

서 론
선행 연구
거시경제 관련 선행 연구
주식시장 관련 선행 연구
분석 방법론
구글 트렌드와 검색어 선정
k-평균 알고리즘
분석 결과
k-평균 군집분석 결과
기댓값 최대화 군집분석 결과
인터넷 검색 자료의 활용
포트폴리오 전략
수정 포트폴리오 전략 적용 결과
결 론
서 론
최근 인터넷의 발달과 이용자 수의 증가는 많은 학자들에게 인터넷 검색 자료를 활용한 각종 사회 현상의 분석 기회를 제공하고 있다. 세계에서 가장 대표적인 검색 엔진인 구글(Google)은 특정 용어에 대한 검색 빈도 자료를 2005년 8월부터 제공하기 시작했고 2012년부터는 지역별, 일정 기간별 검색 빈도를 제공하는 서비스인 구글 트렌드(Google Trends)를 시행하고 있다. 인터넷 검색 자료는 실제 경제 활동 주체들의 경제 활동에 대한 정보를 실시간으로 제공해 준다는 장점을 갖고 있다. 이러한 장점으로 인하여 경제학, 경영학, 의학 등 다양한 학문 분야에서 인터넷 검색 자료를 활용한 연구가 진행 중이며 특히, 거시경제와 주식시장에 관련된 연구가 활발히 진행 중이다. 최근에는 인터넷 검색 자료를 에너지 상품 시장에 적용한 연구도 진행되고 있다. Ji와 Guo (2015)는 원유 가격의 변동성을 인터넷 검색 자료를 활용해 분석을 시도하였다. 그러나 인터넷 검색 자료를 에너지 상품 시장에 적용한 연구는 비교적 최근에 진행되었기 때문에 타 분야와 비교하면 미미한 실정이다.
에너지 상품 시장은 최근 각 국가들의 통화완화 정책과 저금리로 인하여 상대적으로 고수익을 얻을 수 있는 대안투자 상품으로 각광 받고 있다. 또한, 에너지 상품 시장의 성장과 거래규모 증가로 인하여 헤지(hedge)거래자, 기관투자자 뿐만 아니라 개인투자자의 참여가 확대되고 있는 추세이다. 이러한 에너지 상품 시장에서의 거래 규모와 거래 참가자들의 증가로 인해 에너지 상품 시장과 관련 있는 인터넷 검색 자료의 정보량은 점차 축적되어 에너지 상품 시장 분석에 인터넷 검색 자료의 활용이 가능 할 것으로 판단된다.
이에 본 연구는 k-평균(k-means) 군집분석과 기댓값 최대화(Expectation-Maximization, EM) 군집분석을 통하여 인터넷 검색 자료를 활용한 에너지 상품 시장의 변동성을 분석하고 인터넷 검색 자료의 위험관리 지표로의 활용 가능성을 보이고자 한다. 또한, 분석 결과를 바탕으로 인터넷 검색 자료 기반의 투자 포트폴리오를 구성하여 인터넷 자료를 활용한 투자전략에 대해서 제안하고자 한다.
논문의 구성은 다음과 같다. 2장에서는 인터넷 검색 자료를 활용한 선행 연구들을 거시경제 관련 선행 연구와 주식시장 관련 부분으로 나누어 각 선행 연구들에 대해 살펴보았다. 3장에서는 검색어의 선정 방법과 군집분석 방법론을 사용하여 변동성 분석 부분에서의 인터넷 검색 자료 활용 가능성을 검토하였다. 4장에서는 3장의 검토 내용을 바탕으로 인터넷 검색 자료 기반의 투자 포트폴리오를 구성하여 실제 인터넷 검색 자료 적용에 따른 포트폴리오 수익률과 변동성의 변화에 대해 실증 연구를 실시하였다. 마지막으로 5장에서는 본 연구의 결론과 향후 연구 방향에 대해 간략히 정리하였다.
선행 연구
인터넷 검색 자료를 활용한 연구는 2000년대 인터넷 사용자의 증가에 따라 관심이 증가하기 시작했다. 이후, 인터넷 사용이 대중화되어 자료가 충분히 축적되고 이를 분석하기 위한 대용량 자료처리가 가능하게 되자 인터넷 검색 자료를 활용하여 사회 현상을 분석하는 연구가 본격적으로 진행 되었다. 그 중에서도 인터넷 검색 자료를 거시경제와 주식시장 분야에 적용한 연구가 활발히 진행되고 있다.
거시경제 분야의 선행 연구와 주식시장 분야의 선행 연구의 가장 큰 차이점은 분석하고자 하는 대상에 대한 시간단위라고 할 수 있다. 거시경제 분야의 선행 연구의 경우는 주로 주간, 월간 단위로 분석을 하였으며 주식시장 분야의 선행 연구는 일간, 시간단위로 분석을 시행 해왔다. 이에 본 장에서는 적절한 방법과 시간단위를 선정하여 에너지 상품 시장에서의 인터넷 검색 자료 활용 가능성을 보다 효율적으로 분석하기 위해 거시경제 관련 연구와 주식시장 관련 연구로 나누어서 선행 연구를 살펴보았다.
거시경제 관련 선행 연구
인터넷 검색 자료를 활용한 거시경제 관련 선행 연구들은 주로 소비자 신뢰 지수, 실업률, 주택시장, 노동시장 그리고 인플레이션과 같은 거시경제 지표와 소비자의 소비 활동의 예측 위주로 연구가 진행되었다. Ettredge 등(2005)은 인터넷 검색 자료와 미국 실업률과의 관계를 분석하였다. 고용과 관련 있는 검색어를 설명 변수로 설정하여 월간 실업률과 검색 자료의 관계를 분석 하였다. 인터넷 검색 자료가 특정 종속변수를 설명 할 수 있는 설명변수로 활용이 가능함을 보여주었다.
Goel 등(2010)은 실제 소비자가 경제 활동을 하기 이전에 인터넷을 통해 정보를 수집한다는 점에 착안하여 인터넷 검색 자료를 기반으로 실제 소비자들의 행동에 대한 예측을 하였다. 인터넷 검색 자료와 실제 소비경제와 상관관계가 있으며 인터넷 검색 자료가 실제 경제활동에 영향을 미친다는 것을 보여주었다. Vosen과 Schmidt (2011)는 구글 트렌드를 기반으로 개인 소비에 관한 지표를 개발 하였다. 개인 소비와 관련 있는 검색어를 분류하여 인터넷 검색 자료를 기반으로 지표를 구성하였다. 그리고 실제 발표되는 소비자 신뢰 지수와 인터넷 검색 자료 기반의 지표와 비교를 통해 인터넷 검색 자료를 기반으로 개발한 지표의 예측력을 검증하였다.
Mclaren와 Shanbhogue (2011)는 인터넷 검색 자료가 경제적 의사결정을 위한 잠재적으로 유용성이 있는 자료라고 주장하였으며 인터넷 검색 자료를 활용하여 영국의 노동시장과 주택시장에 대한 분석을 실시하였다. Choi와 Varian (2012)는 구글 트렌드를 활용한 시계열 모형을 통해 소비자 지수, 실업률과 같은 거시 경제 지표 분석을 수행하였다. 또한, 차량 구매, 여행 목적지 계획과 같은 소비 활동에 관한 예측도 실시하여 거시경제 및 소비 활동의 분석에 구글 트렌드가 활용 가능하다는 것을 보여주었다. Carrière-Swallow와 Labbé (2013)은 구글 트렌드를 기반으로 시계열 모형을 활용하여 신흥 국가(emerging country)인 칠레의 자동차 판매에 관한 소비 거동을 예측하였다. 이 논문은 인터넷 검색 자료를 활용하여 특정 경제 현상을 분석하기 위해서는 분석 주체와 관계가 깊고 정확한 자료를 수집해야함을 강조하고 있다.
주식시장 관련 선행 연구
인터넷 검색 자료를 활용한 주식시장 관련 선행 연구들은 주로 검색 빈도를 통한 주식가격과 거래량 예측, 변동성 분석, 투자전략 수립 위주로 연구가 진행되었다. Bollen 등 (2011)은 SNS의 한 종류인 트위터(Twitter)를 활용한 주식시장 예측에 관한 연구를 실시하였다. 트위터에 기재된 감성(mood)과 관련된 용어의 빈도가 다우지수와 관계가 있음을 보이고 해당 검색어를 활용하면 다우지수 예측의 정확성을 좀 더 높일 수 있음을 주장하였다.
Bordino 등(2012)은 포털 엔진인 YAHOO!의 검색 빈도와 나스닥 시장에 상장된 기업들을 통해 인터넷 검색 활동과 개별 주식의 거래량에 관한 상관관계에 관하여 분석을 시도하였다. 연구 결과는 당일 검색빈도와 익일 주식 거래량은 양의 상관관계가 있음을 보여주었다. 이는 인터넷 검색 빈도를 기반으로 시장의 거래량과 변동성 분석을 통해 인터넷 검색 자료가 변동성 분석에 적용 가능함을 시사한다. Moat 등(2013)은 인터넷 백과사전인 위키피디아(Wikipedia)에서의 특정 기업이나 주식시장에 관한 내용의 변화와 검색 빈도를 기반으로 주식시장 움직임에 대해서 분석을 하였다. 실제특정기업의 주가가 하락하기 이전에 위키피디아에서 해당 기업에 대한 검색 빈도와 내용의 변화가 빈번하게 일어났음을 보여주었다. 인터넷 검색 자료 정보를 통해서 실제 세계의 행동을 추측 할 수 있으며 투자의사 결정 시, 인터넷 검색 자료가 도움을 줄 수 있음을 강조하였다.
Preis 등(2013)은 주식시장과 관련이 있는 98개의 단어를 선별하여 해당 단어들과 주식시장간의 상관관계에 대해서 분석을 하였다. 그리고 선별된 단어들의 2004년부터 2011년까지의 검색 빈도를 기초로 한 투자 전략을 수립하였다. 벤치마크로 설정한 다우지수를 초과하는 수익률을 보여준 검색어도 존재하지만 하회하는 수익률을 보여주는 검색어도 존재하였다. 그러나 평균적으로 인터넷 검색 자료를 기초로 한 투자 전략이 시장 평균 수익률을 초과한다는 것을 보여주었다.
Kristoufek (2013)는 인터넷 검색 빈도를 기준으로 하는 포트폴리오를 구성하여 벤치마크인 다우지수와 비교를 하였다. 다우시장에 상장된 30개 기업을 대상으로 포트폴리오를 구성하였으며 포트폴리오 구성 기준은 다음과 같다. 특정 기업에 대한 검색 빈도가 높을수록 위험도가 높다는 가정을 설정하고, 해당 기업의 인기도와 검색 빈도를 기준으로 위험(risk)정도를 분류하여 위험정도에 따라 각 기업에 다른 가중치를 부여하였다. 위험정도가 부과된 기업들을 5개 그룹으로 분류하여 검색빈도에 따라 가중화된 포트폴리오를 구성하였다. 구성한 포트폴리오를 통해 인터넷 검색 자료가 투자 활동에서 위험관리 방법에 적용 가능함을 보여주었다.
Ranco 등(2015)는 특정 뉴스에 대해서 투자자들의 검색빈도를 오피니언 마이닝(opinion mining)의 일종인 감정분석(sentiment analysis)과 결합하여 당일 가격 변화에 대한 단기 예측을 시도하였다. 이를 위해 예측을 위한 기본 모형인 sentiment time series를 설정하고 인터넷 검색 빈도를 가중치로 활용하기 위하여 click time series로 모형화 하였다. 그리고 두 모형을 결합하여 가중치가 부여된 weighted sentiment time series를 정의 하였다. 이 논문은 인터넷 검색 빈도 자료를 가중치로 활용하여 가격 예측을 시도했다는 것이 특징이다.
선행 연구를 살펴보면 인터넷 검색 자료를 활용한 대부분 연구는 거시경제와 금융시장 부분에서 진행되었으며 상대적으로 에너지 상품 시장에 활용한 연구는 미미하다는 것을 알 수 있다. 에너지 상품 시장은 가격과 거래량을 가지며 금융시장과 유사한 시장 구조를 가진다. 특히 원유 선물 시장은 풍부한 거래량과 가격변동 위험의 헤지(hedge)수단과 차익 추구 등의 목적으로 거래가 이루어지며 금융시장의 선물 상품과 기초자산에 차이만 있을 뿐 유사한 구조를 갖고 있다. 즉, 주식시장과 유사한 시장 구조를 가지며 금융 상품의 일종인 원유 선물 시장에서도 인터넷 검색 자료의 활용이 충분히 가능하다고 볼 수 있다.
추가적으로 인터넷 검색 자료를 활용하여 특정 대상을 분석 할 경우에는 분석 시간단위와 기간과 검색어 선정 부분이 고려해야하는 주요한 요소임을 알 수 있다. 이에 본 연구는 효과적으로 에너지 상품 시장을 분석하기 위한 적절한 검색어 선정과 분석 시간단위와 기간을 선정하고 에너지 상품 시장에서도 인터넷 검색 자료가 활용 가능하다는 것을 보여주고자 한다.
분석 방법론
앞서 살펴본 선행연구는 인터넷 검색 자료를 주로 시계열 모형을 통한 거시경제 지표, 주식가격과 거래량의 예측에 활용하였다. 본 연구는 군집분석을 통해 대표적인 에너지 상품인 WTI 원유 선물과 인터넷 검색 자료의 일반적인 관계 특성 파악을 시도하였다. 이는 군집분석이 다변량 자료를 분류하고 집단화하여 분석하는 방법론으로 집단화된 자료의 특성과 패턴(pattern) 파악에 용이하고 집단화를 통해 주어진 자료들 사이의 의미 있는 관계를 파악 할 수 있는 특징을 갖고 있기 때문이다(Pang-Ning et al., 2014).
구글 트렌드와 검색어 선정
구글 트렌드는 특정 검색어의 시간에 따른 검색 빈도의 수를 제공해주는 서비스이다. 제공되는 특정 검색어의 검색 빈도는 일정기간동안 이루어진 특정 검색어에 대한 총 검색 횟수를 동일 기간 동안 검색된 모든 검색어의 검색 횟수 합으로 나누어 그 값을 측정한다. 이를 식으로 표현하면 아래 식 (1)과 같다.
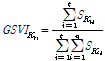 (1)
(1)
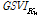 : 시점 t에서의 검색어
: 시점 t에서의 검색어 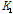 의 검색 빈도 지수 (google search volume index)
의 검색 빈도 지수 (google search volume index)
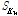 : 시점 t에서의 검색어
: 시점 t에서의 검색어 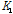 에 대한 검색 수
에 대한 검색 수
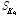 : 시점 t에서의 검색어
: 시점 t에서의 검색어 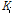 에 대한 검색 수
에 대한 검색 수
다음으로 식 (1)에서 계산된 일정 기간 동안의 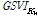 값들 중에서 가장 높은
값들 중에서 가장 높은 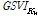 값을 100으로 표준화한다. 표준화 된 값인 100을 기준으로 특정 검색어의 각 시간별 검색빈도 정도를 계산한다. 따라서 구글 트렌드의 검색 빈도 값은 0-100의 범위 값을 갖게 된다. 아래 Fig. 1은 실제 구글 트렌드를 활용 했을 경우 얻게 되는 자료의 형태를 보여준다.
값을 100으로 표준화한다. 표준화 된 값인 100을 기준으로 특정 검색어의 각 시간별 검색빈도 정도를 계산한다. 따라서 구글 트렌드의 검색 빈도 값은 0-100의 범위 값을 갖게 된다. 아래 Fig. 1은 실제 구글 트렌드를 활용 했을 경우 얻게 되는 자료의 형태를 보여준다.
구글 트렌드를 활용하여 특정 대상에 대한 분석을 실시 할 경우에는 분석 대상과 관계있는 검색어 선정에 관한 문제를 우선적으로 고려해야한다(Carrière-Swallow and Labbé, 2013). 본 연구에서는 WTI 원유 선물 가격의 거동을 분석 대상으로 선정 하였으며 검색어는 분석 대상인 WTI 원유 선물 가격과 직간접적으로 연관 있다고 판단되는 “oil price”, “oil future price”, “oil production”, “oil demand”, “oil supply”를 검색어로 선정하였다. 그 중에서 WTI 원유 선물 가격과 상대적으로 높은 상관계수를 보인 검색어 “oil price”, “oil future price1)”를 중심으로 분석을 실시하였다.
k-평균 알고리즘
k-평균 군집분석은 주어진 자료의 특성을 토대로 유사한 속성을 지닌 자료들을 집단화하여 분석하는 다변량 통계기법에 속한다. 군집분석 방법론은 측정한 자료의 집단화를 통해 내부구조에 대한 사전정보 없이 주어진 자료들의 특징과 관계에 대한 결과를 도출 할 수 있는 장점이 있다. k-평균 군집분석의 기본 알고리즘은 다음과 같다. n개의 자료 집합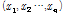 이 주어진 경우 n개의 자료를 k개의 집합
이 주어진 경우 n개의 자료를 k개의 집합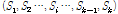 으로 자료의 응집 정도가 최대가 되도록 분할한다. 집합
으로 자료의 응집 정도가 최대가 되도록 분할한다. 집합 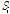 의 중심점이
의 중심점이 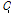 라고 할 때 아래 식 (2)와 같이 계산하여 집합 내의 중심과 각 자료간의 거리의 제곱 합을 최소로 하는 집합 S를 찾는 것이 알고리즘의 목표가 된다.
라고 할 때 아래 식 (2)와 같이 계산하여 집합 내의 중심과 각 자료간의 거리의 제곱 합을 최소로 하는 집합 S를 찾는 것이 알고리즘의 목표가 된다.
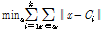 (2)
(2)
k-평균 알고리즘은 군집 내에서 유클리드(Euclid) 거리를 기반으로 자료의 유사도 정도를 설명하고 군집을 분할하는 방식이다. 즉, 각 자료간의 유사도를 집합 중심과의 거리 정도를 기반으로 구분하고 이 거리의 합을 최소화하여 재분류하는 방식으로 요약 할 수 있다. k-평균 알고리즘 과정을 순차적으로 정리하면 Fig. 2와 같다.
기댓값 최대화 알고리즘
기댓값 최대화 알고리즘 역시 k-평균 군집분석과 유사하게 초기 집합 S를 k개 구성하고 반복 계산과정을 통해 최적화된 집합 S를 구성하는 군집분석 방법이다. 그러나 k-평균 군집분석이 유클리드(Euclid) 거리가 기반인 반면에 기댓값 최대화 알고리즘은 각 자료가 집합 S에 속할 가능성을 조정하면서 최적화된 집합 S를 구성하는 차이점을 갖고 있다.
기댓값 최대화 알고리즘은 최대우도추정치(Log-likelihood)를 찾고자 하는 알고리즘으로 관심 대상의 자료가 직접 관측되지 않는 경우 관심 대상의 자료를 관측 가능한 변수들을 통해 추정하는 통계학적 방법이다. 매개변수 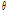 가 존재 할 경우 관측 가능한 확률변수 X, 관측 할 수 없는 확률변수 Z가 존재한다고 하자. 이 때 확률변수 X, Z의 확률분포는 아래 식 (3)으로 주어지며 우도함수는 아래 식 (4)와 같다.
가 존재 할 경우 관측 가능한 확률변수 X, 관측 할 수 없는 확률변수 Z가 존재한다고 하자. 이 때 확률변수 X, Z의 확률분포는 아래 식 (3)으로 주어지며 우도함수는 아래 식 (4)와 같다.
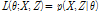 (3)
(3)
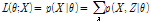 (4)
(4)
기댓값 최대화 알고리즘은 기댓값(E) 단계와 최대화(M) 단계인 두 단계를 반복하여 우도함수 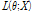 의 최대우도추정치를 구하게 된다. 기댓값(E) 단계에서는
의 최대우도추정치를 구하게 된다. 기댓값(E) 단계에서는 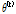 가 주어지고 새로운
가 주어지고 새로운 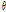 의 가능도의 기댓값 Q를 정의한다. 이 때 기댓값을 취하는 확률분포는 X,
의 가능도의 기댓값 Q를 정의한다. 이 때 기댓값을 취하는 확률분포는 X, 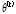 가 주어졌을 때 Z의 조건부 분포이며 아래 식 (5)와 같다.
가 주어졌을 때 Z의 조건부 분포이며 아래 식 (5)와 같다.
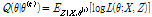 (5)
(5)
최대화(M) 단계에서는 Q를 최대화 하는 새로운 매개변수 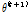 를 계산한다.
를 계산한다. 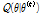 의 기대 추정치에 대한 최대우도추정치의 식은 아래 식 (6)과 같다.
의 기대 추정치에 대한 최대우도추정치의 식은 아래 식 (6)과 같다.
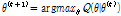 (6)
(6)
기댓값 최대화 알고리즘은 자료를 특정한 집합 S에 포함 시키는 것이 아니라 해당 집합 S속에 포함될 확률을 나타내는 가중치를 통해 자료를 각 집합에 할당시킨다. 즉, k-평균 군집분석 방법은 거리 기반의 군집분석 방법이고 기댓값 최대화 방법은 확률 기반의 군집분석 방법(probability- based clustering)이라 할 수 있다. 기댓값 최대화 알고리즘 과정을 순차적으로 정리하면 Fig. 3과 같다.
분석 결과
사람들은 관심이 있거나 필요한 정보를 인터넷 검색을 통해 얻으며 이러한 검색활동에 대한 정보는 인터넷 검색 엔진에 축적된다(Ettredge et al., 2005). 또한 특정한 의사결정에 앞서 사람들은 관련 정보를 모으며 획득한 정보를 근거로 의사결정을 내린다(Preis et al., 2013). 이는 특정 대상에 대한 관심의 증가는 인터넷 검색 빈도의 증가를 야기 시킬 가능성이 높다는 것을 의미한다.
해당 내용을 투자자의 관점으로 적용하면 특정 투자 상품에 관한 인터넷 검색 빈도의 증가는 많은 투자자들이 해당 상품에 대해 관심을 갖고 있으며, 투자에 앞서 상품에 대한 정보를 획득하고 있다는 것을 의미한다. 그리고 획득한 정보를 바탕으로 투자 의사결정을 내릴 가능성이 높음을 나타낸다. 실제로 Latoerio 등(2013)은 특정 주식의 거래량 증가는 일시적으로 해당 주식과 관련된 투자자들의 관심과 인터넷 검색 빈도가 증가함을 보여주었다.
즉, 특정 상품에 대한 인터넷 검색 빈도의 증가는 많은 투자자들이 해당 상품에 관심을 갖고 있음을 의미하며 실제 투자 의사결정을 내릴 가능성이 높다고 볼 수 있다. 이에 본 연구는 이러한 가정을 기초로 인터넷 검색 빈도와 WTI 원유 선물 가격의 변화율 관계에 대해서 k-평균 군집분석과 기댓값 최대화 군집분석을 수행하였으며 그 결과는 다음과 같다.
k-평균 군집분석 결과
인터넷 검색어 빈도와 WTI 원유 선물 가격의 변화율 관계에 대해 분석하기 위하여 k-평균 군집분석을 수행하였다. 분석을 수행하기 위해 2004년 1월부터 2016년 4월까지의 주간 WTI 원유 선물 가격과 검색어 빈도를 활용하였으며 Table 1에 활용한 자료에 대해 요약하여 정리하였다. 주간 WTI 원유 선물 가격을 활용한 이유는 인터넷 검색 자료 획득의 한계성2)을 극복하기 위해서이다. 그리고 집단화 하고자 하는 집합 S의 수 k는 Elbow Method3)를 통해 5로 선정하였다.
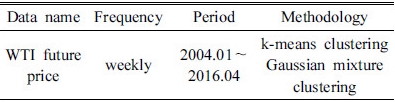
Fig. 4는 검색어 oil price의 검색 빈도에 따른 WTI 원유 선물 가격 변화율의 군집분석 결과를 나타낸다. WTI 원유 선물 가격의 변화율 0%를 기준으로 그룹 A, B는 검색어 빈도가 낮은 집합이며 WTI 원유 선물 가격의 변화율이 -5%~5% 사이에 밀집되어 있는 것을 볼 수 있다. 그러나 그룹 C, D, E는 그룹 A, B와 비교하여 WTI 원유 선물 가격의 변화율이 다소 산발적으로 분포하고 있으며 분포 범위 정도가 상대적으로 넓음을 파악 할 수 있다.
검색어 oil price의 검색 빈도에 따른 WTI 원유 선물 가격의 변화율에 대한 k-평균 군집분석 통계량을 Table 2에 정리하였다. WTI 원유 선물 가격의 변화율은 검색 빈도 평균의 증가에 따라 그 변화율 정도도 증가하는 경향을 확인 할 수 있다. 특히, 검색 빈도 평균이 가장 큰 그룹 E의 경우 WTI 원유 선물 가격 변화율의 평균값이 -6.78%로 상대적으로 높은 음의 변화율 값을 보이고 있다. 이는 2008년 금융위기와 2016년 초 세계 경제 침체로 인한 주식시장 및 원자재 시장의 급격한 변동성 증가와 가격 하락으로 인한 결과로 판단된다.
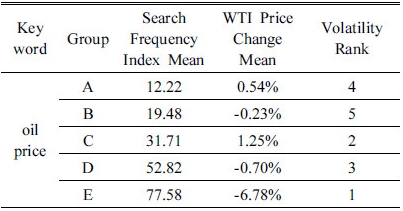
Fig. 5는 검색어 oil future price의 검색 빈도에 따른 WTI 원유 선물 가격 변화율의 군집분석 결과를 나타낸다. 검색어 oil future price 역시 검색어 oil price와 유사하게 검색어 빈도가 낮은 집합인 그룹 A, B에서 WTI 원유 선물 가격 변화율이 -5%~5% 사이에 밀집되는 모습을 보여준다. 마찬가지로 그룹 C, D, E의 경우에도 그룹 A, B에 비해 WTI 원유 선물 가격의 변화율이 다소 산발적으로 분포하고 있음을 파악 할 수 있다.
검색어 oil future price의 검색 빈도에 따른 WTI 원유 선물 가격 변화율에 대한 k-평균 군집분석 통계량을 아래 Table 3에 정리하였다. WTI 원유 선물 가격의 변화율 정도는 검색 빈도 평균이 증가 할수록 그 변화율 정도가 커지는 경향이 있음을 확인 할 수 있다. 그리고 검색어 oil price와 동일하게 그룹 E가 WTI 원유 선물가격 변화율은 -1.10%로 가장 높은 평균값을 갖고 있다.
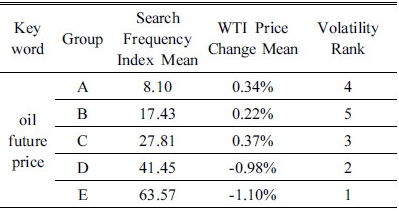
oil price, oil future price 두 검색어 모두 검색어 빈도의 평균이 가장 높은 값인 그룹 E가 -6.78%, -1.10%로 가장 높은 수준의 변화율을 보여주고 있다. 그리고 검색어 빈도의 평균이 낮은 그룹 군에 속하는 그룹 A, B의 경우에는 가장 낮은 수준의 변화율을 보여주고 있다. 이 결과를 통해서 인터넷 검색 빈도가 높을수록 WTI 원유 가격의 평균 변화율이 높은 경향을 보인다는 것을 알 수 있다.
기댓값 최대화 군집분석 결과
기댓값 최대화 알고리즘은 혼합 모델(mixture model)개념에 기반하고 있다. 혼합이라는 의미는 여러 개의 확률 분포가 혼합된 것을 의미하며 집합 S의 개수가 k라고 하면 k개의 확률 분포를 갖고 있음을 의미한다. 기댓값 최대화 군집분석에서는 정규분포 혼합 모델(Gaussian mixture model)이 주로 활용된다. 정규분포 혼합 모델은 관측된 자료가 정규분포를 따른다고 가정하고 기댓값 최대화 알고리즘을 사용하여 매개변수를 추정하는 방법으로 자료의 각 집합에 따른 분포의 정도 파악에 용이한 특징이 있다.
이에 본 연구는 검색어 oil price와 oil future price의 검색 빈도 변화에 따른 WTI 원유 선물 가격 변화율 분포 정도를 파악하기 위하여 신뢰수준 90% 범위의 정규분포 군집분석을 실시하였다. 집단화 하고자 하는 집합 S의 수 k는 Elbow Method로 선정하였으며 검색어 oil price는 4, oil future price는 3으로 설정하였다.
Fig. 6은 검색어 oil price와 WTI 원유 선물 가격의 변화율에 대한 정규분포 군집분석결과이다. 신뢰수준 90% 수준에서 각 집합의 자료 분포의 정도는 검색 빈도가 증가 할수록 그 분포 범위가 넓어지는 경향을 보이는 것을 알 수 있다. 특히, 그룹 4의 경우 다른 집합과는 달리 매우 넓은 분포 범위를 보여주고 있다. 이는 검색어 빈도가 일정 수준 보다 클 경우 WIT 원유 선물 가격의 변화율이 높을 확률이 높다는 것을 의미한다.
Fig. 7은 검색어 oil future price와 WTI 원유 선물 가격의 변화율에 대한 정규분포 군집분석 결과이다. 검색어 oil price와 비교하여 검색 빈도가 높을수록 자료 분포 범위 정도가 증가하는 경향을 뚜렷하게 보여주고 있다. 또한, 검색 빈도의 증가에 따른 WTI 원유 선물 가격 변화율 정도의 분포 범위가 넓어지는 경향도 확인 할 수 있다.
정규분포 군집분석에서 집합의 분포 범위가 넓다는 것은 해당 집합에 속하는 자료가 넓은 범위로 분포하는 것을 의미한다. 이는 WTI 원유 선물 가격 변화율이 갖는 범위가 넓다는 것을 의미함과 동시에 가격의 변동성 정도가 넓다는 것을 나타낸다. Table 4에 oil price와 oil future price 검색어의 정규분포 군집분석 결과이다. 정규분포 군집분석을 통해 신뢰수준 90% 범위에서 검색 빈도가 증가 할수록 변동성 분포 범위가 증가한다는 결과를 도출 할 수 있다.
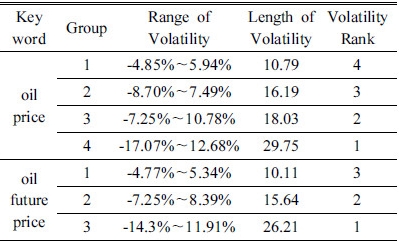
인터넷 검색 자료의 활용
Latoerio 등(2013)은 특정 주식의 거래량과 변동성이 증가하면 해당 주식과 관련된 인터넷 검색어 빈도가 증가함을 보여주었다. 본 연구에서도 인터넷 검색 자료와 WTI 원유 선물 가격의 변동성을 k-평균 군집분석과 정규분포 군집분석을 통해 분석하였으며 분석 대상의 인터넷 검색 빈도와 변동성의 관계를 효과적으로 보여주었다. 특히, 정규분포 군집분석 결과에 따르면 검색어 빈도가 증가함에 따라 WTI 원유 선물 가격의 변동성 범위가 증가하는 것을 알 수 있다. 이는 인터넷 검색 빈도가 변동성 정도를 측정하는 변수로 활용 할 수 있으며 검색 빈도를 이용한 위험관리가 가능함을 의미한다. 따라서 본 장에서는 인터넷 검색 자료를 위험관리 지표로 활용하여 기준 포트폴리오를 새로운 포트폴리오로 재구성하는 투자 전략을 제안하고자 한다.
포트폴리오 전략
인터넷 검색 자료를 위험관리 지표로 활용한 투자 전략은 기존의 포트폴리오 투자 전략에서 출발한다. 기준 포트폴리오와 인터넷 검색 빈도가 활용된 새로운 포트폴리오를 구성하고 두 포트폴리오의 성과를 비교 분석하는 방법으로 전략을 검증하였다. 포트폴리오에 포함될 개별 기업은 두 포트폴리오 모두 Dow Jones Oil& Gas Index (DJUSEN) 구성에서 가장 높은 비중을 차지하는 에너지 기업인 엑슨모빌(Exxon Mobil), 쉐브론(Chevron Corp), 슐럼버저(Schlum-berger)로 선정하였다.
해당 3기업을 선정한 이유는 임으로 구성한 포트폴리오보다 잘 알려진 지수를 기준 포트폴리오로 선정하여 수정된 포트폴리오에 대해 보다 효과적으로 분석하기 위함이다. 잘 알려진 지수를 활용 할 경우 포트폴리오 비중 설정에 대한 추가적인 고려를 하지 않아도 된다는 장점과 각 기업의 상관관계에 대해서는 분석이 되지 않아 수익률 극대화가 되는 포트폴리오는 아니라는 단점4)이 있다.
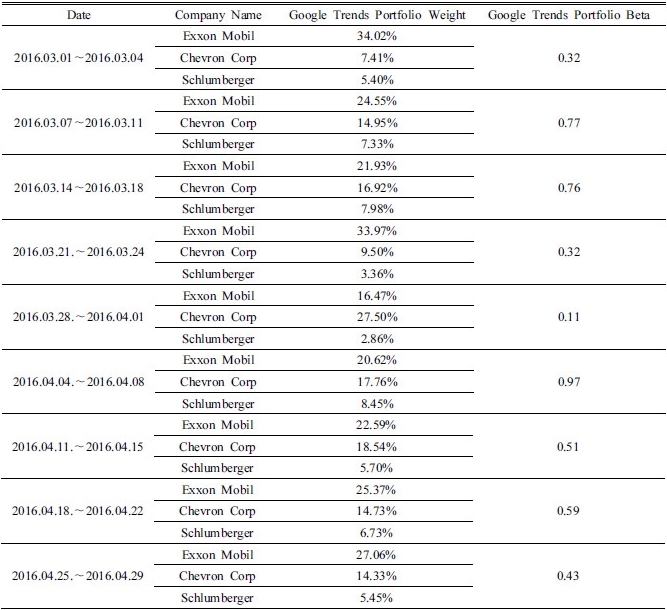
기준 포트폴리오의 개별기업 비중은 DJUSEN에서 각 개별기업이 차지하고 있는 비중5)을 그대로 사용하였다. 이는 지수를 구성하는 비중을 기준으로 포트폴리오 베타와 개별 기업 베타를 측정하기 위함이다. 기준 포트폴리오에서 사용된 개별기업 비중과 베타 값을 정리하면 Table 5와 같다.
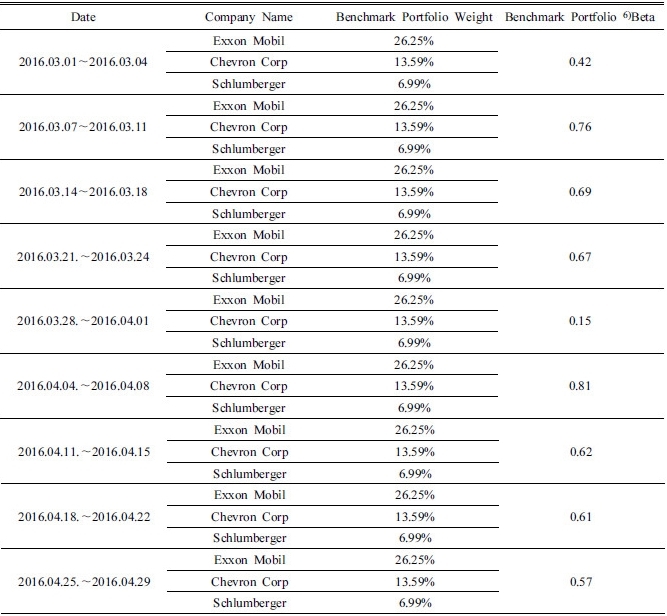
다음으로 새로운 포트폴리오를 구성하기 위하여 기존 포트폴리오에 속한 개별 기업들의 검색 빈도를 수집하였다. 인터넷 검색어는 해당 기업명과 기업을 지칭하는 티거(ticker symbol) 2가지로 설정하였고 두 검색어의 검색 빈도 평균을 사용하였다. 수집 자료의 기간은 2016년 3월, 4월 2개월 동안이며 이는 구글에서 일간 단위의 검색 빈도 자료는 최대 2~3개월 수준 내에서 제공하고 있기 때문이다. 구글에서 획득한 인터넷 검색 빈도를 기반으로 새로운 포트폴리오를 구성하기 위하여 우선적 각 기업에 대한 일간 수익률을 아래 식 (7)을 통해 계산하였다.
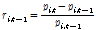 (7)
(7)
 : 기업 i에 대한 시점 t에서의 일간 수익률
: 기업 i에 대한 시점 t에서의 일간 수익률
 : 기업 i에 대한 시점 t에서의 주식가격
: 기업 i에 대한 시점 t에서의 주식가격
그리고 인터넷 검색 빈도를 위험관리 지표로 활용하기 위하여 아래 식 (8)를 통해 가중치 값을 계산하였다. 계산된 가중치가 추가된 각 기업에 대한 수정 일간 수익률은 아래 식 (9)과 같으며 식 (9)의 결과는 인터넷 검색 빈도 정도에 따라 가중치가 부여된 개별 기업의 일간 수익률이다.
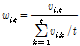 (8)
(8)
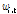 : 기업 i에 대한 시점 t에서의 가중치
: 기업 i에 대한 시점 t에서의 가중치
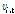 : 기업 i에 대한 시점 t에서의 검색 빈도
: 기업 i에 대한 시점 t에서의 검색 빈도
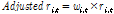 (9)
(9)
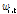 : 기업 i에 대한 시점 t에서의 가중치
: 기업 i에 대한 시점 t에서의 가중치
 : 기업 i에 대한 시점 t에서의 일간 수익률
: 기업 i에 대한 시점 t에서의 일간 수익률
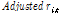 : 기업 i에 대한 시점 t에서의 가중치 일간 수익률
: 기업 i에 대한 시점 t에서의 가중치 일간 수익률
시점 t에서 기업 i에 대한 검색 빈도가 높으면 해당 기업은 시점 t에서 높은 가중치 값을 갖게 된다. 이는 기업 i의 변동성 값은 가중치로 인하여 증가하게 되고 위험도가 높아짐을 의미한다. 이를 기반으로 새로운 포트폴리오는 검색 빈도가 높아짐에 따라 높은 가중치가 부여되어 위험도가 증가한 개별 기업의 비중은 축소하고 낮은 가중치가 부여되어 위험도가 감소한 기업의 비중은 확대하는 방법을 통하여 포트폴리오의 개별 기업의 비중을 조절하였다.
새로운 포트폴리오의 수정 개별 기업 비중을 도출하기 위해 우선적으로 식 (9)에 의해 가중치가 부여된 개별 기업의 일간 수익률을 통해 개별 기업의 베타 값을 새롭게 계산하였다. 그리고 계산된 수정 개별 기업의 베타 값을 활용하여 기준 포트폴리오와 새로운 포트폴리오의 포트폴리오 전체 베타 값을 같게 해주는 수정 개별 기업의 비중을 도출하였다. 마지막으로 도출된 수정 개별 기업의 비중을 보정하여 새로운 포트폴리오의 전체 비중이 기준 포트폴리오의 전체 비중인 46.83%와 같도록 재조정하였다. 인터넷 검색 빈도가 가중치로 적용되어 새롭게 구성된 포트폴리오의 개별 기업 비중과 베타 값을 정리하면 아래 Table 6와 같다.
수정 포트폴리오 전략 적용 결과
본 연구에서 제안하는 인터넷 검색 자료를 활용한 투자 전략은 인터넷 검색 빈도를 가중치로 이용하여 기존 포트폴리오를 구성하고 있는 개별 기업의 비중을 전략적으로 조절하는 투자 전략이다. 즉, 해당 전략의 핵심은 가중치로 적용된 인터넷 검색 빈도를 통해 위험도가 높은 기업의 비중은 축소하고 위험도가 낮은 기업의 비중은 확대하여 포트폴리오의 위험은 낮추고 초과 수익을 추구하는 방법으로 요약 할 수 있다. 기준 포트폴리오와 새로운 포트폴리오의 수익률과 통계 값을 정리하면 아래 Table 7과 같다.
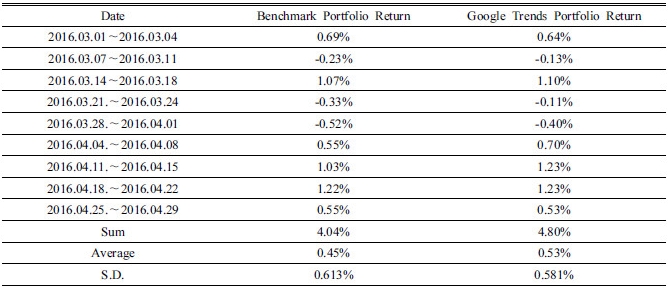
인터넷 검색 빈도를 가중치로 활용한 새로운 포트폴리오는 기준 포트폴리오와 비교하여 누적 수익률이 0.76% 증가하는 것을 확인 할 수 있다. 또한, 변동성과 위험을 나타내는 표준편차 값은 0.032% 감소한 것을 확인 할 수 있다. 즉, 새로운 포트폴리오가 기준 포트폴리오에 비해 위험은 다소 감소하고 수익률은 증가하는 결과를 보여준다.
전략에 대한 추가적인 분석을 위해 단위 위험에 대한 초과수익의 정도를 나타내는 값인 샤프비율(sharp ratio)값을 계산하였다. 샤프비율 계산에 필요한 무위험 수익률(risk free rate of return, Rf)은 일반적으로 국채수익률, CD 금리 91일물 수익률6)이 사용된다. 무위험 수익률에 따른 샤프비율 변화를 살펴보기 위하여 무위험 수익률의 범위를 0.01~0.1%로 설정 하였다. Table 8은 샤프비율 측정에 대한 결과를 정리한 내용이다.

새로운 포트폴리오의 단위 위험에 따른 평균 수익률은 0.92로 기준 포트폴리오의 0.73에 비해 0.19 높은 값을 보여준다. 또한, 무위험 수익률의 0.01~0.1% 범위 내에서 기준 포트폴리오와 비교하여 높은 샤프비율 값을 보이고 있다. 이는 새로운 포트폴리오가 기준 포트폴리오에 비해 나은 투자 성과를 보이고 있음을 의미한다. 무위험 수익률에 따른 기준 포트폴리오와 새로운 포트폴리오의 샤프비율 변화는 Fig. 8과 같다.
결 론
본 연구는 인터넷 검색 자료의 에너지 상품 시장에 대한 적용 가능성에 대해 살펴보고 그 활용 방안에 대해서 고찰해보았다. 인터넷의 보급이 활성화된 이후에 경제, 금융, 경영 등 다양한 분야에서 인터넷 검색 자료를 활용한 연구가 진행되었으나 에너지 상품 시장에서 인터넷 검색 자료를 활용한 연구는 미미한 실정이다. 또한, 기존에 실시된 선행 연구의 경우 활용성에 대해서 시계열 모형과 변동성 모형을 통해 분석했으며 주로 경제 활동 및 지표 예측을 시도했다. 이에 본 연구는 인터넷 검색 자료를 거시 경제, 금융 그리고 경영 분야뿐만 아니라 에너지 상품 시장에 적용을 시도했다는 점에 의의가 있으며, 기존과 다른 접근 방식인 군집분석을 통해 인터넷 검색 자료와 분석 대상의 실질적인 거동 관계와 변동성에 대해 초점 맞춰 분석을 실시하였다는 것이 특징적이다.
k-평균 군집분석과 정규분포 군집분석을 통해 WTI 원유 선물 가격 변화율의 범위가 증가함에 따라 인터넷 검색 빈도가 증가하는 경향을 확인할 수 있었다. 해당 결과는 WTI 원유 선물 가격 변화율이 커질수록 인터넷 검색 빈도가 증가 한다는 것을 의미하고 인터넷 검색 빈도를 위험관리 측면에서 활용이 가능함을 나타낸다. 실제 위험관리 측면에서의 활용을 확인하기 위해 인터넷 검색 자료 기반의 포트폴리오를 구성하여 기준 포트폴리오와 성과를 비교해보았다. 기준 포트폴리오에 비해 인터넷 검색 자료 기반의 포트폴리오는 표준편차가 0.032% 감소하여 위험도가 낮게 측정되었으며 주간 평균 수익률은 0.08%가 증가한 성과를 보여주었다. 이는 인터넷 검색 빈도가 위험관리 지표로 활용이 가능함을 시사한다.
