

서 론
탄성파 탐사의 궁극적인 목표는 지하의 구조와 물성을 탐사를 통해 간접적으로 파악하여 석유·가스 생산이나 이산화탄소 지중저장 등의 성공 확률을 높이는 것이다. 구조는 주로 구조보정을 통한 영상화로 파악하거나, 물성 역산을 통해 추정한다. 역산을 통해 추정한 물성은 암상 분류(lithofacies classfication), 저류층 모델링(reservior modeling)등에 활용되는 기초 자료로서의 역할을 하게 되며 그 정확도가 매우 중요하다. 따라서 정확한 역산은 그 중요도가 매우 크며 많은 연구자들이 탄성파 탐사에서의 역산 기법을 연구하였다.
이러한 역산은 그 접근법에 따라 크게 두 가지 방법으로 나뉘게 되는데, 탐사 데이터와 모델 데이터의 차이를 잔차로 설정하고 잔차를 줄여나가는 결정론적 역산(deterministic inversion)과 모델을 제시하고 모델의 타당성을 검토하여 모델을 업데이트하는 추계학적 역산(stochastic inversion)으로 나뉘게 된다(Tarantola, 2005). 결정론적 역산은 잔차의 미분 등을 통하여 초기 모델로부터 업데이트 방향을 결정하여 물성을 조금씩 실제 지구와 비슷하게 만드는 방법이다(Torres-Verdin et al., 1999). 반면 추계학적 역산은 베이즈 추론에 기반하여 지구의 물성을 사전정보와 탐사 데이터를 결합하여 확률을 통해 추정하는 방법이다(Zhang et al., 2012). 베이즈 추론은 추정하려는 분포(target distribution)를 정확하게 알지 못하며 직접 구할 수도 없는 경우 사전 분포(prior distribution)와 가능도(likelihood)를 통한 표본 추출을 통해서 간접적으로 사후 분포(posterior distribution)를 구하여 분포를 추정하는 방법이다(Lee and Lee, 2022). 일반적으로 사전정보는 데이터 관측 이전에 알고있는 정보를 의미하지만, 탄성파 탐사 추계학적 역산에서는 제시하는 모델을 제한하는 역할을 한다. 탐사 데이터는 가능도에 해당하며, 추계학적 역산에서는 제시하는 모델의 타당성을 판단하는 역할을 한다. 이러한 추계학적 역산은 사후 분포를 통계적으로 분석할 수 있다는 점에서 결정론적 역산과 달리 불확실성 분석이나 국소값(local minimum) 탈출이 가능하다는 장점이 존재한다(Francis, 2005).
사후 분포를 따르는 서로 독립인 사후 표본으로 사후 분포를 근사하여 분석할 수 있다는 것은 이미 잘 알려졌지만, 실제 통계적 분석의 경우에는 사후 분포의 차원이 매우 크기 때문에 독립적인 사후 표본을 추출하는 것이 현실적으로 불가능하다. 따라서 매우 간단한 경우를 제외하고는 사후 분포를 계산할 수 없었기 때문에 베이즈 통계학을 통한 추론은 실용적이라고 보기는 어려웠다(Lee and Lee, 2022). 그러나 겔판드와 스미스는 추정하고자 하는 분포의 차원이 크더라도 각 표본을 조건부 사후 분포에서 충분히 많이 추출하면 표본들이 마르코프 체인(Markov Chain)을 구성하며 추출된 표본의 분포가 추정하고자 하는 분포에 근사됨을 보였다(Gelfand and Smith, 1990). 추출된 각 표본은 조건부 분포에 의해 종속성을 가져 독립은 아니지만, 해당 표본들을 독립적인 표본으로 간주하여 몬테 카를로 표본으로 활용할 수 있다는 점은 차원이 복잡한 분포에서도 사후 분포를 표본 추출을 통해 추정할 수 있다는 획기적인 아이디어를 제시하였다. 이 아이디어로부터 사후 분포를 실용적으로 추출하는 방법을 고안하였고 비로소 베이즈 통계학을 활용한 추론에 관한 연구가 본격적으로 수행되었다. 사후 분포를 추정하는 방법에는 마르코프-체인 몬테카를로(Markov-Chain Monte Carlo, MCMC) 방법이 주로 사용되며 초기 모델에서 사전 분포를 활용하여 새로운 모델을 제시하고, 가능도를 기준으로 새로운 모델의 수락과 거절을 반복하며 사후 분포의 추출을 진행하는 방식으로 사후 분포를 얻는다. 새로운 모델을 제시하는 방법이나 추출 방법에 따라 메트로폴리스 추출법(Metropolis-Hastings Sampling), 깁스 추출법(Gibbs Sampling), 슬라이스 추출법(Slice Sampling), 해밀톤 추출법(Hamiltonian Sampling), 가역도약 추출법(Reversible Jump Sampling), 순차적 몬테카를로(Sequential Monte Carlo) 등으로 구분된다(Lee, 2023).
이러한 MCMC기법들은 상기한 장점들에도 불구하고 본질적으로 많은 연산량 및 저장용량을 요구하기 때문에 대용량 자료의 경우에는 접근이 쉽지 않다. 이러한 경우 MCMC의 장점은 유지하면서 저장용량을 줄이기 위해 가늘게 하기(Thinning, 희석, 솎아내기)를 적용한다. 가늘게 하기는 많은 베이지안 통계학 연구에 적용되었으며, 탄성파 자료를 활용한 역산 등에도 활용되었다. 탄성파 탐사 자료를 활용한 선행 연구에서도 가늘게 하기는 자료가 가지고 있는 숨겨진 정보를 버리는 과정이기 때문에 정확한 역산을 위해서는 가늘게 하기를 적용하지 않는 것을 권장(Bottero et al., 2016)하였다. 그러나 이러한 단점에도 불구하고 탄성파 자료의 용량이 너무 큰 경우는 가늘게 하기를 적용하여 부담을 낮추고자 하는 시도가 꾸준히 적용되었다(Izzatullah et al., 2021; Zhang et al., 2013). 그러나 이러한 시도들은 연구 과정에서 저장 용량의 부담을 덜기 위해 적절한 가늘게 하기를 적용한 것이고, 가늘게 하기 자체의 초점을 맞춘 연구는 존재하지 않았다. 따라서 본 연구에서는 탄성파 자료의 추계학적 역산을 수행할 때 가늘게 하기를 적용한다면 어느 정도의 가늘게 하기를 적용해야 하는지에 초점을 맞추어 분석하고자 한다.
본 논문에서는 가늘게 하기에 대한 간단한 소개를 한 후, 추계학적 역산에 및 가늘게 하기를 노르웨이의 Norne 지역 탐사 데이터에 대해서 적용한다. 이후 가늘게 하기 적용에 따른 역산 결과를 분석하여 가늘게 하기 적용의 장점을 논하고 희석수에 따른 불확실성 분석을 진행한다.
MCMC 기법과 가늘게 하기
수학적으로는 마르코프 체인의 개수가 무한하다면 사후 분포가 추정하고자 하는 분포와 동일해지지만, 현실적으로는 마르코프 체인의 개수를 무한히 늘릴 수 없기 때문에 유한한 개수의 체인을 가지게 된다. 이러한 점에서 MCMC는 추출한 표본들이 독립이 아니라는 근본적인 전제조건 때문에 사후 분포가 추정하고자 하는 분포와 사후 분포 사이의 수렴을 보장함에 있어 태생적으로 몇 가지 한계가 존재한다(Lee and Lee, 2022). 첫 번째는 초깃값(initial model)과 번인(burn-in)문제로, 초기 표본이 실제 분포로부터 멀리 떨어진 곳에서 추출을 시작할 경우 멀리 떨어진 지점을 우선으로 탐색하며 실제 분포에 가까워지므로 초기의 표본들이 편향된 결과를 가진다는 점이다. 두 번째는 자기상관(auto-correlation)문제로, 자기상관은 시계열 혹은 체인의 데이터끼리 얼마나 상관되어 있는가를 나타내는 값이다. 체인에서 n번째 표본이 n-k번째 표본과 얼마만큼의 상관관계가 있는지를 나타내는 자기상관계수는 식 (1)과 같이 나타나며, 1은 완전한 자기상관, 0은 무상관관계, –1은 완전한 음의 자기상관이다.
Fig. 1은 평균이 0이고 표준편차가 1인 정규분포로부터 독립적인 표본 추출과 종속적인 마르코프 체인의 표본 추출 결과와 각 표본의 자기상관계수를 나타낸 예시이다. 독립적으로 추출한 파란색 선의 경우는 이전 결과에 상관없는 값이 추출되어 자기상관계수가 낮게 나타나지만, 종속적으로 추출한 빨간색 선의 경우는 자기상관계수가 매우 높게 나타나는 것을 확인할 수 있다.
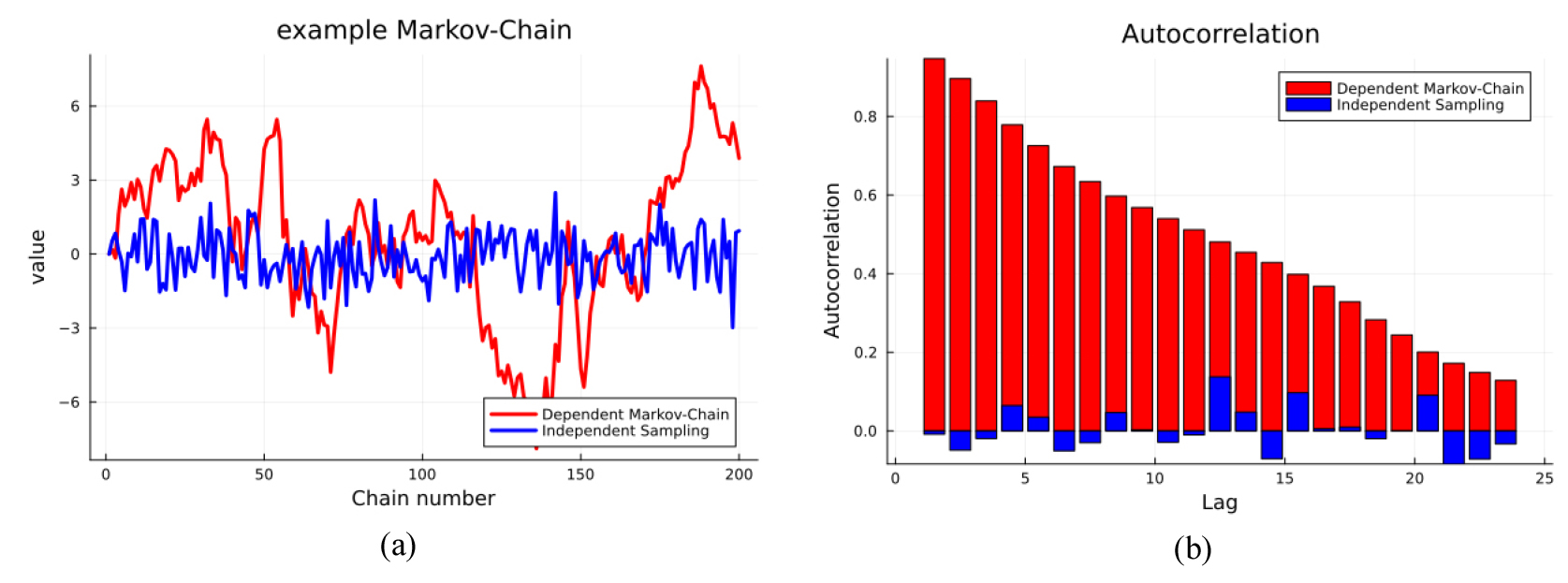
MCMC 알고리듬은 이전 표본의 조건부 분포로부터 다음 표본을 탐색하는 ‘보행(walk)’ 과정을 거치기 때문에 표본끼리의 자기상관관계가 높게 나타나는 경향이 있다. 이는 공간을 탐색 중인 체인의 경우 뚜렷하게 나타나며, 수렴 이후 ‘잘 섞인 상태(well-mixed)’인 경우에는 자기상관관계가 낮게 나타난다. 정확한 사후 분포의 분석을 위해서는 자기상관관계가 낮은 표본에 대해서 분석하는 것이 이상적이지만, 자기상관계수가 낮아질 때까지 무작정 추출을 반복하는 것도 현실적으로 불가능하다. 마지막 문제는 사후 분포를 담고 있는 표본들의 개수의 한계이다. 표본들의 개수를 늘리면 더욱 정확한 사후 분포 추정이 가능하지만, 체인 추출 과정에서 소요되는 시간이 표본 수에 비례해서 증가하고 표본의 용량 역시 증가하여 저장이나 통곗값 분석에 있어 연산량이 증가하게 된다. 번인 문제는 정확한 초기 모델을 사용하고 사후 분포를 추정함에 있어 초기 표본 일부를 버리고 수렴 이후의 표본만 사용하여 편향성을 줄이는 방법으로 해결이 가능하다.
이처럼 마르코프 체인의 문제점을 샘플링 기법을 통해 일부 해결 가능하며, 자기상관문제와 표본 수의 한계는 가늘게 하기를 통해 해결 가능하다는 것이 알려져 있다. 가늘게 하기는 표본 추출 과정에서 모든 표본을 저장하여 사용하는 것이 아닌 일정 간격마다 표본을 저장하여 사후 분포 분석에 사용하는 것이다(Riabiz et al., 2022). 이때 저장하는 간격을 희석수(Thinning number, 가늘게 하기수)라고 하며, 샘플의 개수를 원본 체인에 비해 1/희석수 만큼 줄여주게 된다.
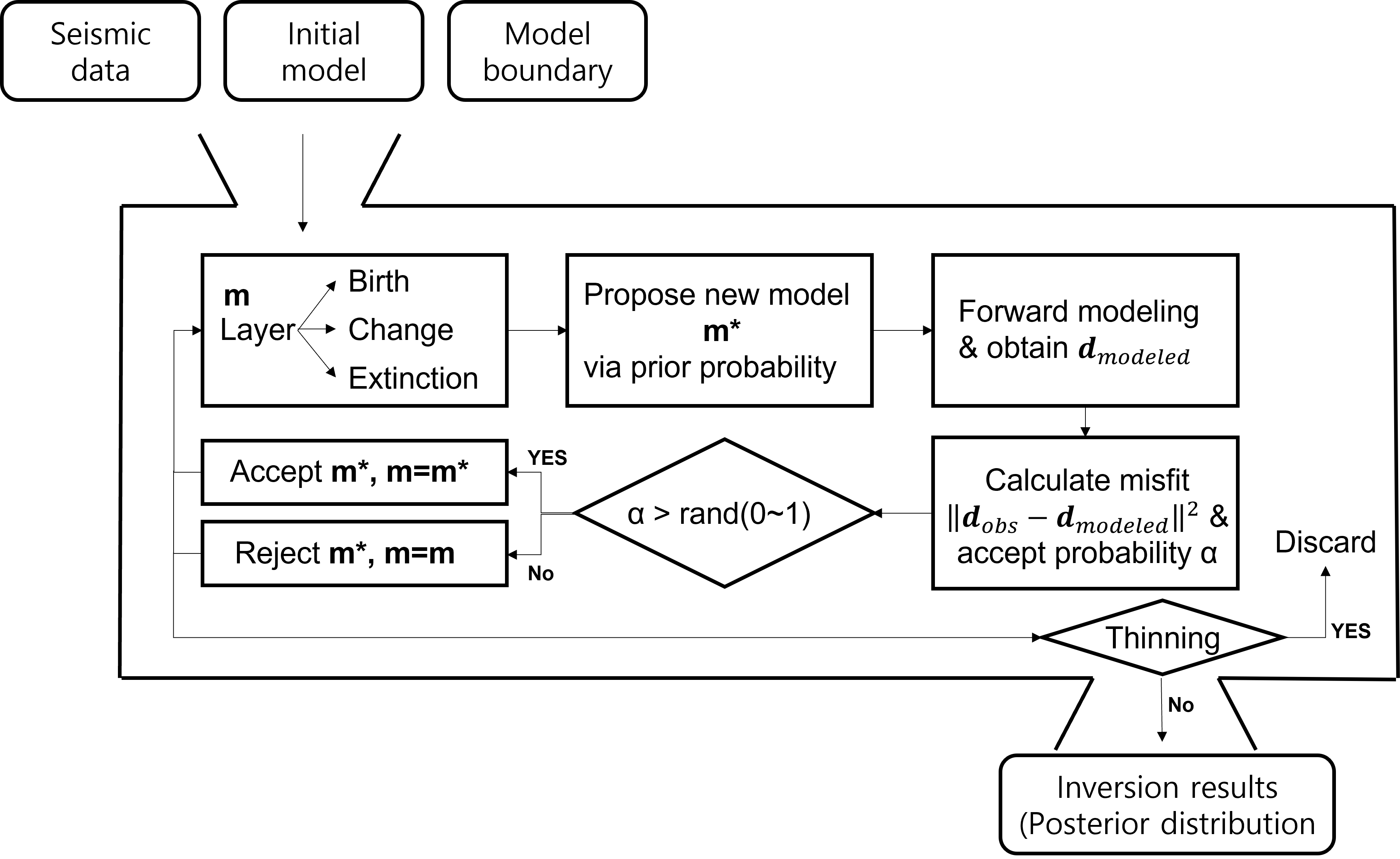
Fig. 2는 가늘게 하기의 개념을 간단하게 시각화한 모식도이다. 초기 모델 로부터 새로운 모델 을 제시하고, 제시한 모델 이 타당한지를 가능도 기준으로 판단하여 수락 혹은 거절한다. 이를 다음 모델 를 제시하는데 사용하며 MCMC의 체인 길이만큼 반복한다. MCMC기법은 이 과정에서 제시되는 모든 모델 을 사후 분포에 저장한다. 그러나 가늘게 하기를 적용하면 MCMC의 체인 길이만큼 반복하는 과정은 동일하나 모든 모델을 사후 분포에 저장하지 않는다. 모델을 희석수 간격으로 저장하여 일부 모델만 사후 분포에 저장한다. 사후 분포에 저장되는 모델의 수가 줄기 때문에 사후 분포의 저장 용량을 줄이고, 인접한 모델(,)이 연속으로 사후 분포에 저장되지 않기 때문에 자기상관계수가 줄어들게 된다.
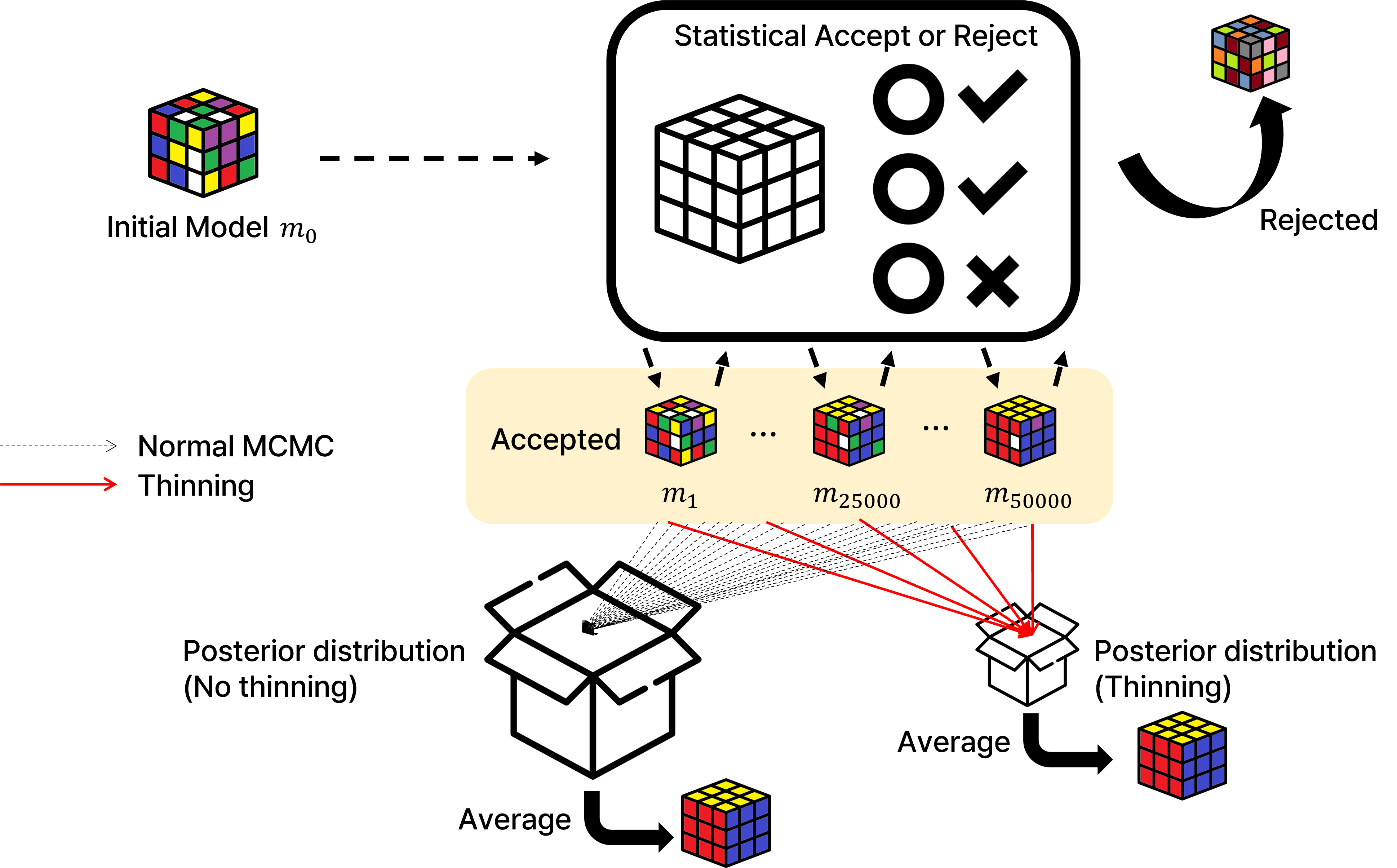
상기하였듯이 자기상관계수를 줄이고 저장 용량을 줄여주는 장점이 있어 동일 저장용량 하에서 가늘게 하기를 적용한 만큼 추가적인 표본 추출이 가능하지만, 추정치의 정확성 자체를 개선하는 방식이 아니기 때문에 저장 용량이 제한되는 상황이 아니면 불필요하다고 알려져 있다(Link and Eaton, 2012). 과거에는 정보 저장 기술이 발달하지 않아 저장 공간의 제한 때문에 가늘게 하기를 많이 적용하였지만, 최근에는 기술의 발달로 인해 일반적으로는 가늘게 하기를 잘 적용하지 않는 추세이다. 그러나 탄성파 탐사 자료의 경우는 일반적으로 매우 넓은 지역을 탐사하고 수치해석을 사용할 경우 높은 해상도를 사용하기 때문에 탐사 데이터와 모델의 용량이 매우 크게 나타난다. 3차원 추계학적 역산의 경우 탐사 지역의 모델을 마르코프 체인의 반복 수만큼 저장하여야 하므로 저장 용량의 명확한 한계를 가지게 된다. 따라서 3차원 역산 자료에 가늘게 하기의 적용은 마르코프 체인의 길이를 늘려 보다 실제 지구 물성에 가까운 사후 분포 획득에 도움이 된다.
Norne 데이터 및 추계학적 역산
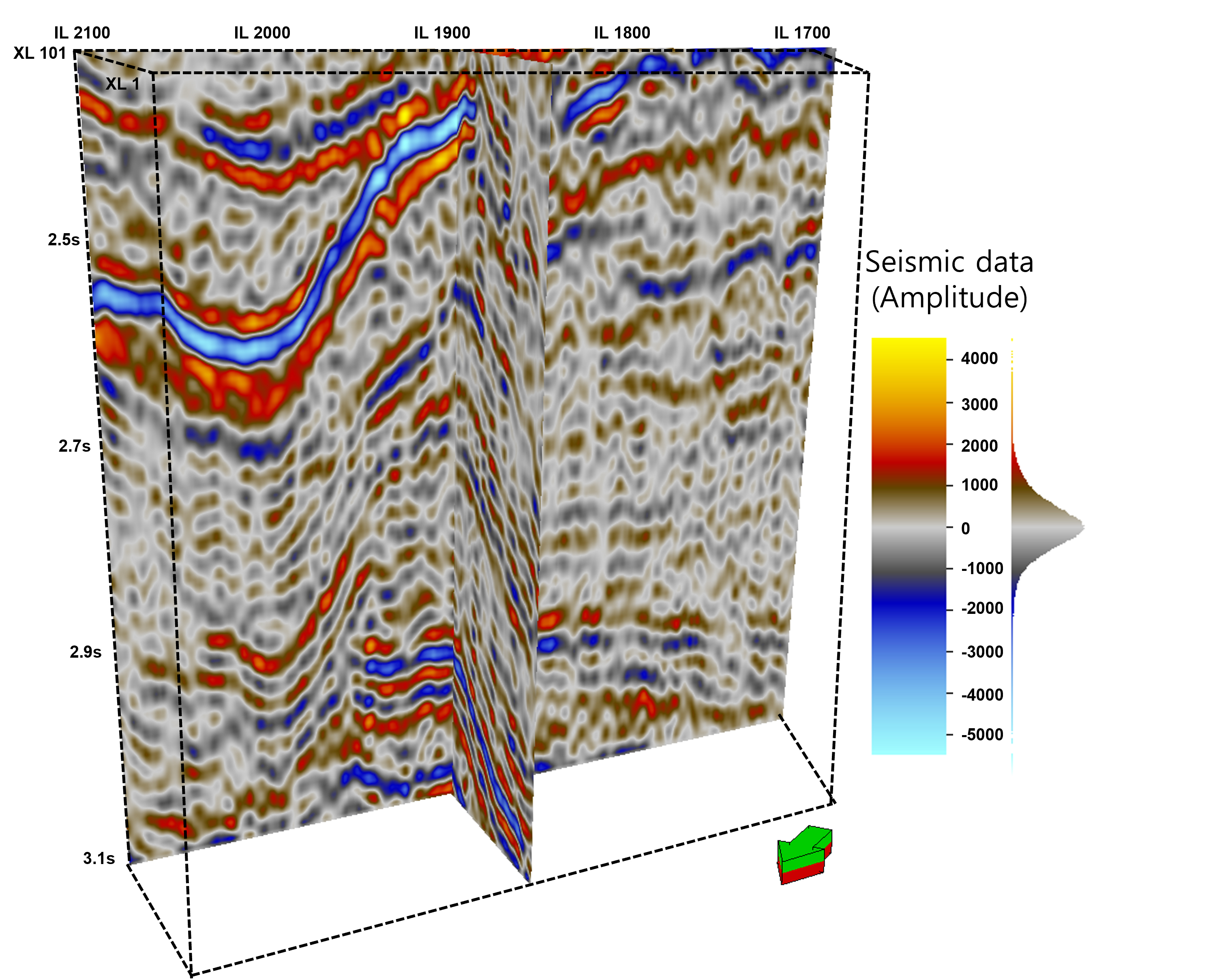
본 논문에서는 노르웨이 지역의 Norne 현장 자료를 사용하여 가늘게 하기의 적용성을 확인하였다. Norne 현장은 노르웨이해 Nordland Ⅱ 지역 남쪽에 위치하며, 1991년 발견 이후 생산 준비를 거쳐 1997년부터 계속 석유와 가스를 생산하고 있는 광구이다(Rwechungura et al., 2010). Fig. 3에 나와 있듯이 Norne 현장은 전체 구역 중 C, D, E 그리고 G 구역으로 나누어져 있다. 분석에 사용한 현장 자료는 E 구역의 석유·가스 저류층이 뚜렷한 부분을 일부 잘라서 사용하였으며, 탐사 영역은 Fig. 4에 나타나듯이 400 인라인 데이터와 101 크로스라인 데이터로 총 40,400개의 트레이스 중 석유·가스의 저류층 구조가 뚜렷하게 나타나는 2.3~3.1초(양방향 도달시간, two-way time) 구간만 잘라 역산에 사용하였다. 각 트레이스 별 길이는 250개의 데이터로 이루어져 있다. Fig. 4은 본 연구에서 사용한 3차원 탄성파 자료를 나타낸 그림이며, 향사 구조가 뚜렷하게 나타나는 지점을 선정하여 나타내었다.
추계학적 역산은 식 (2)와 같이 베이즈 추론(Bayesian inference)에 기반한다.
은 추정하고자 하는 지구의 물성, 는 탄성파 탐사를 통해 획득한 자료에 해당한다. 는 사후 확률분포, 는 가능도, 는 사전 확률분포로 나타난다. 사전 확률분포는 모델 이 제시될 수 있는 사전 정보를 담고 있으며, 가능도는 제시된 모델 이 얼마나 타당한지를 정량적으로 판단하는 역할을 한다. 가능도는 모델링 결과와 탐사 데이터 사이의 잔차를 가우시안 분포(Gaussian distribution)으로 가정(Bodin and Sambridge, 2009)하고 식 (3)과 같이 나타내었다.
본 연구에서는 MCMC의 알고리듬 중 차원이 다른 상태 공간을 넘나들면서 표본을 추출하는 가역도약 추출법(rjMCMC)를 적용하여 총 50,000번의 표본 추출 과정을 진행하였다(Cho et al., 2018). 가역도약 추출법은 물성 모델에서 물성의 차원을 추가하기도, 제거하기도 하며 최적의 차원으로 수렴해 나가는 방법으로, 그 구현이 어렵지만 차원의 과대-과소 추정을 막을 수 있어 지구물리학 등 추정하고자 하는 값의 차원이 명확하지 않은 경우 많이 적용된다(Sambridge et al., 2006; Zhu and Gibson, 2016). 일반적인 가역도약 추출법에서는 부분공간(subspace)의 구성에 따라 차원 전이에 가중치를 주는 경우가 일반적이다(Lee, 2023). 하지만 본 역산 과정에서는 차원의 추가, 유지, 제거에 모두 동일한 확률을 적용하여 차원 탐색에 있어 편향된 모델이 발생하지 않도록 설정하였다.
사전 확률분포는 N개의 가능한 차원에서 n-차원의 모델이 제시될 확률로써 식 (4) 및 (5)와 같이 나타난다.
식 (3), (4), (5)를 통해 기존 모델 과 의 사후 확률을 계산할 수 있으며, 이를 통해 의 수락확률을 식 (6)과 같이 계산할 수 있다.
는 에서 으로 제안되는 커널의 역할을 하며, 는 에서 으로 전환 시에 자코비안 행렬이며, 본 전이식에서는 항등행렬로 간주 가능하다(Bodin and Sambridge, 2009; Bodin et al., 2012). 최종적으로 α의 값이 0~1 사이의 임의의 난수와 비교하는 과정을 거치며(walk), 만약 임의의 난수보다 크다면 이 타당한 모델이라고 판단하고 수락한다.
역산에 활용되는 초기 모델은 Norne 지역에서 유일하게 물리검층 자료를 가지고 있는 10-E-3H 시추공 자료를 활용하여 음파 검층(sonic log)자료와 밀도 검층(density log)자료로부터 1차원 모델을 설정하였다. 역산에 활용되는 파원(source wavelet)은 탄성파 자료로부터 추정하였으며, 최종적으로 1차원 모델에 파원을 합성곱(convolution)하여 3차원 초기 모델을 설정하였다. 추계학적 역산과 가늘게 하기의 전체적인 흐름을 Fig. 5에 나타내었다. MCMC 체인을 구성하는 과정에서 의 체인 차수가 희석수의 배수라면 최종 사후 분포에 포함하고, 그렇지 않다면 사후 분포에는 포함하지 않고 다음 체인 추정에만 사용한다.
역산은 P파의 속도와 밀도를 역산하였으며 50,000개의 사후 분포 평균을 취하여 Fig. 6에 나타내었다. Fig. 6의 좌상단 그림은 역산에 사용한 초기 모델이며, 시추공 10-E-3H의 물리검층 데이터를 활용하여 구성하였다. 우상단 그림은 역산 결과를 통한 모델링 결과이며, Fig. 4과 유사하게 나타난다는 점에서 추계학적 역산이 탄성파 자료를 잘 모사함을 확인할 수 있다. 좌하단 그림은 역산 결과 중 P파 속도를 나타내었으며, 우하단 그림은 밀도를 나타내었다.
마르코프 체인 기반 추계학적 역산 결과 및 분석
역산 결과에 가늘게 하기를 적용한 결과를 비교하기 위해서, Fig. 6의 P파 속도 3차원 자료 중 임의의 트레이스(101번째 지점)를 선택하여 가늘게 하기를 적용하여 Fig. 7에 나타내었다.
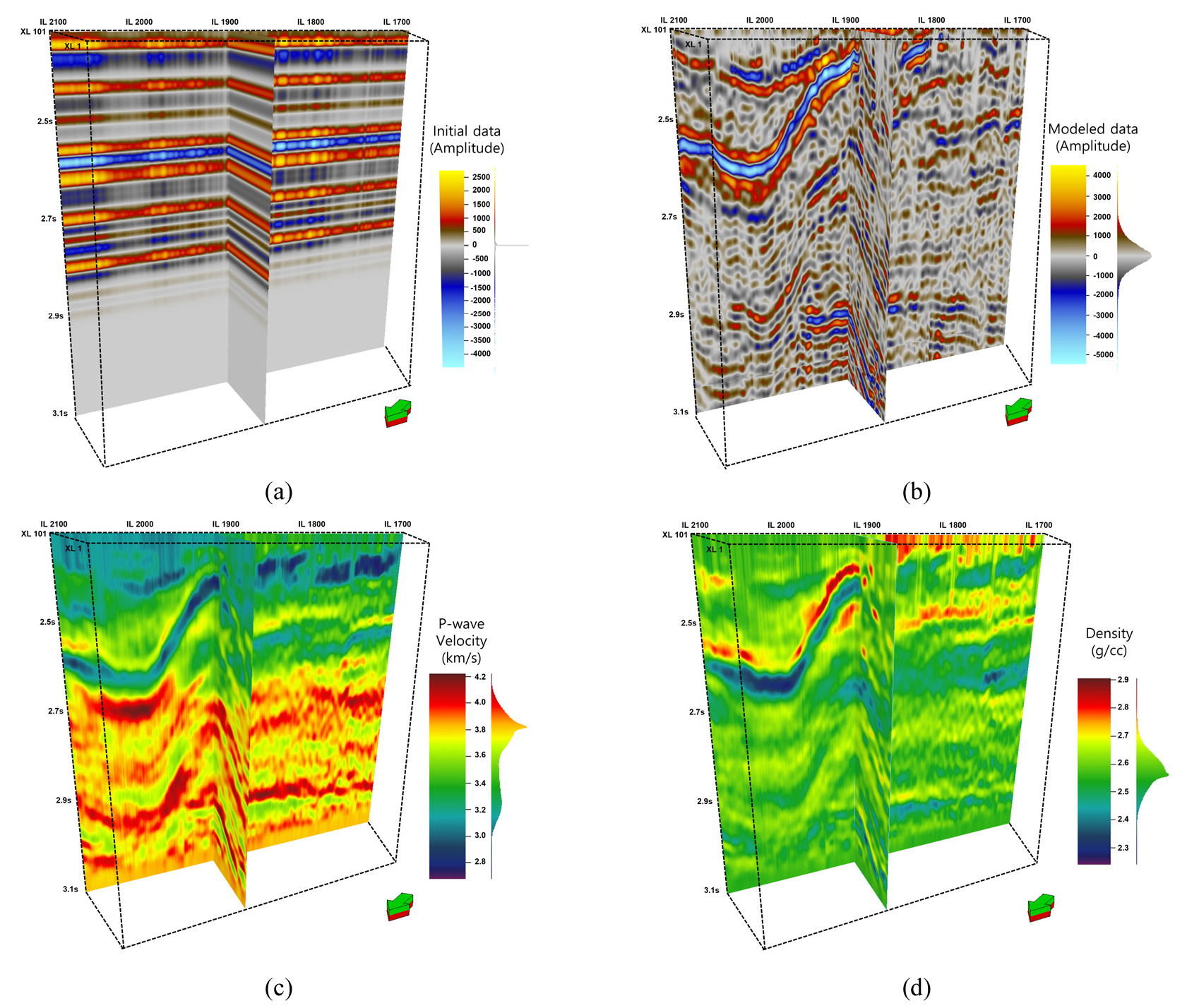
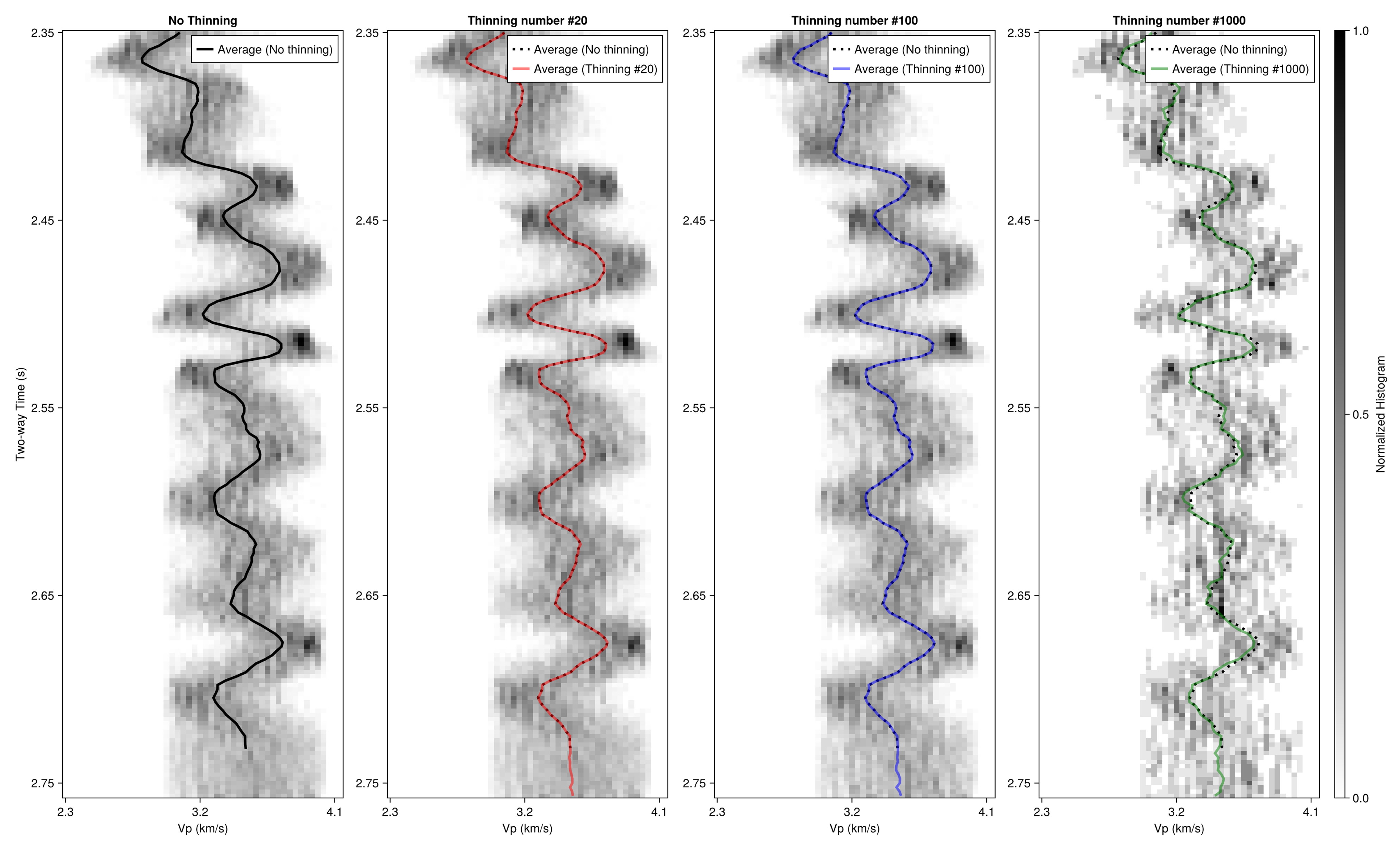
Fig. 7.
Inversion results with varying thinning numbers. The background shows the normalized histograms of estimated P-wave velocity (Vp). The black line represents the average profile without thinning, while the red, blue, and green lines correspond to thinning numbers of 20, 100, and 1000, respectively.
Fig. 7은 좌측부터 순서대로 가늘게 하기를 적용하지 않은 표본, 희석수 20, 희석수 100, 희석수 1,000으로 가늘게 하기를 적용한 결과를 나타낸 그림이다. 대표 경우로 해당 희석수를 사용한 이유는 가늘게 하기의 결과를 시각적으로 나타내기 위함이며, 희석수의 변화에 따른 결과는 후술한다. 각 표본은 정규화된 누적 히스토그램을 통하여 사후 분포로 나타내었으며, 각 사후 분포의 평균을 선으로 나타내었다. 가늘게 하기를 적용하지 않은 50,000개의 표본 평균은 흑색 점선으로 나타내었고, 가늘게 하기를 적용한 표본 평균은 각각 적색, 청색, 녹색으로 나타내었다.
Fig. 7에서 확인할 수 있듯이 가늘게 하기를 적용한 사후 분포는 희석수가 너무 커지지만 않는다면 온전한 사후 분포에 거의 근사하는 것을 확인할 수 있다. 또한 대푯값을 구하기 위해 평균을 취하더라도 희석되지 않은 평균값과 큰 차이가 나지 않는 것을 확인할 수 있다. 이는 마르코프 체인의 길이가 충분히 길어 체인 전체가 잘 섞인 경우는 가늘게 하기를 적용하더라도 사후 분포를 왜곡하지 않음을 의미한다. 마르코프 체인의 길이는 저장 용량과 연산 시간에 비례하는데 연산 시간은 MCMC의 알고리듬이나 계산 환경에 크게 영향을 받기 때문에 일반화하기 어렵다. 하지만 저장 용량은 가늘게 하기를 적용하며 저장 용량을 낮추고, 그만큼 체인을 길게 설정하여 체인이 잘 섞임을 보장할 수 있다.
Fig. 8은 기록시간 2.63초 지점에서 P파 속도의 사후 표본을 히스토그램으로 나타낸 결과이다. 가늘게 하기를 적용하더라도 전체적인 히스토그램의 양상은 크게 변하지 않지만, 희석수를 1,000으로 설정한 경우는 사후 표본의 개수가 50개밖에 되지 않아 히스토그램에서 P파의 분포가 일부 왜곡됨을 확인하였다. 따라서 저장 용량의 제한이 심한 경우가 아니라면 과도한 가늘게 하기는 피하여야 한다.
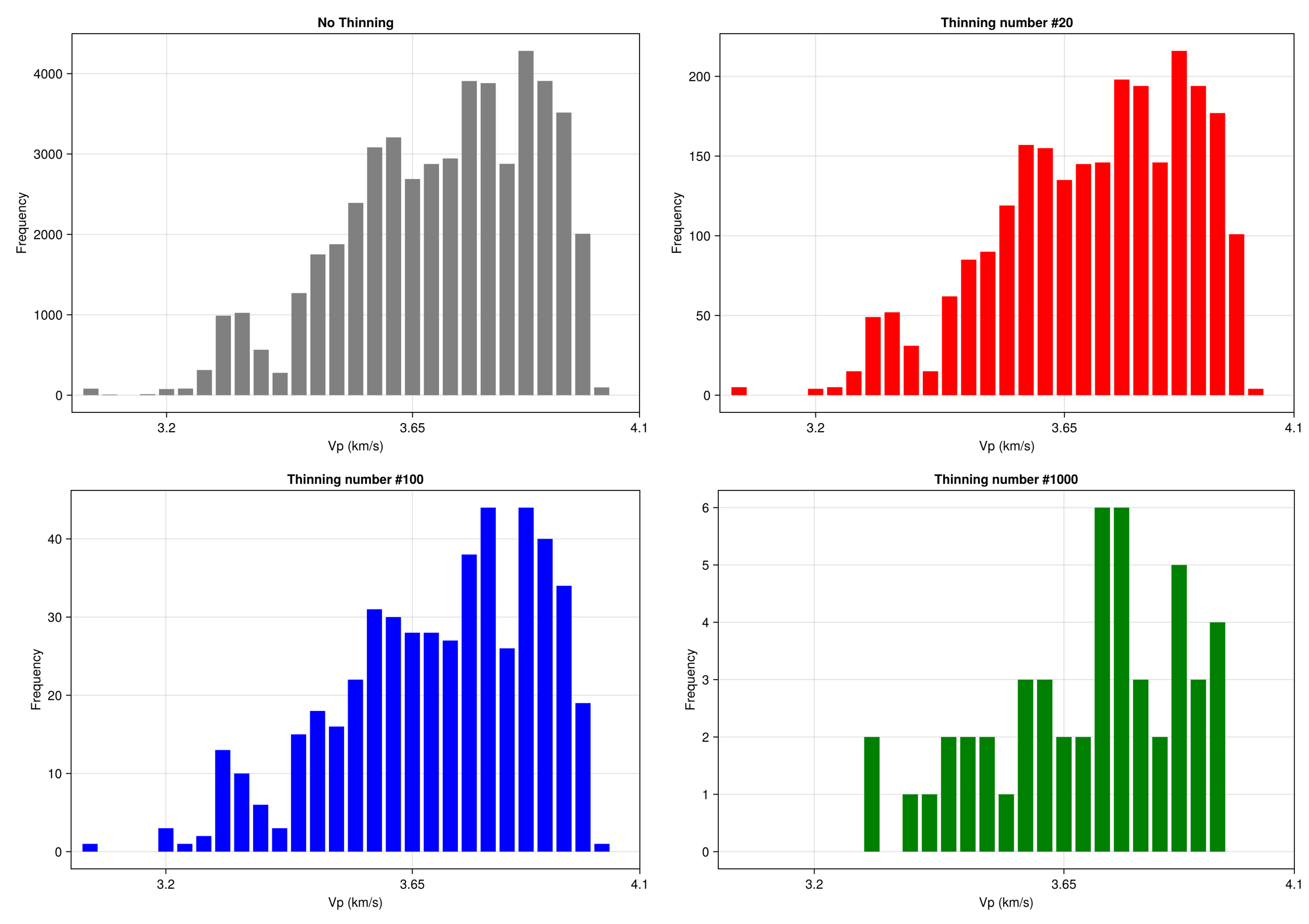
Fig. 9는 기록시간 2.63초 지점에서 각 사후 표본의 자기상관계수를 분석한 결과이다. 가늘게 하기를 적용하지 않은 경우는 회색, 가늘게 하기를 적용한 경우는 희석수 20, 100, 1000에 대해서 각각 적색, 청색, 녹색으로 나타내었다. 가늘게 하기를 적용한 후에 자기상관계수가 빠르게 감소하며, 이는 희석수가 커질수록 그 정도가 더욱 커짐을 확인할 수 있다. 희석수 1,000의 경우는 음의 상관계수가 나오기도 하여 과도한 가늘게 하기 적용이 이루어졌음을 추정할 수 있으며, 그 외의 경우는 평균값을 왜곡하지 않으면서도 자기상관계수를 효과적으로 낮춤을 확인하였다. 이는 추계학적 역산의 결과가 해가 존재할 수 있는 범위를 다양하게 반영함과 동시에 신뢰성 있는 결과를 가져다줌을 의미한다.
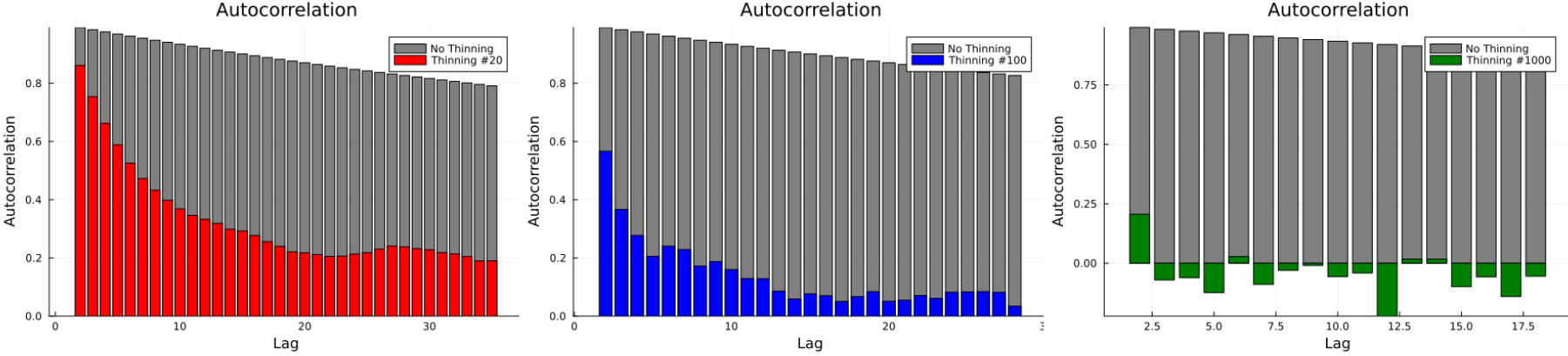
Fig. 10은 길이(반복 횟수)가 50,000이 아닌 10,000인 역산으로부터 가늘게 하기를 적용한 결과를 나타낸 그림이다. 마르코프 체인의 길이가 짧은 경우는 체인 표본의 개수 자체가 적은 MCMC 표본 추출을 의미하며, 추정하고자 하는 분포에 충분히 근사가 되지 않았음을 내포한다. 충분히 근사되지 않은 마르코프 체인에 가늘게 하기를 적용하면 Fig. 10에서 확인할 수 있듯이 그 오차가 크게 나타나는 것을 확인할 수 있다. Table 1은 마르코프 체인의 길이와 희석수의 크기에 따른 사후 분포의 평균 제곱근(Root Mean Square, RMS)를 나타낸 결과로, 체인의 길이가 충분하지 않은 상태에서 가늘게 하기를 적용하면 그 오차가 매우 커짐을 확인할 수 있다.
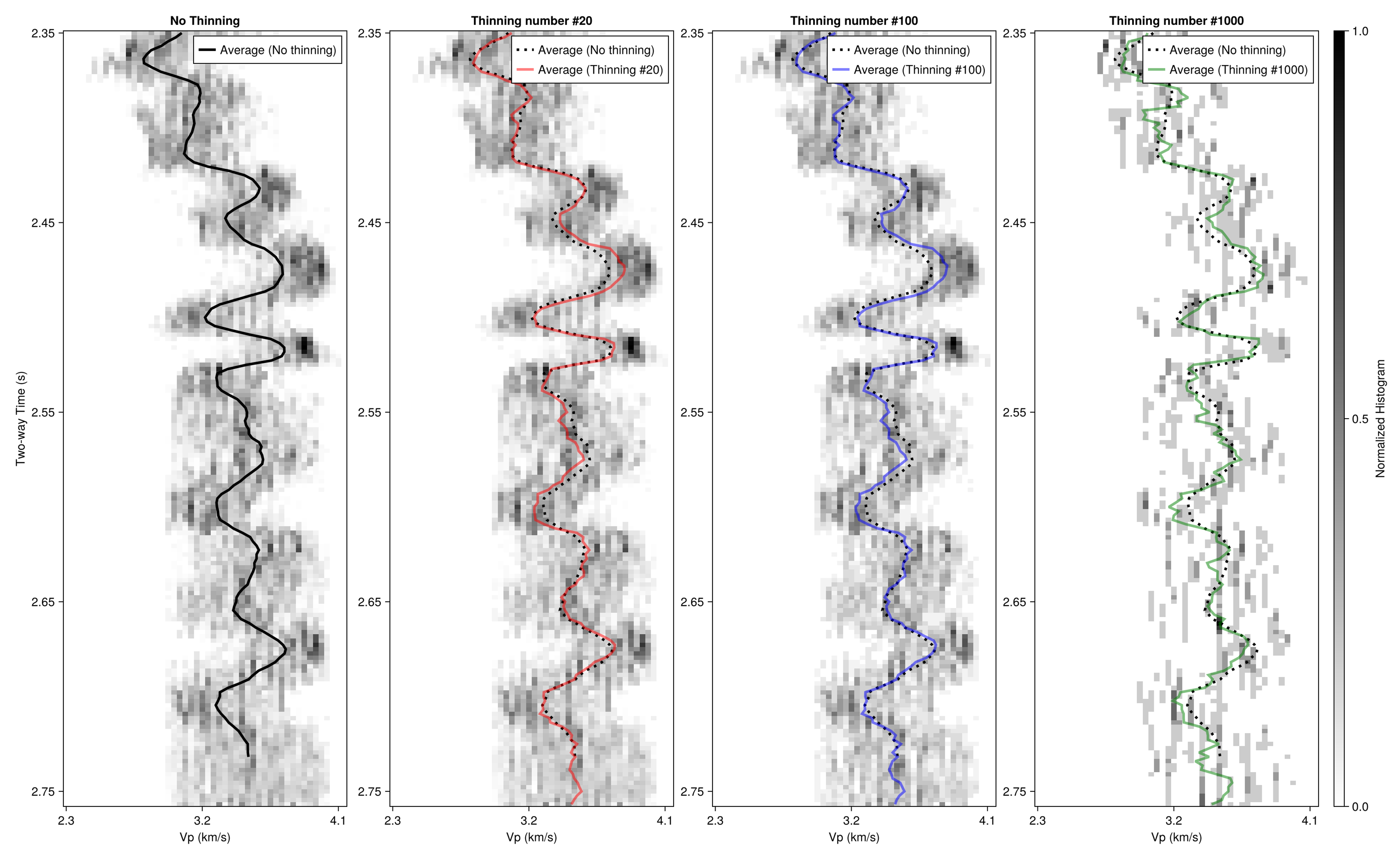
Fig. 10.
Effects of thinning on the posterior distribution derived from a Markov chain of 10,000 iterations. The background shows the normalized histograms of the estimated P-wave velocity (Vp). The black line indicates the average without thinning, while the red, blue, and green lines correspond to thinning numbers of 20, 100, and 1000, respectively.
Table 1.
Root mean square comparison for average values
| RMS | Thinning #20 | Thinning #100 | Thinning #1000 |
| Chain length 50,000 | 0.018535193 | 0.09337511 | 0.6478018 |
| Chain length 10,000 | 1.1252854 | 1.1789033 | 1.7886984 |
Fig. 11은 희석수의 변동에 따른 사후 분포의 불확실성을 나타내기 위해 가늘게 하기를 적용하지 않은 사후 분포와의 오차를 분석한 그림이다. 희석수는 1,000까지 순차적으로 증가시켰다. 오차값으로는 평균 제곱근 오차(Root Mean Square; RMS, RMSE)를 사용하였으며, 가늘게 하기를 적용하지 않은 사후 분포와 적용한 사후 분포 사이의 평균 차이를 측정하였다. 체인 길이 50,000개를 사용한 경우는 파란색 선으로, 길이 10,000개를 사용한 경우는 붉은색 선으로 나타내었다. 희석수가 증가함에 따라 평균 제곱근 값이 선형적으로 증가하지 않는 것은 MCMC 체인의 특성상 가늘게 하기를 적용할 때 다른 구간에서 모델이 선택되기 때문임을 확인하였고, 각 분포의 전체적인 경향을 분석하기 위해 선형회귀를 활용한 직선 역시 각각 점선으로 나타내었다.
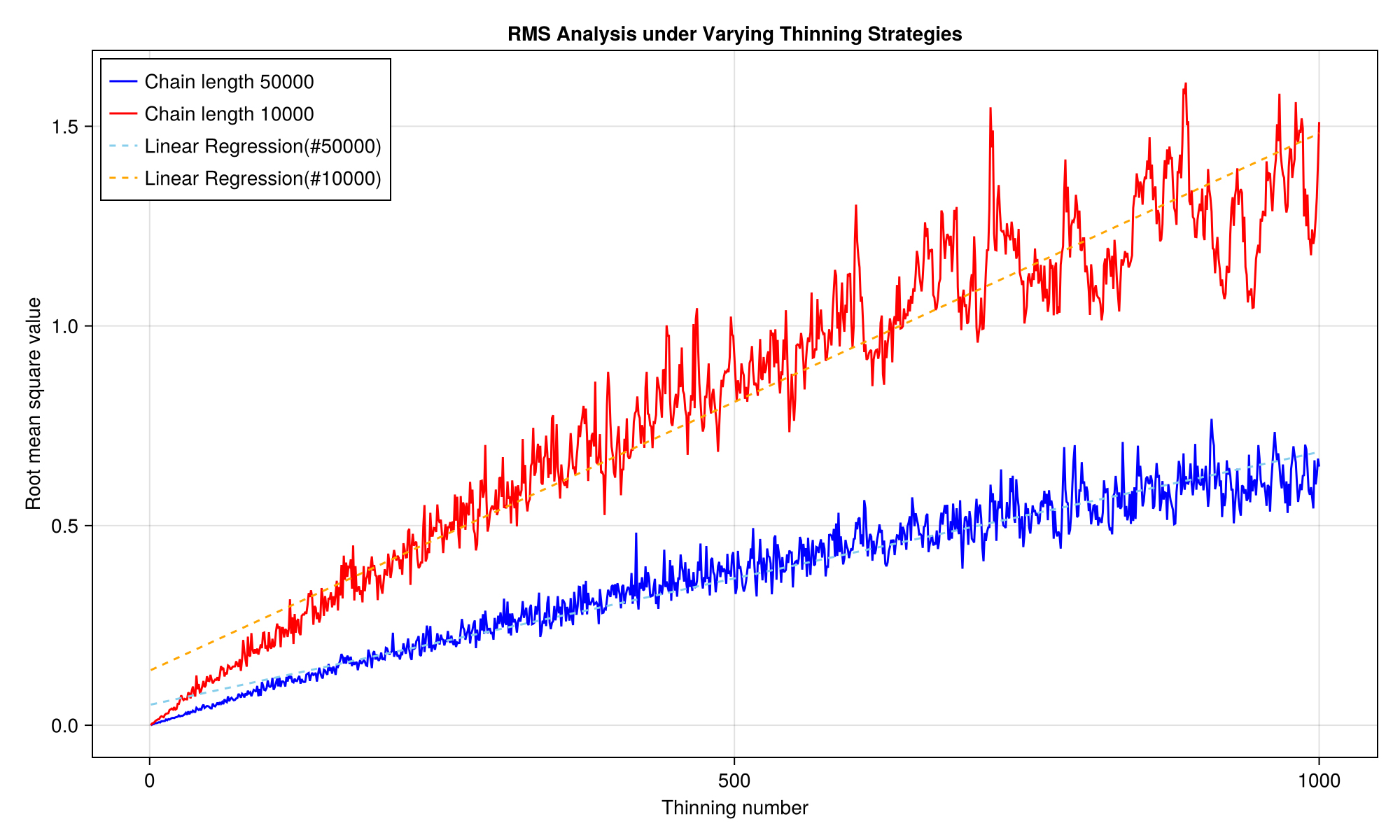
분석 결과 희석수를 증가시킴에 따라 평균 제곱근 오차가 커지지만, 체인 길이가 긴 경우는 완만하게 증가하는 것을 확인하였다. 그러나 체인 길이가 짧은 경우는 상대적으로 빠르게 오차가 증가한다. 특히 희석수가 크게 증가함에 따라 불확실성이 커지는 정도 역시 체인의 길이가 긴 경우보다 짧은 경우가 훨씬 크다는 점을 확인하였다. 각 희석수에 따른 저장용량은 희석수의 역수에 비례하여 감소한다. 따라서 10,000개의 체인을 저장할 수 있는 저장용량일 때, 가늘게하기를 적용하지 않고 10,000개의 체인을 분석하는 것보다 희석수를 5로 설정하여 50,000개의 체인 중 10,000개의 모델을 분석하는 것이 더욱 정확함을 알 수 있다. 이는 희석수가 5일 때 50,000개 체인에 대한 평균 제곱근 오차 값이 약 0.005수준으로 낮다는 점에서 가늘게 하기가 결과를 크게 왜곡하지 않음을 확인하였다.
저장용량의 측면에서, 본 분석에서 사용한 트레이스의 길이는 250개의 길이를 가지며 4바이트(4 bytes)를 기준으로 트레이스 하나당 1,000바이트(약 1 KB)를 저장한다. 길이가 50,000인 마르코프 체인을 저장하기 위해서는 50,000,000바이트(약 47.68 MB)가 필요하며, 40,400개의 트레이스를 저장하기 위해서는 약 1.84 TB의 용량이 필요하다. 그러나 가늘게 하기를 적용하면 희석수 20의 경우에는 약 94 GB, 희석수 100의 경우에는 18 GB 정도로 사후 분포를 왜곡하지 않으면서도 저장 용량을 획기적으로 줄일 수 있다. 이는 가늘게 하기를 적용하면 동일 저장 용량에서도 희석수배만큼의 추가적인 표본추출이 가능하다는 것을 의미하며, Fig. 7과 10, 11에서 비교할 수 있듯이 표본 추출 횟수가 많아지는 것은 사후 분포 근사를 비슷하게 할 수 있기 때문에 역산의 정확성을 증가시킬 수 있다. 또한 Fig. 11에서 확인할 수 있듯이 가늘게 하기를 적용한 만큼 추가적인 추출을 통해 마르코프 체인의 길이를 늘이는 것은 불확실성 측면에서도 장점을 가진다고 볼 수 있다. 특히 그래픽 처리장치(Graphic Processing Unit, GPU)를 활용하여 추계학적 역산의 연산 속도를 획기적으로 향상시킬 수 있다는 점이 알려지면서(Moon et al., 2024) 표본 추출 횟수 증가의 부담이 줄었기 때문에 대용량 자료에 가늘게 하기를 적용하는 것은 정확한 역산 결과에 기여한다.
결 론
본 연구에서는 탄성파 탐사 자료의 3차원 추계학적 역산의 사후 분포를 분석함에 있어 가늘게 하기를 적용하고 그 효용성을 입증하였다. 서로 길이가 다른 마르코프 체인에서의 가늘게 하기를 비교하여 마르코프 체인이 충분히 추정하고자 하는 분포에 근사되어 있다면 가늘게 하기를 적용하더라도 사후 분포를 거의 왜곡하지 않음을 오차의 정량적인 분석을 통해 확인하였다. 이 과정에서 저장 용량의 부담을 획기적으로 낮출 뿐만 아니라 자기상관계수 또한 감소시켜 마르코프 체인의 독립성 역시 증가시킬 수 있었다. 또한 추계학적 역산의 연산 속도 자체는 그래픽 처리장치(GPU)등의 병렬 연산을 통하여 기하급수적인 증가가 가능하기 때문에 동일 저장 용량에서는 최대한 가늘게 하기를 적용하여 마르코프 체인의 독립성을 증가시키며 반복 횟수를 늘리는 것이 정확한 분석에 도움이 된다는 점 역시 확인하였다.
