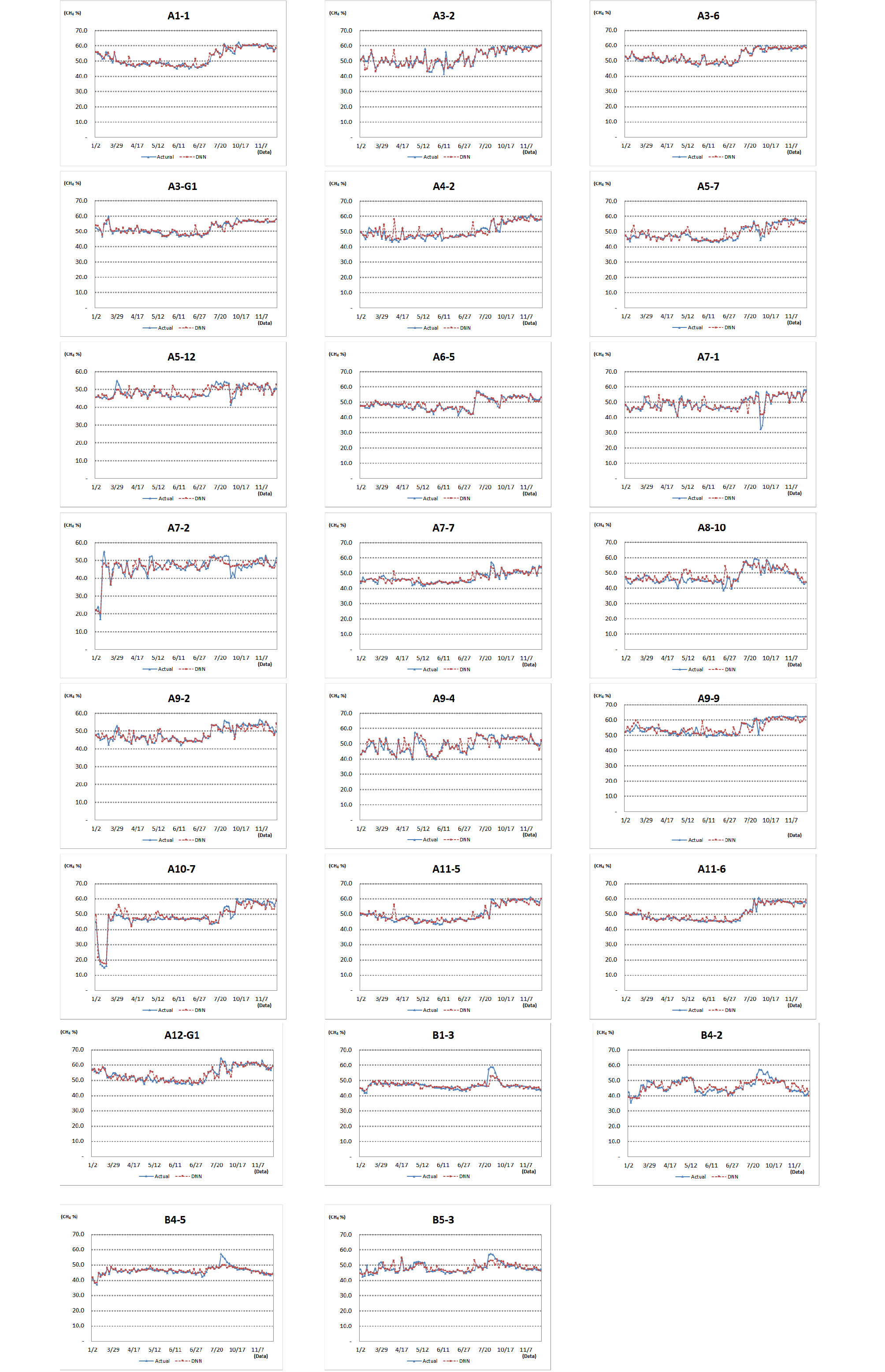
Table 4. Comparison of CH4 concentration between two models
결론
본 연구는 포집공별 매립가스 농도의 변화를 예측하고자 2017년 1월부터~11월 중 88일 데이터를 이용하여 실험하였다. 128개 포집공 중에서 가장 많이 사용한 23개의 포집공의 메탄가스 농도, 이산화탄소 농도, 황화수소 농도, 산소농도, 밸브 개방정도, 기온, 습도 자료를 이용하여 실제 값을 추정할 수 있는 딥러닝 모형을 제시하였다.
매립장에 설치된 포집공은 발전소를 운영하는 매우 중요한 항목으로, 실제로 측정된 자료를 이용하여 매립가스 농도가 어떻게 변화될지에 대한 추정이 매우 중요하다. 매립가스 발전소 운영 중에 포집공의 농도를 분석하지 못해 가동이 정지될 수 있고 포집공의 운영도 중단될 수 있다. 딥러닝 기법을 이용하여 포집공을 분석한 결과 실제 평균 메탄가스농도 49.6%, 딥러닝을 이용한 추정 평균 메탄가스농도 49.7%로 0.1% 차이로 실제 값과 매우 유사한 것으로 확인되었다.
본 연구 결과를 활용하면 향후 매립가스 포집공 관리에 큰 도움이 될 것으로 예상한다. 다양한 상황에 따른 매립가스 농도를 실시간으로 추정하며 위험상황을 미리 인지하고 이에 대응할 수 있다. 또한 실제 인력이 투입되었던 많은 부분들이 자동화 프로세스로 변경될 수 있어 업무의 효율성도 증가할 것이며, 현재 자료에 의한 추정모델의 한계를 극복하고 미래 예측 및 분석을 위해서는 LSTM(Long Short Term Memory)의 순환신경망(RNN) 모델 이용시 예측 능력을 더 향상 시킬 수 있을 것으로 예상된다.
