

서 론
2050 탄소중립 달성을 위해 이산화탄소 포집 및 지중저장(Carbon Capture and Storage, CCS)은 온실가스 배출 저감을 위한 필수 기술로 제시되고 있다(IEA, 2023). 한국은 2030년 국가 온실가스 감축 목표 중 CCS 분야의 감축 목표를 연 480 만톤으로 선정하였다(Park and Jin, 2023). 이에 따라 국내 CCS 저장소 확보 및 덮개암 안전성 검증의 필요성이 증가하고 있다(Ko, 2013).
그러나 덮개암 역할을 하는 셰일은 유기물 및 광물 조성에 따라 수리·역학·화학적 특성이 복합적으로 나타나며, 나노 규모 공극이 지배적인 저투과성 지층이므로 공극 네트워크의 연결성이 물성에 큰 영향을 미친다(Sondergeld et al., 2010; Loucks et al., 2012). 따라서 셰일 덮개암의 치밀성을 신뢰성 있게 평가하기 위해서는 나노 규모에서의 공극 구조와 연결성을 기반으로 공극률·투과도 등 핵심 물성을 분석할 필요가 있다(Sondergeld et al., 2010).
물성 분석 방법은 대표적으로 실험을 통한 방법과 수치 시뮬레이션을 통한 방법이 존재한다. 실험 기반 방법은 시뮬레이션 방법 대비 정확한 물성 평가가 가능하지만, 실험 이후 사용한 시료가 손상될 가능성이 있으며 다수의 시료 물성 평가는 계산 비용이 매우 많다는 한계를 가진다(McPhee, 2012; Nekouie et al., 2016; Jones et al., 2016). 이에 반해 시뮬레이션을 통한 물성평가 방법에는 디지털 암석을 이용한 방법이 많이 활용되고 있다. 디지털 암석은 암석 시료를 Micro-CT 또는 SEM과 같은 이미지 촬영 기법을 통하여 3D 이미지로 표현하는 기술로(Andrä et al., 2013) 실험에 비해 시간 비용 부담이 적고 비파괴적인 시료의 반복 분석이 가능하다는 장점이 존재한다(Balcewicz et al., 2021). 또한, 디지털 암석 기반 수치 시뮬레이션을 적용하면, Lattice Boltzmann Method(LBM)를 통하여 공극 유동을 해석해 단상 절대투과도를 산정할 수 있으며, 다상 LBM 모델을 이용하면 상대투과도와 같은 다상 유동 특성도 평가할 수 있다(Arns et al., 2004; Ramstad et al., 2012). 또한 Finite Element Method를 통하여 전기전도와 선형탄성 해석을 통해 전기전도도(electrical resistivity)와 탄성계수를 계산할 수 있다(Madonna et al., 2012; Sun and Wong, 2018).
그러나 디지털 암석 3D 데이터는 이미지 획득 이전 단계에서 실제 시료 확보에 크게 의존한다. 국내에서는 고갈된 동해-1 가스전을 활용한 CCS 실증 사업이 추친되고 있다(MOTIE, 2024). 다만 기존 탐사·개발 과정에서 축적된 자료는 주로 저류층 구간에 집중되어 있어 다수의 저류층 코어 및 관련 자료가 존재하는 반면, 덮개암 구간의 코어 확보가 어려워 로그나 커팅 자료에 의존하는 사례가 보고된다(BGS, 2000). 이로 인해 공극 규모 고해상도 3D 데이터 구축과 이를 활용한 물성 분석에 제약이 발생한다.
이러한 데이터 부족 문제를 완화하기 위해 생성형 AI 기반의 미세 공극 디지털 암석 데이터 증강 연구가 활발히 진행되고 있다(Mosser et al., 2017; Kench and Cooper, 2021; Zheng and Zhang, 2022; Lee and Yun, 2024). Mosser et al.(2017)은 고해상도 3D 데이터를 적대적 생성 신경망(generative adversarial networks, GAN)으로 학습하여 3D 데이터를 생성하였고, Zheng and Zhang(2022)은 조건부 GAN(conditional GAN)을 이용해 학습 데이터와 유사한 3D 데이터를 생성하는 동시에 공극률 등 사용자가 지정한 물성을 만족하도록 하는 증강 기법을 제시하였다. 그러나 이러한 3D 데이터 자체를 학습하는 방법은 학습 단계에서 충분한 양의 고해상도 3D 학습 데이터가 필요하다는 점에서, 실제 적용 시 데이터 확보 한계가 있다(Mosser et al., 2017).
데이터 확보 한계를 완화하기 위해, 3D 데이터 없이 2D 데이터를 학습하여 3D 데이터를 생성하는 대안이 제시되었다. Kench and Cooper(2021)는 단일 2D 데이터로부터 3D 데이터 생성 결과를 2D 단면 데이터로 절단하여 2D 판별 모델에 학습시키는 SliceGAN을 제안함으로써, 2D 데이터만으로 3D 데이터의 공극 구조를 구현하였다. Lee and Yun(2024)은 2D 확산 모델(diffusion model)을 기반으로 다중 평면 슬라이스 정보를 동시에 반영하여 2D 데이터로부터 3D 데이터를 생성하는 방법을 제시하였다. 다만 2D 데이터 기반 접근은 3D 데이터의 구조적 변동성과 방향성을 충분히 반영하기 어려워, SliceGAN은 등방성 가정에 기반하며 이방성 생성에서는 추가 학습 이미지 및 별도 판별기 구성이 요구되고(Kench and Cooper, 2021), 확산 기반 접근에서도 학습에 사용되는 2D 데이터의 다양성이 제한될 경우 3D 생성 오차가 증가할 수 있다(Lee and Yun, 2024).
본 연구의 목적은 CCS의 덮개암 셰일 물성 평가에 기초 자료로 활용될 다수의 3D 디지털 암석 데이터를 증강할 수 있는 방법을 제안한다. 이를 위해 Shaham et al.(2019)이 제안한 단일 이미지 적대적 생성 신경망 (Single Image GAN, SinGAN)을 적용한다. 구체적으로 원본 3D 데이터에서 공극 크기 분포(pore size distribution)와 공극 구형도 분포(pore sphericity distribution)의 수렴성을 기준으로 대표요소체적(Representative Elementary Volume, REV)을 설정하고, REV 기준을 만족하는 부분 체적 크기에서 SinGAN을 학습하여 다수의 셰일 3D 디지털 암석 데이터를 생성한다. 생성된 3D 데이터가 원본 공극 구조를 정량적으로 재현하는지 평가하기 위해 공극률, 공극–암석 비표면적(specific surface area), 오일러 지표(Euler characteristic) 등 공극 특성 및 연결성 기반 지표를 비교·분석하며, 추가적으로 저차원 분석(spectral embedding)을 통해 원본 데이터와 생성 데이터의 유사성을 종합적으로 검증한다. 이를 통해 CCS 덮개암의 치밀성 평가를 위한 셰일 디지털 암석 데이터 증강 및 활용 가능성을 제시한다.
본 론
공극 특성 분석
REV는 공극률, 투과도 등 주요한 암석 물성을 평가하는데 필요한 최소 샘플의 크기로 1) 통계적 정상성(Stationarity) 및 2) 관심 물성의 수렴한 정도를 통해 판단할 수 있다. 특히 디지털 암석의 크기가 클수록 물성 평가에 많은 계산시간이 소요되는 특성으로 인하여 가능한 최적의 REV로부터 물성을 파악하는 것이 중요하다. 이를 위한 공극 크기 분포와 공극 구형도 분포를 통하여 공극 특성 분석을 실행한다.
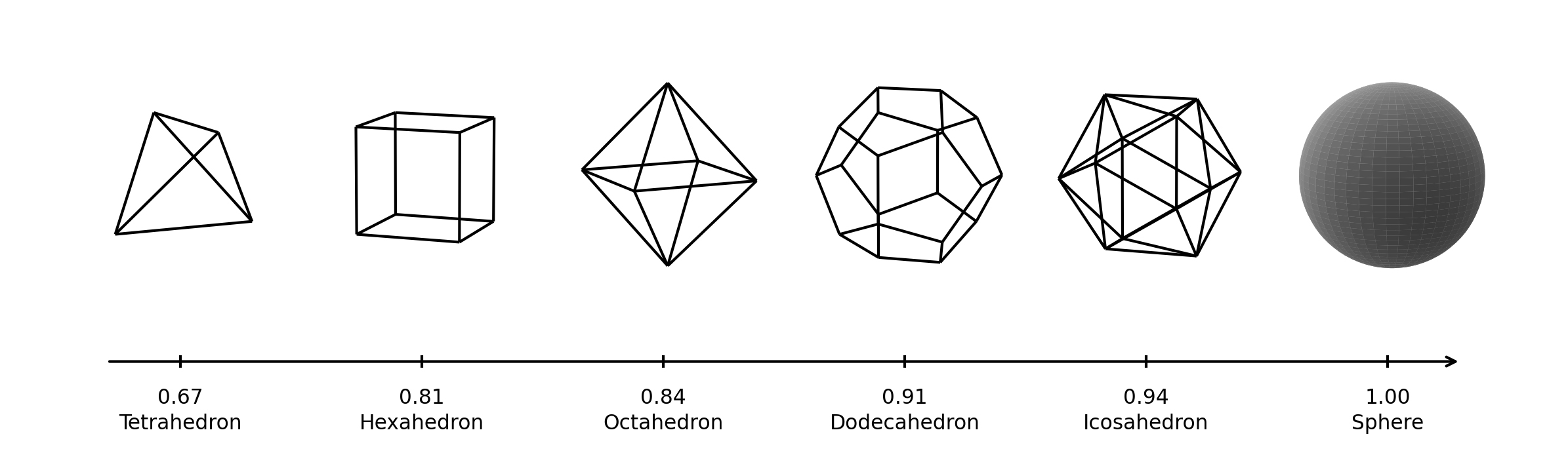
공극 특성 분석에 사용되는 대표적인 지표인 공극 크기 분포는 Fig. 1과 같이 공극 크기의 분포로 공극과 유체 유동의 영향을 평가한다(Song et al., 2019). 공극 크기 분포를 측정하기 위하여 공극 네트워크를 watershed segmentation 알고리듬 기반한 SNOW(Sub-Network of an Over-segmented Watershed) 방법을 통하여 추출한다(Gostick, 2017). 이후 추출된 네트워크로부터 공극 크기는 공극마다 가장 가까운 암석까지의 거리를 내접구의 지름으로 계산한다. 또한, 유체 유동에 영향을 주는 공극 구형도는 공극의 형상이 구에 얼마나 가까운지를 나타내는 척도로 Fig. 2와 같이 값이 1에 가까울수록 더 완전한 구형에 가까우며 공극 구형도는 식 (1)을 통하여 계산된다(Gabrieli et al., 2024).
여기서 는 공극 단면적, 는 공극 부피를 의미한다.
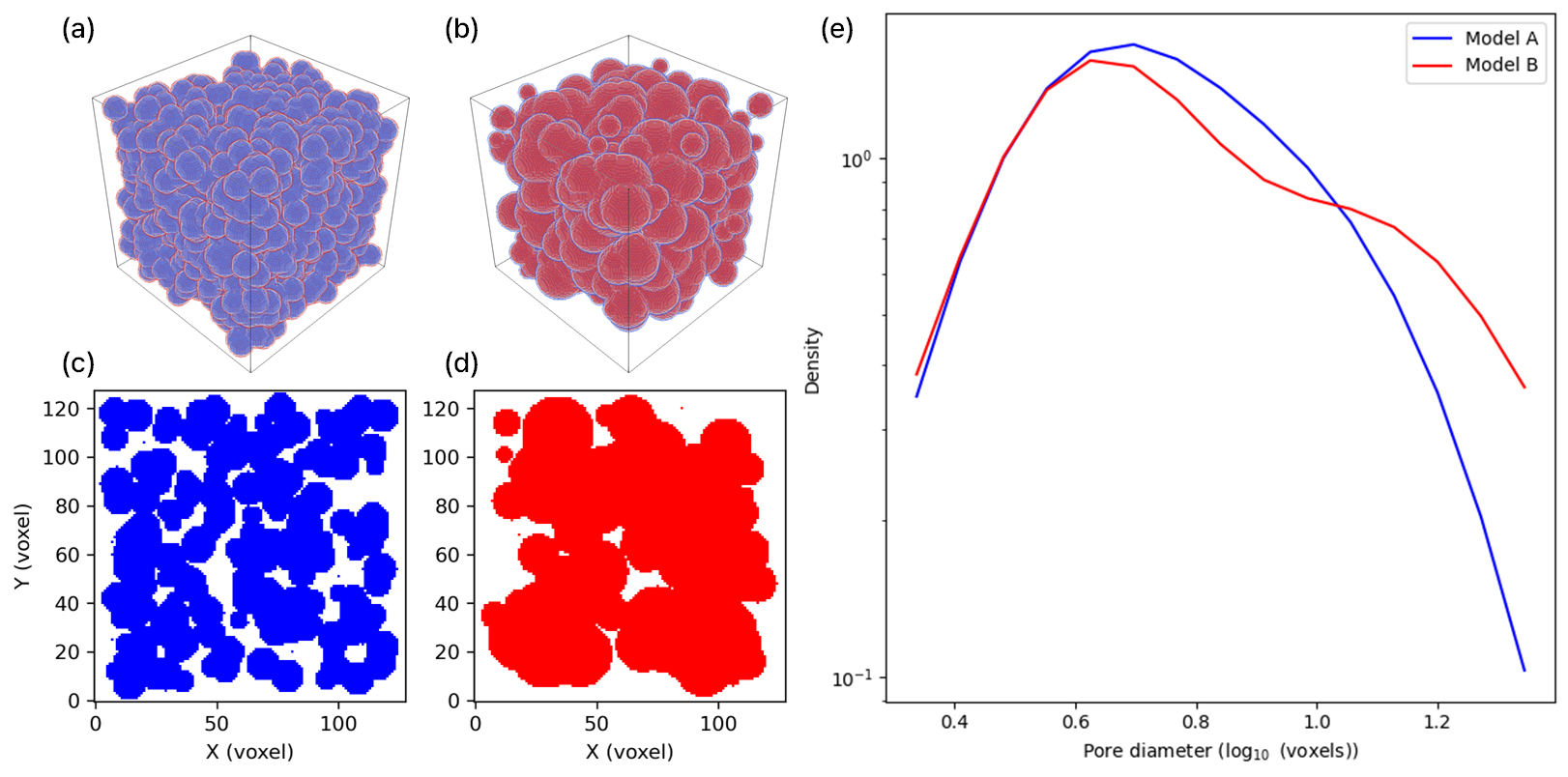
Fig. 1.
Pore size distribution comparison for two digital rock models. (a) Three-dimensional (3D) model of A with uniform-sized grains. (b) 3D model of B with random-sized grains. (c) Representative XY cross-section of Model A. (d) Representative XY cross-section of Model B. (e) Pore size distribution comparing Model A and Model B.
합성곱 신경망 및 적대적 생성 신경망
합성곱 신경망(Convolutional Neural Network, CNN)은 이미지의 공간적 구조 정보를 보존하면서 주요 특징을 추출하도록 설계된 심층신경망으로, 합성곱층(convolution layer)과 풀링층(pooling layer)으로 구성된다. 합성곱층은 필터(filter)를 입력 이미지에서 순차적으로 이동하면서 합성곱 연산을 수행하고, 이를 통해 특성 맵(feature map)을 생성한다(LeCun and Bengio, 1995; LeCun et al., 2002). 풀링층은 생성된 특성 맵을 다운샘플링하여 공간 해상도를 낮추고 크기를 축소함으로써, 모델의 복잡도를 완화한다. 이 과정을 통하여 과적합(overfitting)을 줄이는 동시에, 특성 맵의 크기를 조절하는 역할을 수행한다(LeCun and Bengio, 1995).
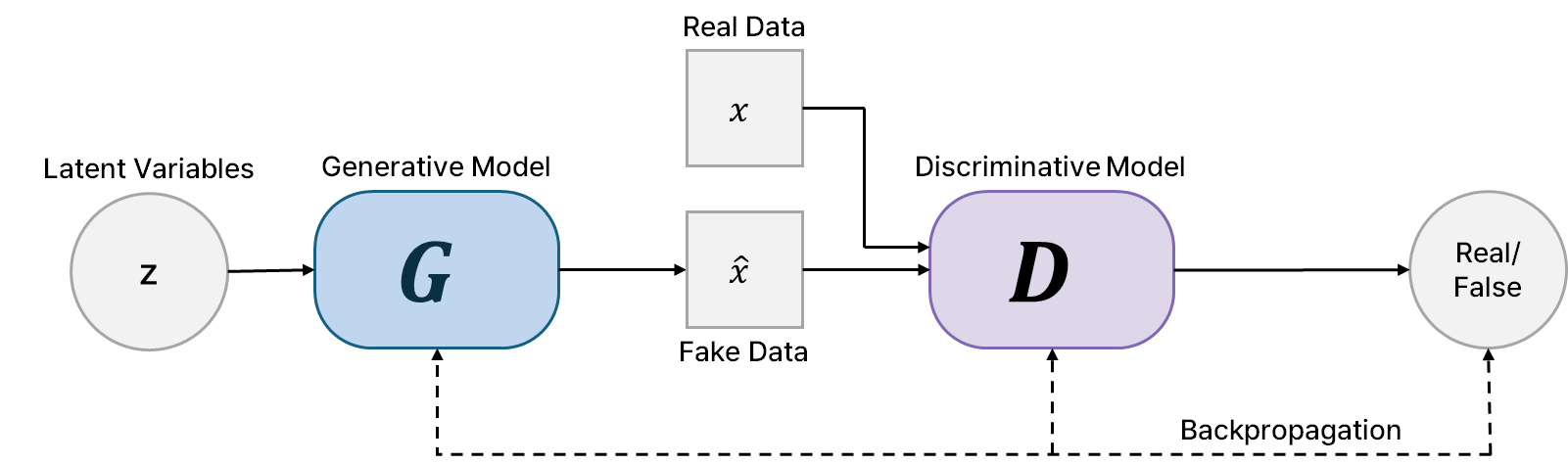
이러한 CNN 기반 구조는 이미지 데이터를 생성할 수 있는 생성형 AI에 활용된다(Creswell et al., 2018; Sengar et al., 2025). 대표적인 생성형 AI인 적대적 생성 신경망(GAN)은 생성 모델(generative model)과 판별 모델(discriminative model)로 구성되며 실제 데이터와 유사한 데이터를 생성하는 것을 목표로 한다(Fig. 3). 생성 모델은 실제 데이터(예: 디지털 암석)와 유사한 데이터를 생성하고 판별 모델은 입력 데이터가 실제 데이터인지 혹은 생성된 데이터인지 판별한다. GAN의 학습은 두 모델이 적대적 경쟁하는 과정으로 진행되며, 학습이 끝난 생성 모델은 잠재 변수(latent variables)를 바꿀 때마다 새로운 데이터를 생성한다. 그러나 GAN은 안정적인 학습을 위하여 방대한 양의 학습 데이터가 필요하다는 한계를 가지며, 데이터 확보가 제한적인 상황에서는 성능 저하 또는 학습 불안정 문제가 발생할 수 있다(Robb et al., 2020; Zhao et al., 2020).
SinGAN
위에서 언급한 많은 학습 데이터를 요구하는 GAN의 한계를 보완하기 위한 SinGAN은 단일 학습 데이터를 입력받아 다수의 데이터를 생성할 수 있는 생성형 AI이다(Shaham et al., 2019). SinGAN은 Fig. 4와 같이 계층적·다단계 구조(hie rarchical, multi-scaled)의 GAN으로 구성되며, 저해상도 스케일에서 고해상도 스케일 순서에 따라 여러 단계의 생성 모델–판별 모델 쌍을 순차적으로 학습한다.
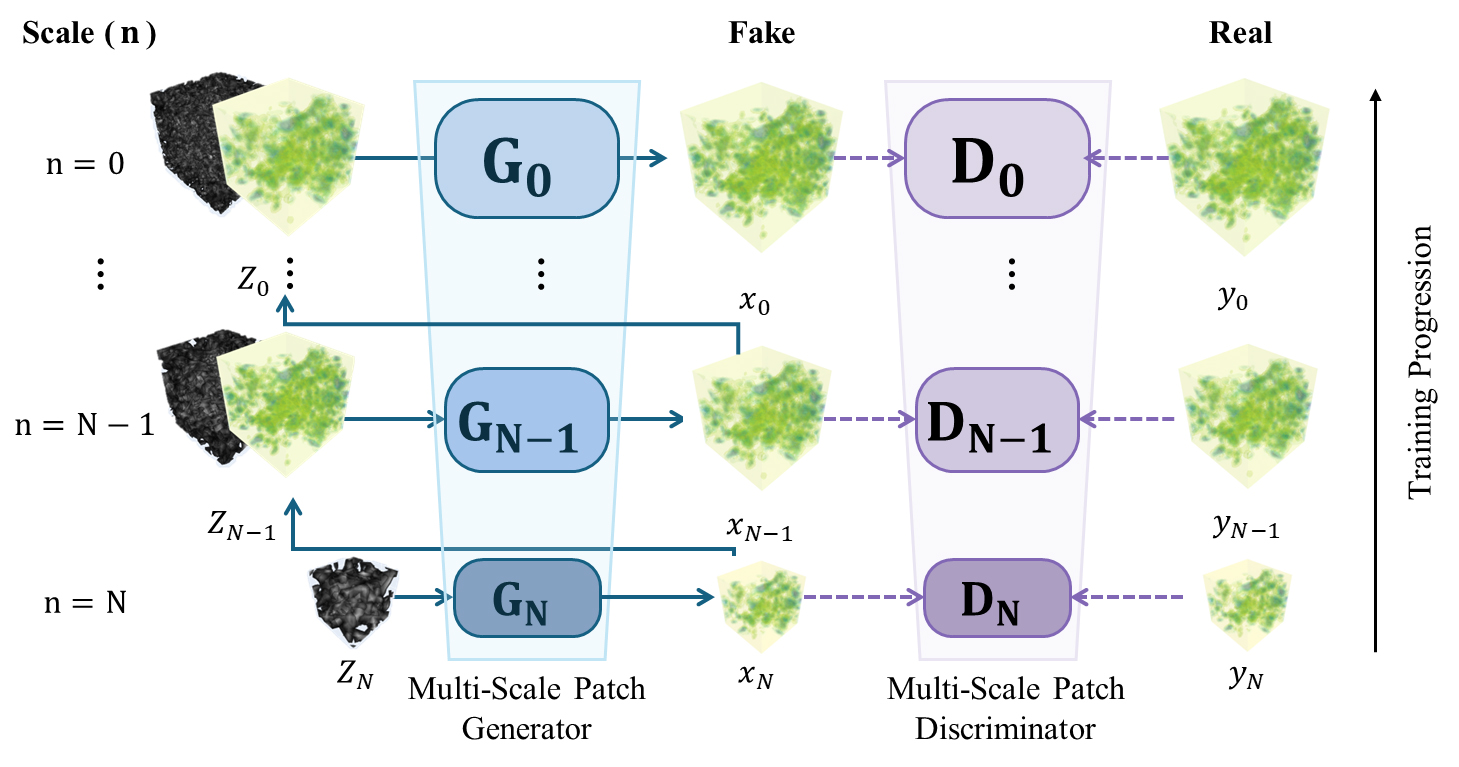
Fig. 4.
Workflow of the single-image generative adversarial network (SinGAN) (modified from Shaham et al., 2019).
구체적으로 SinGAN은 원본 데이터를 여러 단계로 다운샘플링한 뒤, 가장 낮은 해상도(N번째 스케일)에서 학습을 시작한다. 이후 각 스케일에서 생성된 결과는 다음 단계(N−1번째 스케일)의 입력으로 연속적으로 전달되며, 이 과정을 통해 전역적 구조부터 국소적 세부 구조까지 점진적으로 학습한다. 훈련 과정에서 사용되는 목적함수는 식 (2, 3, 4)와 같으며(Goodfellow et al., 2014; Isola et al., 2017; Shaham et al., 2019), 스케일별 학습을 반복함으로써 최종 단계에서는 원본과 동일한 해상도의 이미지를 생성할 수 있다. 또한 각 단계에서 생성 모델과 판별 모델이 입력 및 출력 데이터 크기는 Table 1과 같다.
여기서, 𝛼는 와 의 가중치를 조절하며, 𝜆는 기울기 페널티(gradient penalty) 항의 가중치이다(Gulrajani et al., 2017). 과 는 각각 스케일 n에서의 실제 샘플과 생성된 샘플에 해당하며 은 과 사이에서 보간된 샘플을 뜻하고 기울기 패널티에 사용된다. 은 스케일 n에서의 생성 모델, 은 스케일 n에서의 판별 모델이다. 과 은 각각 과 의 분포에 해당한다. 은 내부 통계적 패턴을 보존하는 반면에, 는 원본 이미지를 닮게 하도록 한다. 본 연구에서 α=10으로 설정하였다.
Table 1.
Model size for each scale in SinGAN training
본 연구에서 사용한 SinGAN의 생성 모델 및 판별 모델의 내부 구조는 Table 2와 같으며 생성 모델과 판별 모델 모두 5개의 블록으로 구성된다. 생성 모델은 잠재 변수와 이전 단계에서 생성된 결과(단, 스케일 7의 경우 zeros를 받음)를 받아 해당 단계의 생성 결과를 도출하고, 판별 모델은 같은 크기의 이미지를 입력받아 입력받은 이미지가 실제 데이터인지 아닌지를 판별한 결과인 [0, 1]의 값을 도출한다.
Table 2.
Architectures of the generator and discriminator constituting SinGAN
SinGAN으로부터 생성된 디지털 암석 샘플과 원본 디지털 암석의 공극 특성 및 기하학적 성질을 (1) 공극률, (2) 공극-암석 비표면적, (3) 오일러 지표, 그리고 (4) 비대각 복잡성을 통해서 검증한다. 또한, 학습 데이터와 생성 샘플간의 유사성을 비교하기 위하여 차원 축소 방법인 (5) Spectral Embedding을 활용한다.
공극률은 공극의 부피를 전체 부피로 나눈 값이다. 공극-암석 비표면적은 공극과 암석이 접촉하는 표면적을 전체 부피로 나눈 값이다. 비대각 복잡성은 연결된 공극의 조합이 얼마나 다양하게 나타나는지를 엔트로피로 정량화한 지표이다. 비대각 복잡성이 클수록 공극들이 다양한 방식으로 연결된 복잡한 네트워크 구조를 가진다(Liu et al., 2025). 오일러 지표는 공극 및 암석 구조의 위상학적 특성을 표현하는 값으로, 오일러 지표가 클수록 분리된 공극의 수가 많다는 것을 의미한다. Spectral Embedding은 차원 축소 방법으로 유사한 데이터일수록 가깝게 위치하고 데이터의 주변 관계를 보존하며 노이즈나 이상치에 둔감하다(Belkin and Niyogi, 2001). 평가 지표들의 계산을 위한 자세한 식들은 Appendix를 참고한다.
결과 및 분석
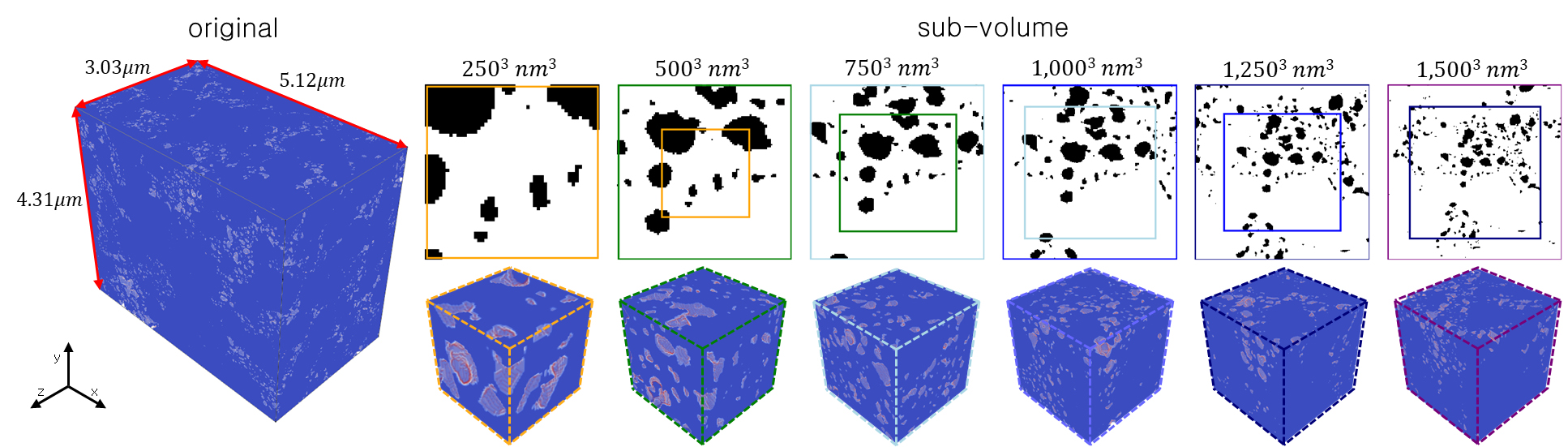
본 연구에서는 FIB-SEM을 통한 아르헨티나의 Vaca Muerta 지층의 셰일 디지털 암석 데이터를 이용한다(Andrew, 2018; Andrew, 2020). 원본 데이터의 물리적인 크기는 x, y, z 방향으로 각각 5.12×4.31×3.03 µm이다. 원본 데이터는 x, y, z 방향에서 동일한 격자 해상도 5 nm이며, 전체 격자 크기는 1024×861×606으로 각각 x, y, z 방향이다. 계산 비용을 줄이기 위하여 원본 데이터를 x, y, z 방향 모두에서 2배로 다운샘플링하여 격자 해상도를 10 nm로 조정하였고, 그 결과 전체 격자 크기는 512×431×303이다.
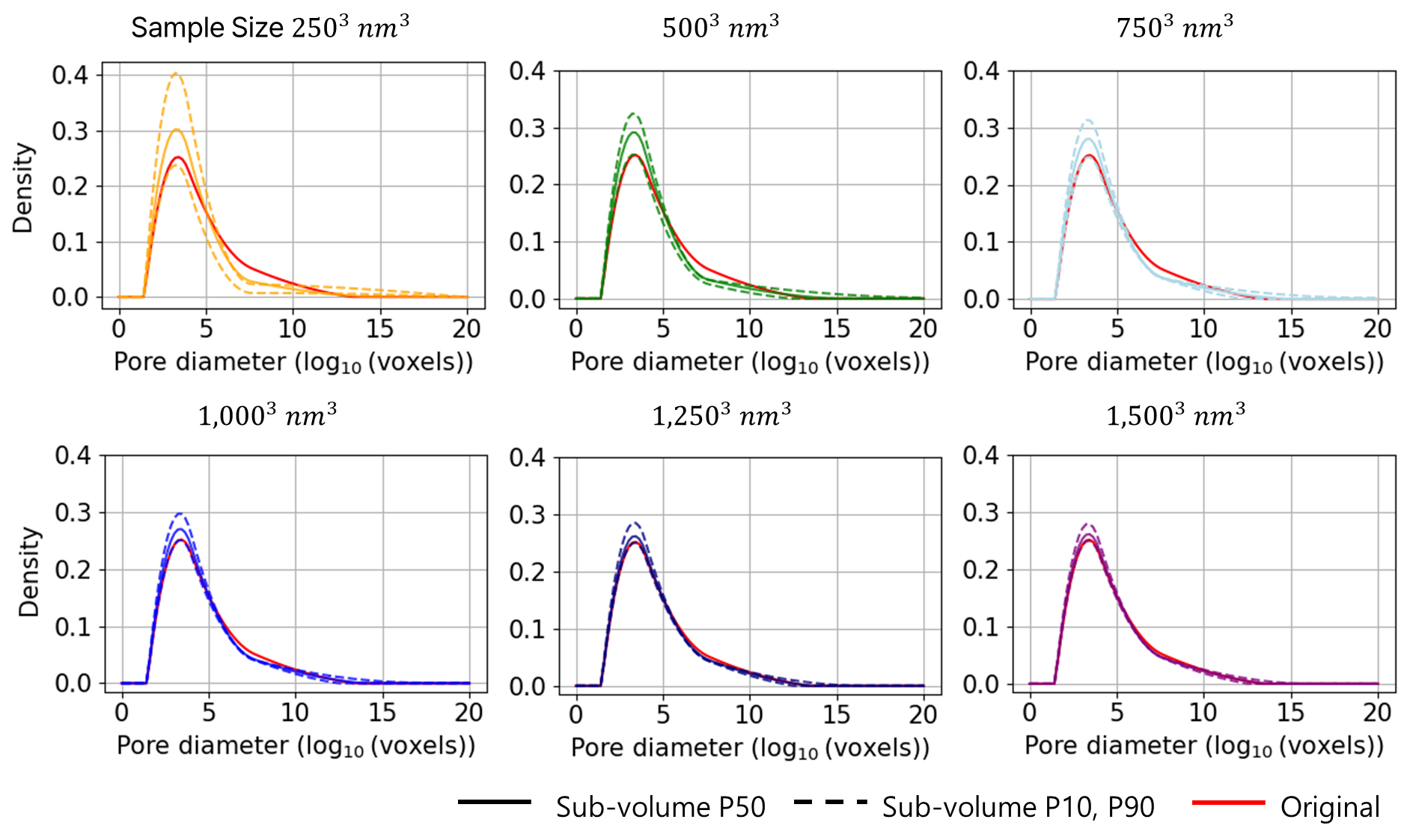
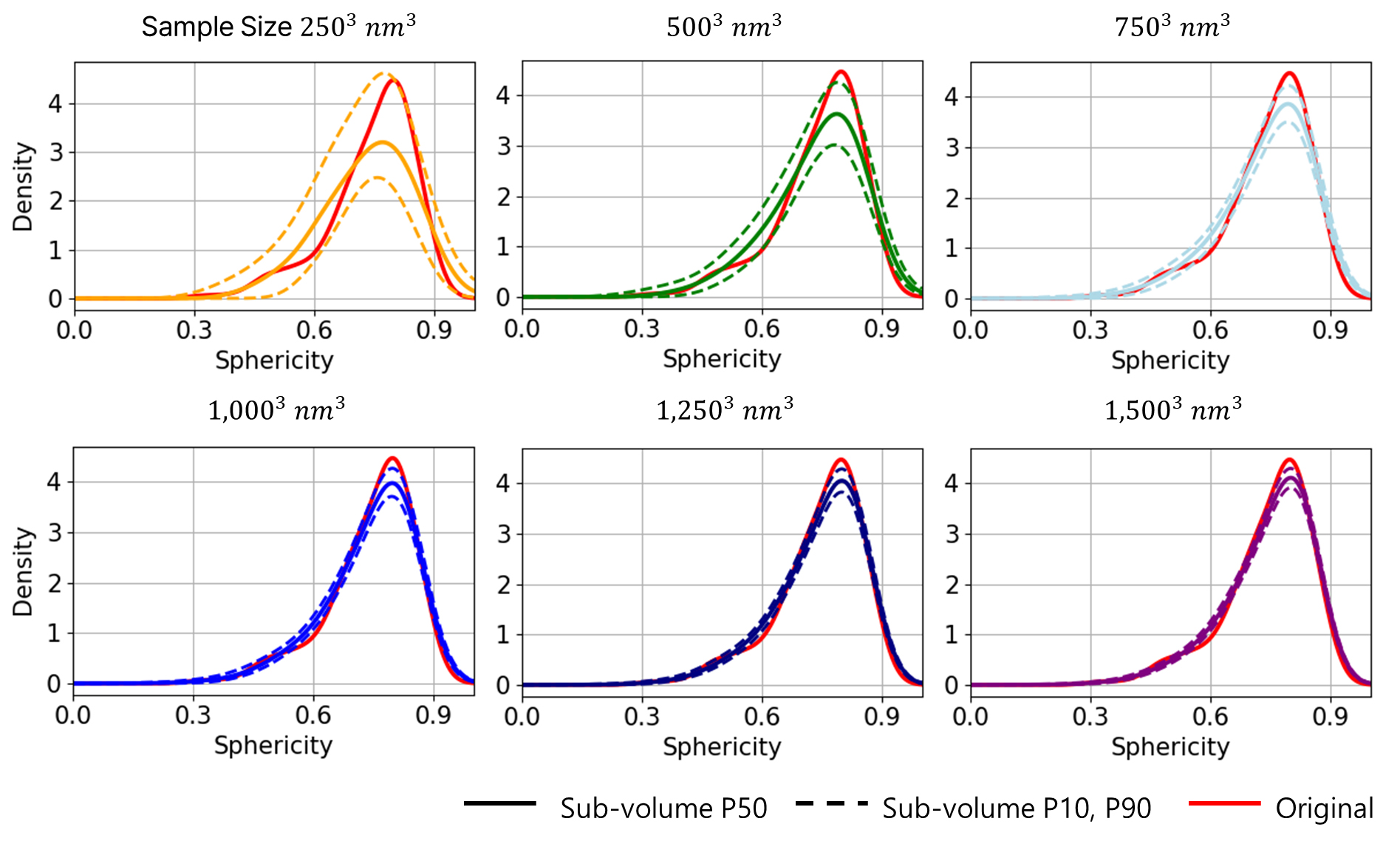
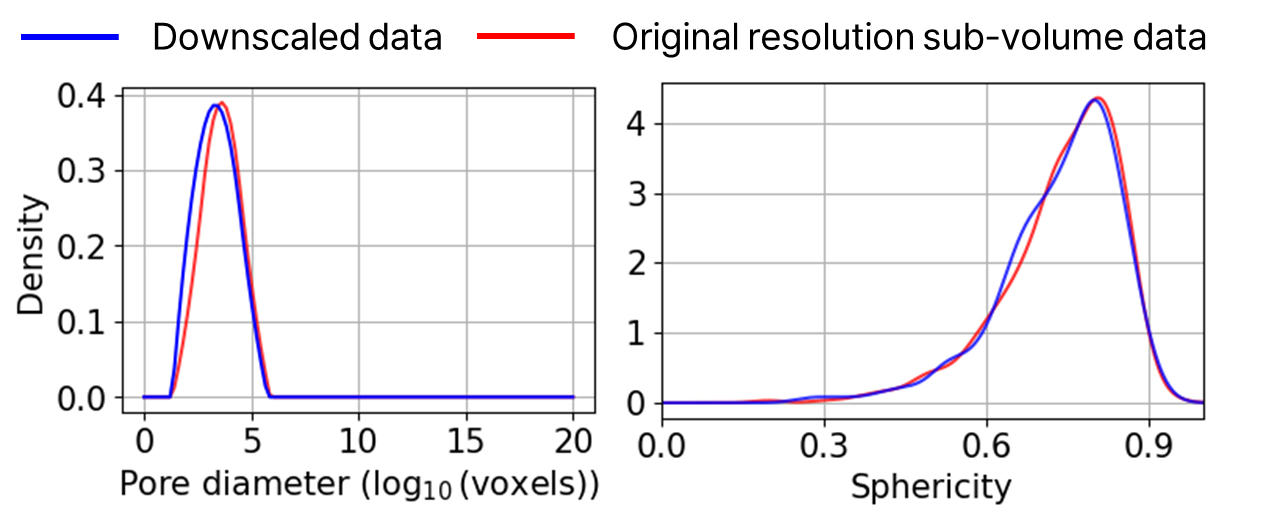
디지털 암석의 유의미한 수리·역학 물성 평가가 가능하며 계산 비용이 최소인 최적의 REV를 도출하기 위하여 원본 디지털 암석 데이터에서 크기별로 부분 체적을 생성하였으며, 그 결과는 Fig. 5로 제시하였다. 부분 체적의 크기 범위는 2503 nm3 부터 1,5003 nm3 까지다. 또한, 각 부분 체적에 대한 공극 크기 분포(Fig. 6) 및 공극 구형도 분포(Fig. 7)를 분석하여 원본 자료와 유사한 P50을 보이고, 나아가 적절한 P10/P90 불확실 폭을 갖는 크기를 찾고자 한다. 그 결과 공극 특성은 1,0003 nm3의 부분 체적부터 원본의 대표적인 공극 특성을 보존함을 확인하여, 이후 생성형 AI 학습 및 데이터 증강 기법은 1,0003 nm3의 부분 체적 자료에 대해 수행한다. 또한, 학습 이미지로 사용한 다운샘플링된 1,0003 nm3의 부분 체적과 원본 해상도의 1,0003 nm3의 부분 체적 자료에 대한 셰일의 공극 특성 분석 시 큰 오차가 발생하지 않음을 확인하였다(Fig. 8).
본 연구에서 Intel Xeon Silver 4214R CPU 및 NVIDIA RTX 3090 (24 GB) GPU의 사양인 워크스테이션을 사용하여 위에 제시한 SinGAN을 epoch 1,000번으로 학습하는데 총 95여 시간이 소요된다. 각 스케일별 학습 시간은 Table 3으로 요약한다. 3D 디지털 암석 데이터 1개 생성에 소요되는 시간은 2 s가 소요되며 100개 생성하는 시간은 총 약 3 min 30 s가 소요된다.
Table 3.
SinGAN training time per scale
| SinGAN training time per scale | |
| Scale # (0: finest, 7: coarsest) | Training Time |
| 0 | 91 h 26 min |
| 1 | 1 h 19 min |
| 2 | 45 min |
| 3 | 28 min |
| 4 | 17 min |
| 5 | 10 min |
| 6 | 6 min |
| 7 | 4 min |
학습이 끝난 SinGAN을 이용하여 새로운 디지털 암석 데이터를 생성한 결과는 Fig. 9와 같다. 학습에 이용한 학습 이미지와 전체적인 구조는 유사하나, 세부적 정보에 다양한 변화를 제공함으로써 다양한 공극 구조를 생성할 수 있다.
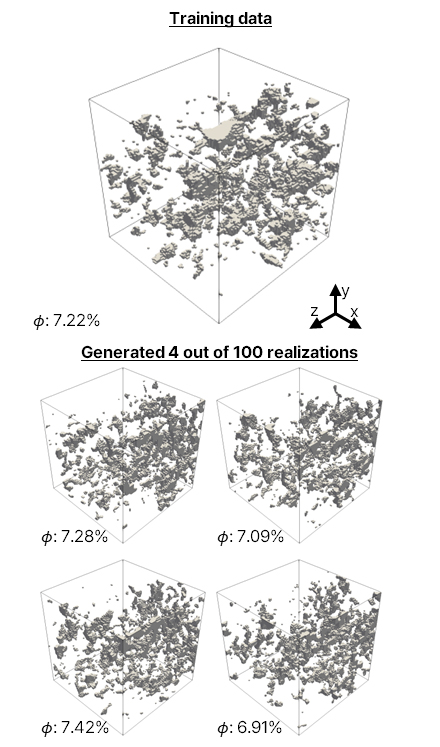
평가 지표를 통한 학습 데이터와 생성 데이터의 정량적 평가 결과는 Fig. 10으로 제시되며 빨간 선은 학습 데이터의 값, 파란 막대는 생성 데이터의 값이다. 모든 검증 지표에서 학습 데이터의 값이 100개의 생성 데이터 분포 내에 위치함을 통해 생성 데이터가 학습 데이터의 공극 및 기하학적 특징을 보존함을 검증한다.
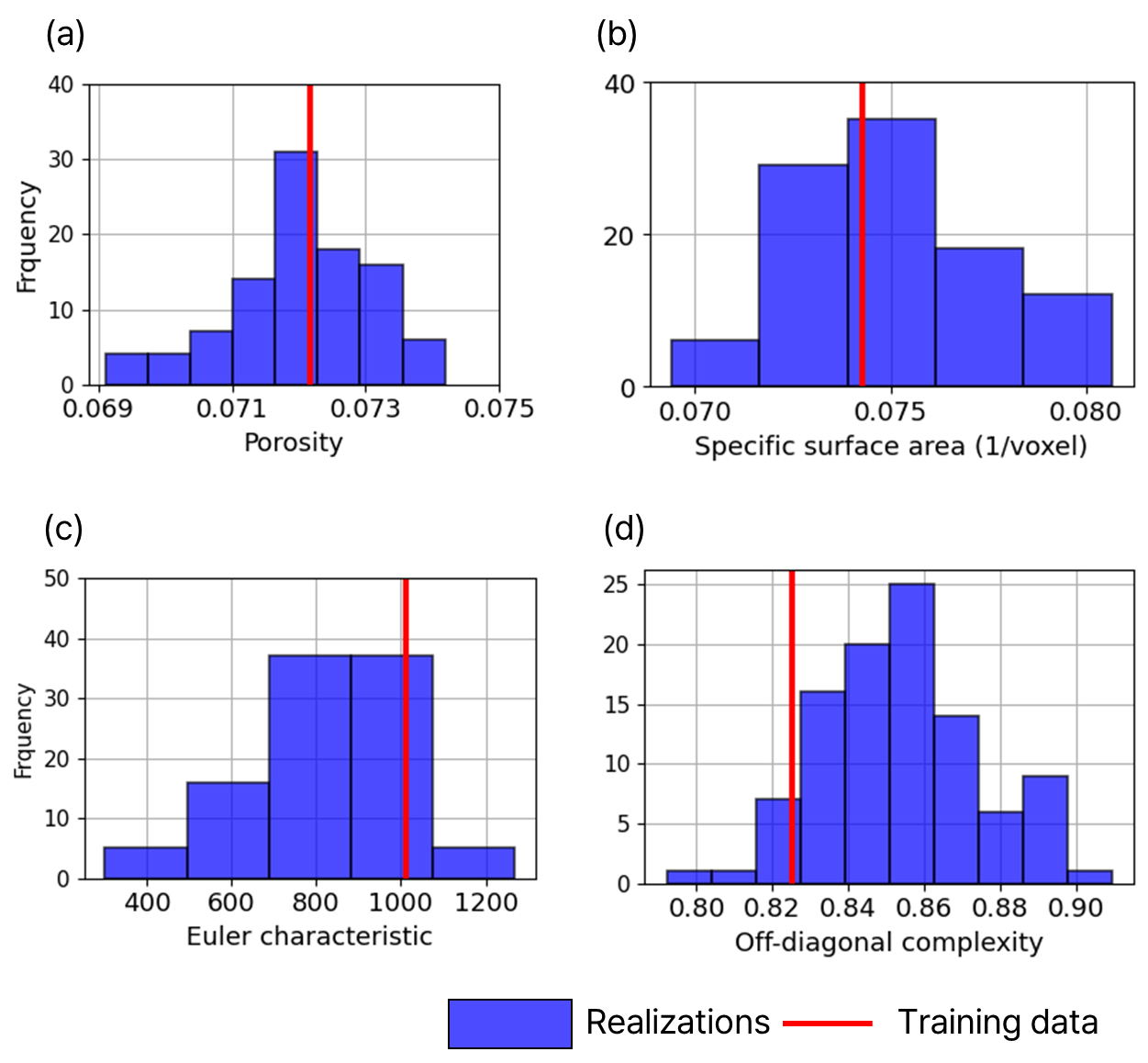
세부적으로, 공극률의 경우 생성 데이터의 값은 0.0691–0.0742의 범위를 보이고, 학습 데이터의 값은 0.0722으로 이는 생성 데이터가 학습 데이터 대비 ±5% 이내로 생성되어 학습 데이터와 유사함을 검증한다. 또한, 공극-암석 비표면적의 경우, 학습 데이터의 값은 0.0743 (1/격자)이고 생성 데이터의 값은 0.0694–0.0806 (1/격자)이므로 생성 데이터가 학습 데이터와 유사함을 검증한다. 오일러 지표는 학습 데이터의 값이 1013이고 생성 데이터의 값은 302–1269이므로 생성 데이터가 학습 데이터와 유사함을 검증한다. 또한, 공극들이 다양한 방식으로 연결된 복잡한 네트워크 구조를 표현하는 비대각 복잡성의 경우 학습 데이터의 값은 0.8253이고 생성 데이터의 값은 0.7921–0.9094이다. 이는 생성 데이터들이 하나의 구조로 수렴하는 현상이 발생하지 않고 구조적 다양성을 지니며 생성 데이터가 학습 데이터와 유사함을 검증한다.
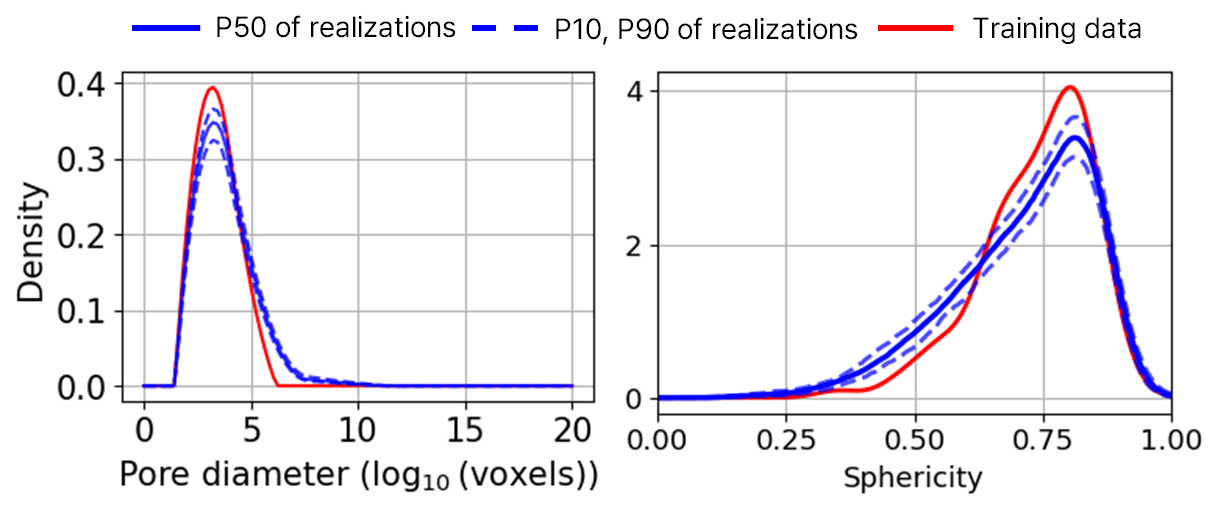
나아가, 최적의 REV 도출에 사용된 지표인 공극 크기 분포 및 공극 구형도 분포를 학습 데이터와 비교한다(Fig. 11). 이 결과를 통해서도 학습 데이터의 대표적 공극 특성을 보존하는 사실적이고 새로운 디지털 암석 데이터가 SinGAN을 통해 생성되었음을 확인할 수 있다.
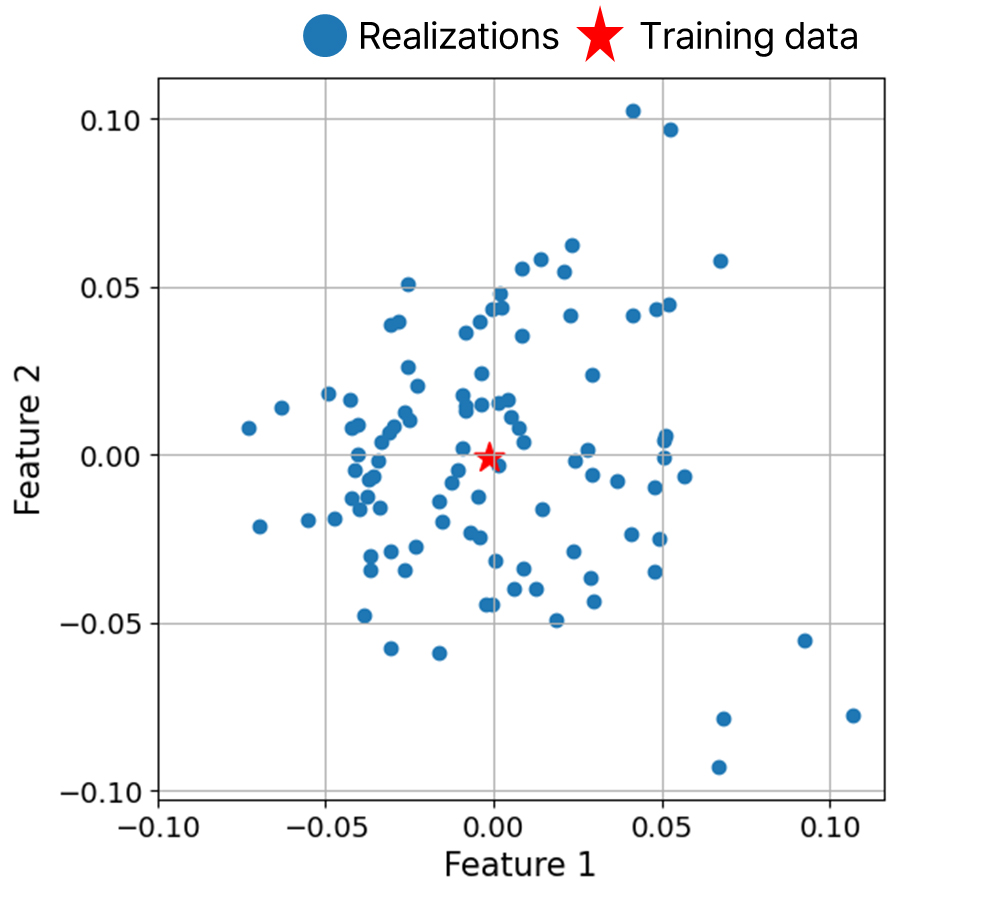
또한, 총 100개의 생성된 데이터에 Spectral Embedding으로 차원 축소를 수행한 결과는 Fig. 12와 같다. 이는 학습 데이터를 중심으로 생성 데이터들이 근처에 위치하며 한 점으로 수렴하지 않아 구조적으로 다양한 데이터가 학습 데이터와 유사하게 형성되었음을 나타낸다.
결 론
본 연구에서는 셰일 덮개암의 치밀성 분석을 위한 데이터 부족 문제를 해결하고자, 단일 3D 이미지만으로도 데이터 증강이 가능한 SinGAN 기반의 디지털 암석 생성 기법을 제안하고 그 타당성을 검증하였다. 연구의 주요 성과는 다음과 같다.
(1) REV 기반의 학습 데이터 최적화: 원본 3D 데이터에서 공극 크기 분포와 공극 구형도 분포의 수렴성을 분석하여, 원본의 대표성을 유지하면서도 계산 효율성을 극대화할 수 있는 최적의 1,0003 nm3 크기를 가지는 부분 체적을 도출하였다.
(2) 고해상도 3D 디지털 암석 데이터의 성공적 증강: 계층적·다단계 구조를 가진 SinGAN을 적용하여, 단일 학습 데이터로부터 원본의 미세구조적 특징을 유지하면서도 통계적 다양성을 갖춘 다수의 3D 디지털 암석 데이터를 생성하였다.
(3) 다각적 지표를 통한 생성 데이터의 신뢰성 검증: 생성된 데이터는 공극률, 비표면적, 오일러 지표, 비대각 복잡성 등 기하학적·연결성 지표 측면에서 원본과 일관된 경향을 보였다. 특히 Spectral Embedding 분석 결과, 생성된 샘플들이 학습 이미지의 특성 범위 내에서 사실적으로 분포함을 확인하였다.
(4) 학습은 데이터 수가 부족한 특정 1,0003 nm3의 부분 체적 자료에서 수행하므로 원본 데이터의 다른 영역에 존재할 수 있는 구조는 완벽히 반영되지 않을 수 있다는 한계가 존재한다.
결론적으로, 본 연구에서 제안한 생성형 AI 기반의 증강 기법은 고비용·저효율의 기존 데이터 확보 한계를 극복할 수 있는 대안임을 입증하였다. 또한, 국내 덮개암 셰일을 대상으로 디지털 암석 데이터를 확보한다면, 향후 국내 CCS 저장소의 안전성 평가를 진행할 수 있다. 특히, 유체 유동 시뮬레이션 및 물성 분석을 위한 스케일업 기초 자료로 유용하게 활용될 것으로 기대된다.

