

서 론
선행연구 고찰
합성 물리검층 자료 생성 사례
저류층 물성 추정 사례
연구방법
고해상도 모델링을 위한 입출력자료의 변환
알고리듬 특성별 입력자료의 배열 크기 조정
고해상도 비율에 따른 학습자료의 구성
연구결과
자료 취득 및 선별
자료분석
입력자료 조합에 대한 민감도 분석
딥러닝 모델 설계
연구 결과분석
결 론
서 론
E&P 산업은 현장규모에 비해 매우 한정된 데이터로 저류층 평가를 수행하는 특성상 불확실성이 크고 이로 인한 리스크가 높기 때문에 신속하고도 정확한 의사결정이 요구된다. 따라서 고품질 광구 빅데이터를 확보하는 것이 중요하며 이는 저류층 평가의 신뢰도를 높인다(Min et al., 2020). 그러나 물리검층 및 코어자료와 같은 하드 자료(hard data)의 경우 충분한 표본을 샘플링하기에는 기업의 비용 부담이 크다는 현실적인 어려움이 있다. 육상 광구 유정 하나의 시추 비용은 4.9~8.3백만 달러에 이르기 때문이다(EIA, 2016). 뿐만 아니라 장비 손상, 불량한 검층 조건 등 다양한 이유로 인해 물리검층 자료가 부분적으로 누락되는 일이 빈번하다(Salehi et al., 2017). 이에 기확보한 표본으로부터 시추공의 미지구간에 대한 물리검층 결과를 추론해야 하는 문제에 직면하게 되었으며 최근 딥러닝(deep learning)이 발달하면서 신경망(neural network)과 같은 AI 기술의 활용사례가 증가하고 있다(Park, 2021). 특히, 딥러닝은 비선형 관계 추출에 탁월하다는 측면에서 저류층 인자(reservoir parameters) 추정에 유용하여 물리검층 분야 연구에서 널리 활용되고 있다(Maiti et al., 2007; Ji et al., 2021; Park et al., 2021).
물리검층 자료로부터 저류층 인자를 추정하는 딥러닝 연구는 크게 합성 물리검층 자료(synthetic logs)의 생성(음파 검층, 밀도 검층 등)과 저류층 물성(reservoir properties) 추정(공극률, 포화도 등)으로 나눌 수 있다. 상기 구분은 딥러닝의 출력 유형이 다를 뿐 입력 유형은 물리검층 자료로 동일하다. 이와 관련하여 선행연구들은 저류층 인자의 출력 해상도를 물리검층의 입력 해상도와 동일하게 설정하여 왔다. 예를 들어, 물리검층의 수직 해상도는 보통 0.15 m(약 0.5 ft) 이므로(La Croix et al., 2019; Dong et al., 2020), 물리검층 자료를 활용하여 공극률을 예측한 경우 예측한 공극률 역시 0.15 m 간격으로 도출된다. 요컨대, 일반적인 물리검층 해상도로는 0.03 m(약 0.1 ft) 간격의 해상도를 갖는 코어자료와 직접적인 비교가 어렵다는 한계가 있을 뿐만 아니라, 때때로 충분한 정보를 제공하지 못하여 저류층 해석에 큰 오차를 야기한다. 일례로, 국내 동해 울릉분지에 위치한 가스하이드레이트 부존층(Ulleung basin gas hydrate, UBGH)의 경우 가스하이드레이트가 두꺼운 층을 이루는 형태가 아닌 퇴적층 내에 얇게 산재된 형태의 분포양상을 보이기 때문에 가스하이드레이트 매장량이 과대평가 혹은 과소평가 될 수 있는 우려가 있다(Kim, 2012). Horozal et al.(2015)은 코어 이미지를 바탕으로 가스하이드레이트가 사질층(muddy sand) 또는 머드층(sandy mud)에 0.5 m보다 얇은 두께로 존재함을 확인하였다. Kim and Lee(2022)는 UBGH2-6 시추공에서 해저면 기준 140.5 m에서 153.8 m 사이 사질층에 가스하이드레이트가 분포하며, 두께 0.1–0.6 m의 사질층과 머드층이 교차하는 형태로 존재함을 확인하였다. 따라서 보다 조밀한 고해상도의 저류층 물성 자료를 취득하거나 계산할 필요가 있다.
이에 본 연구는 딥러닝 기반 해석을 통해 물리검층 자료로부터 합성 물리검층 자료를 고해상도로 추정하여 향후 고해상도 저류층 물성 평가에 활용할 수 있는 방법을 제안한다. 대표적인 3가지 유형의 딥러닝(심층신경망, 합성곱신경망, 장단기메모리) 모델을 노르웨이 Volve 유전에 적용하여 타 물리검층 자료로부터 음파 검층자료를 고해상도로 생성한 결과를 제시한다.
선행연구 고찰
물리검층 분야에서 저류층 인자 추정과 관련된 선행연구를 조사하였으며, 다음과 같이 두 가지 유형에 따라 선행연구를 분류하였다. 첫째, 물리검층 자료로부터 합성 물리검층 자료를 생성한 경우, 둘째, 물리검층 자료로부터 저류층 물성을 추정한 경우이다. 본 연구는 기계학습(machine learning) 중에서도 신경망 알고리듬으로 지도학습법을 적용한 사례로 한정하여 조사를 진행하였고, 그 중 대표적인 연구사례를 Table 1과 Table 2에 정리하였다. 표는 저자명과 출판연도, 신경망 알고리듬, 입력자료, 출력자료, 현장 순으로 나타냈으며, 표에서 사용하고 있는 약어 및 기호들은 선행연구 원문들의 표기법을 준수하여 본 논문의 Nomenclature에 정리하였다. 조사 결과, 선행연구들은 모두 입력자료와 동일한 해상도로 출력자료를 예측하였으며 물리검층 분야에서 입력자료보다 높은 해상도로 출력한 연구사례는 아직 없음으로 확인하였다.
합성 물리검층 자료 생성 사례
물리검층은 지층의 물리적 특성을 측정하기 위해 그 종류가 다양하나 비용 절감, 장비 손상, 불량한 검층 조건 등의 이유로 시추공에서 특정 물리검층 자료가 부재한 경우가 발생한다. 이에 다양한 연구에서 가용한 물리검층 자료를 합성하여 부재한 특정 물리검층 자료를 추정하여 왔다(Rolon et al., 2009; Salehi et al., 2017; Alimohammadi et al., 2020; Kim et al., 2020). 음파 검층, 밀도 검층, 비저항 검층, 중성자 검층 등을 비롯하여 다양한 종류의 물리검층 자료가 합성 물리검층 자료 생성의 대상이 되었다. 일례로, Kim et al.(2020)은 유정의 위도, 경도, 심도, 음파검층을 입력자료로 하는 DNN을 사용하여 밀도검층을 생성하면서, 학습자료 구성 시 도메인지식을 활용한 유정선별을 강조하였다. 또한 음파 검층을 추정한 연구사례가 많았는데, 이는 음파 검층이 물리검층 중에서도 상대적으로 높은 측정 비용으로 인해 제한된 구간에서만 수행되는 경향이 있기 때문이다(Onalo et al., 2020).
Table 1은 신경망을 활용하여 물리검층 자료로부터 음파 검층을 합성한 4가지 대표사례이다. Salehi et al.(2017)은 은닉층의 개수가 세 개인 심층신경망(deep neural network, DNN)을, Onalo et al.(2018)은 은닉층의 개수가 한 개인 인공신경망(artificial neural network, ANN)을, Zhang et al. (2018)은 출력자료를 다시 입력자료로 추가하여 사용하도록 설계된 계단식 장단기메모리(cascaded long short-term memory, cascaded LSTM)를, Pham et al.(2020)은 셀 내에서 합성곱 연산을 수행하는 양방향 합성곱 장단기메모리(bidirectional convolutional LSTM)를 적용하였다. 이처럼 각 연구마다 적용한 신경망 알고리듬은 하나의 기법에 치중되지 않고 다양한 것으로 나타났다. 상기 연구들은 현장에서 취득한 물리검층 자료를 바탕으로 연구를 수행하였으며, 음파 검층을 생성하기 위해 각 현장별로 가용한 물리검층 자료들을 입력자료로 활용하였다. 이는 실제 현장 자료를 활용하는 만큼, 가용한 물리검층의 종류가 제한적인 동시에 서로 다른 현장 지질특성을 고려하였기 때문으로 사료된다.
Table 1.
Literature review for the generation of synthetic sonic logs using neural networks
| Authors (year) | Method | Inputs | Outputs | Field |
| Salehi et al. (2017) | DNN | Rxo, RHOB, NPHI | DT | Mansouri, Iran |
| Onalo et al. (2018) | ANN | GR, RHOB, Vsh | DTCO, DTSM | West Africa Offshore |
| Zhang et al. (2018) | Cascaded LSTM | ΔRT, CALI, SP, GR | DTb, DTh, RHOB | Daqing Oil Field, China |
| Pham et al. (2020) | Bidirectional convolutional LSTM | GR, RHOB, NPHI | DT | United Kingdom Continental Shelf |
저류층 물성 추정 사례
물리검층 자료는 일반적으로 공극률, 수포화도 등 저류층 물성의 추정을 위한 기초 자료로 활용된다. 저류층 물성은 석유, 천연가스, 가스하이드레이트와 같은 지하자원의 매장량 평가에 있어 핵심 요소이며 생산량 예측을 위한 저류층 모델링 및 시뮬레이션 수행의 근간이 된다. 그러나 현장에서 저류층 물성을 직접 취득하기란 쉽지 않기 때문에 일반적으로 물리검층 자료와의 상관관계 분석을 통하여 공극률, 포화도, 유체투과율과 같은 저류층 물성을 간접적으로 예측하고 소수의 코어분석 결과와 비교 분석하게 된다. 공극률 추정의 경우 밀도 검층, 중성자 검층, 음파 검층을 활용한 경험식이 대표적이며 셰일 함량과 같은 지층 조건에 따라 다양한 경험식들이 제안되었다(Wyllie et al., 1958; Schlumberger, 1967; Gaymard and Poupon, 1968; Bateman, 1986; Lee and Collett, 2011). 경험식들은 복잡한 지질학적 구조를 보이는 경우 정확도가 현저히 감소하는 한계가 있다. 이에 물리검층 분야에서는 비선형 복합관계를 보이는 저류층에서 물리검층 자료로부터 저류층 물성을 추정하기 위해 신경망 기법을 도입한 사례가 다수 존재한다.
Table 2는 신경망을 활용하여 물리검층 자료로부터 공극률과 수포화도 또는 가스하이드레이트 포화도를 추정한 4가지 대표사례이다(Mahmoudi and Mahmoudi, 2014; Saputro et al., 2016; Mukherjee and Sain, 2019; Miah et al., 2020). 다양한 신경망 알고리듬을 적용한 합성 물리검층 자료 생성 연구와 달리 저류층 물성 추정 연구들은 주로 인공신경망 또는 심층신경망을 적용하는 것으로 나타났다. 상기 연구들은 Saputro et al.(2016)을 제외하고는 현장에서 취득한 물리검층 자료 또는 코어자료를 바탕으로 연구를 수행하였으며, 마찬가지로 각 현장별로 가용한 물리검층 자료들을 입력자료로 활용하였다.
Table 2.
Literature review for the estimation of reservoir properties using neural networks
| Authors (year) | Method | Inputs | Outputs | Field |
| Mahmoudi and Mahmoudi (2014) | ANN | CALI, DT, NEUT, RHOB, EPHI | ϕ, Sw | Oil Field, Iran |
| Saputro et al. (2016) | DNN | GR, DT | ϕ | N/A |
| Mukherjee and Sain (2019) | DNN | RT, RHOB, vp, DPHI | ϕ, Sgh | NGHP Exp-02, India |
| Miah et al. (2020) | DNN | DT, GR, NPHI, PEF, RHOB, RT | Sw | Bengal Basin, India |
Table 1과 2에 정리한 선행연구를 바탕으로 본 연구는 딥러닝 기반 해석을 통해 물리검층 자료로부터 저류층 물성을 고해상도로 평가할 수 있는 방법론을 개발하는 것을 최종 연구목표로 한다. 우선 본 논문은 합성 물리검층 자료의 고해상도 생성에 초점을 맞추었다. 고해상도 자료를 생성하기 위해 3가지 유형의 딥러닝 알고리듬(심층신경망, 합성곱신경망, 장단기메모리)을 적용하고 알고리듬들의 성능을 평가한다. 합성 물리검층 자료에 기반한 저류층 물성 추정 및 코어 자료와의 매칭을 통한 추정치 보정은 후속 연구에서 다룰 계획임을 밝힌다.
연구방법
본 연구에서 제안하는 딥러닝 기반 고해상도 물리검층 자료 생성 모델의 원리는 다음과 같다. 딥러닝 알고리듬의 입력자료인 물리검층의 원시해상도보다 M배 높은 해상도를 갖는 합성 물리검층 자료를 출력한다. Fig. 1은 본 연구의 개념도를 나타낸다. 예를 들면, 0.15 m 간격으로 측정된 총 4가지 물리검층 자료(NPHI, RHOB, GR, RT)를 입력자료로 사용하여 5배의 고해상도 DT를 생성한다면 딥러닝을 적용한 합성 DT의 간격은 0.03 m이다. 상기 사례는 출력 인자가 특정 물리검층 자료이므로 Table 1처럼 합성 물리검층 자료의 생성에 해당한다.
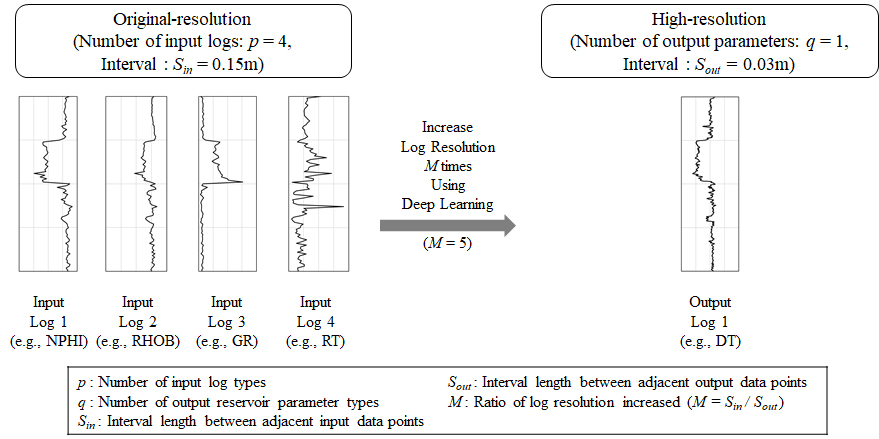
고해상도 모델링을 위한 입출력자료의 변환
본 연구에서 제안하는 고해상도 저류층 인자 평가 모델에서 주목할 점은 입출력자료의 구성이다. 이에 본 연구 모델을 전형적인 저류층 인자 추정 모델과 비교하며 설명하기로 한다. 우선 전형적인 모델의 경우, 입출력자료의 해상도가 동일하므로 총 N개의 지점에서 측정한 p종류의 물리검층 자료를 입력자료로 사용하여 q종류의 저류층 인자를 출력한다. 따라서 입력자료는 (N, p)의 배열 크기를, 출력자료는 (N, q)의 배열 크기를 가진다(Fig. 2).
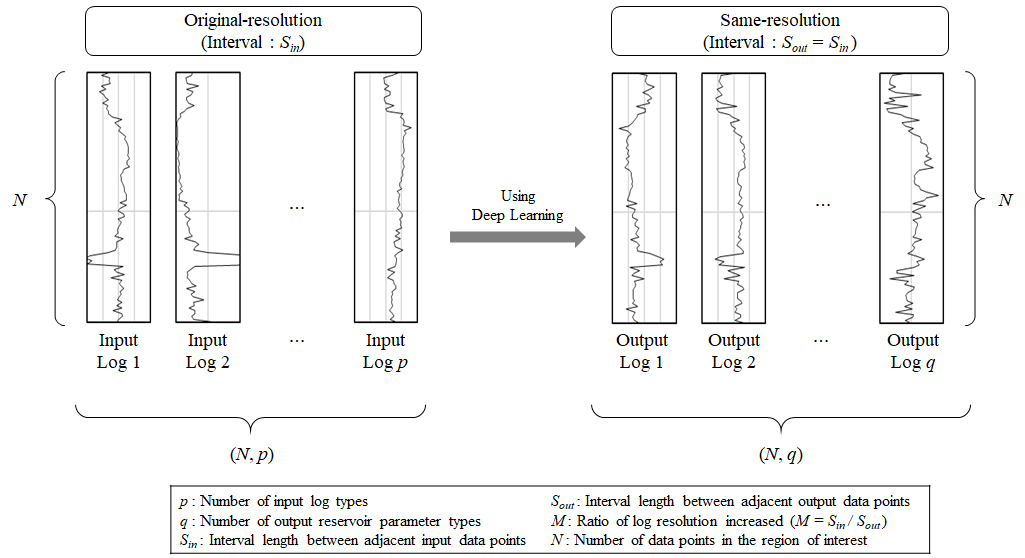
본 연구 모델의 경우, 입력 원시해상도 대비 M배 높은 해상도의 자료를 출력하므로 입력자료의 배열 크기는 (N, p)로 동일하나 출력자료의 배열 크기는 (N, q)에서 (M(N–1)+1, q)로 증가한다(Fig. 3).
식 (1)에서 식 (4)에 해당하는 상기 입출력자료는 주어진 자료의 크기를 배열로 나타냈을 뿐, 실제 신경망 모델에 바로 사용되는 형태가 아니므로 신경망 알고리듬 특성에 따라 배열 크기를 조정하는 과정을 거친다.
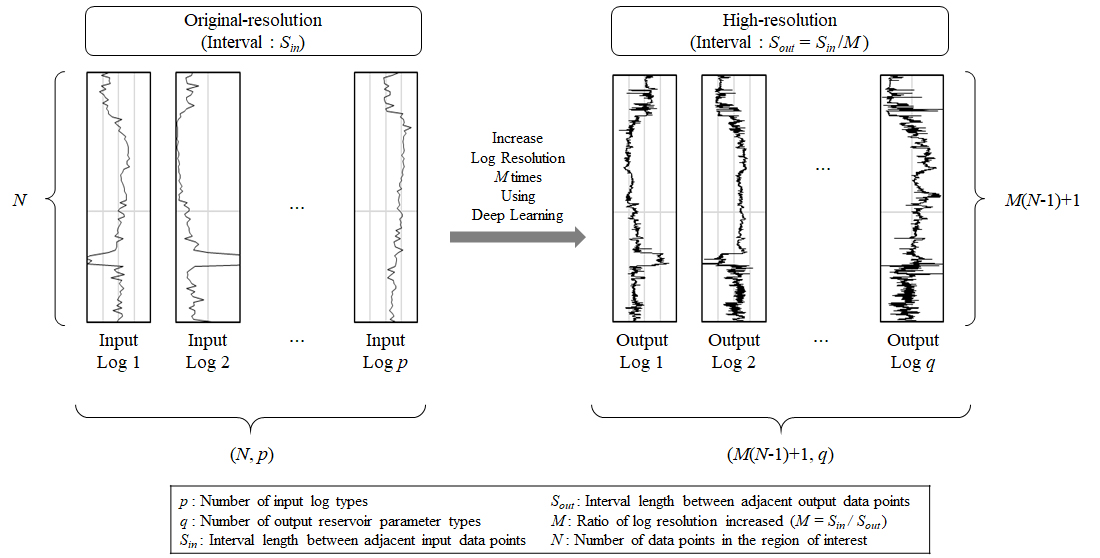
Fig. 4와 Fig. 5는 입출력자료를 점으로 표현한 것으로 각각 전형적인 모델과 제안하는 고해상도 모델을 비교하여 나타낸다. 검은색 점은 측정 자료를, 흰색 점은 측정되지 않은 자료를, 빗금 친 점은 해당 모델을 적용하여 추정한 자료를 의미한다. 전형적인 모델의 경우(Fig. 4), 회색박스와 같이 i번째의 입력자료 쌍(pair)으로부터 i번째의 출력자료 쌍을 추정한다. 따라서 하나의 입출력자료 쌍에 대한 배열의 크기는 각각 (1, p), (1, q)이고, 구성할 수 있는 입출력자료 쌍은 총 N개이므로 전체 입출력자료 쌍에 대한 배열의 크기는 각각 (N, p), (N, q)이다. 즉, 전형적인 모델의 입출력자료 배열의 크기는 각각 식 (1), 식 (2)와 동일하다.
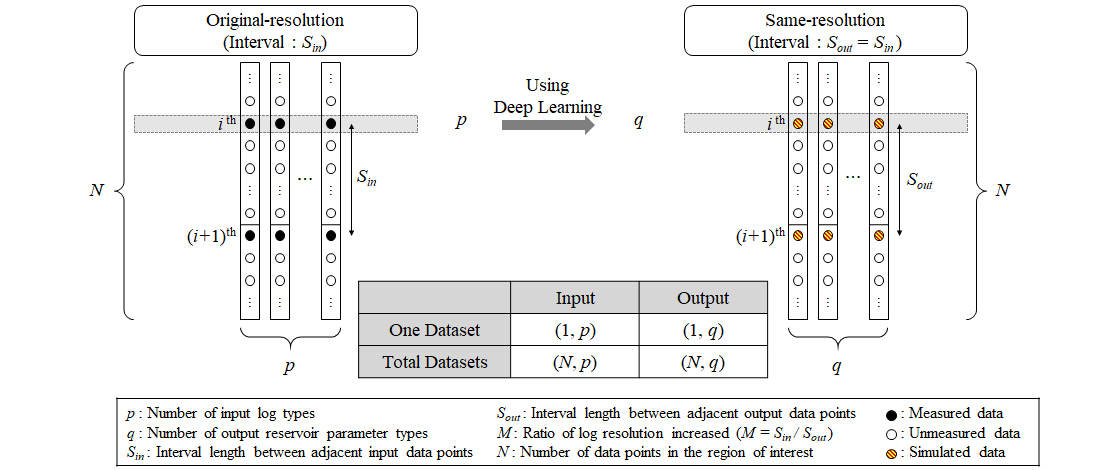
반면, 제안하는 고해상도 모델의 경우(Fig. 5), i번째와 i+1번째의 입력자료 쌍(pair)으로부터 M(i–1)+1번째부터 Mi+1번째까지의 출력자료 쌍을 추정하도록 설계하였다. 이때, i번째 입력자료 쌍은 M(i–1)+1번째 출력자료 쌍과, i+1번째 입력자료 쌍은 Mi+1번째 출력자료 쌍에 대응한다. 따라서 하나의 입출력자료 쌍에 대한 배열의 크기는 각각 (1, 2p), (1, (M+1)q)이고, 구성할 수 있는 입출력자료 쌍은 총 N–1개이므로 전체 입출력자료 쌍에 대한 배열의 크기는 각각 (N–1, 2p), (N–1, (M+1)q)이다. 즉, 식 (5)와 식 (6)은 각각 식 (3), 식 (4)에서 고해상도 변환 과정을 적용한 결과이다.
한편, Mi+1번째 출력자료 쌍은 i번째와 i+1번째의 입력자료 쌍으로부터 예측한 자료 중 마지막 출력 쌍에 해당하나 이는 i+1번째와 i+2번째의 입력자료 쌍으로부터 예측한 자료 중 처음 출력 쌍에 해당하기도 한다. 즉, 본 연구 모델은 Mi+1번째 출력자료 쌍을 겹쳐서 추정하며 알고리듬의 손실함수 계산 시 모두 포함한다. 그러나 최종 예측 결과로는 겹치는 Mi+1번째 출력자료는 둘 중 하나만을 사용한다. 다시 말해, 최종 예측 결과로서는 i+1번째와 i+2번째의 입력자료로부터 예측한 자료 중 처음 Mi+1번째 출력만을 사용하고 i번째와 i+1번째의 입력자료로부터 예측한 자료 중 마지막 Mi+1번째 출력은 배제한다. 다만, 마지막 입력자료 쌍 i = N–1일 때는 마지막 Mi+1번째 출력을 유일하게 포함한다. 이는 알고리듬의 손실함수 계산과는 무관하다.
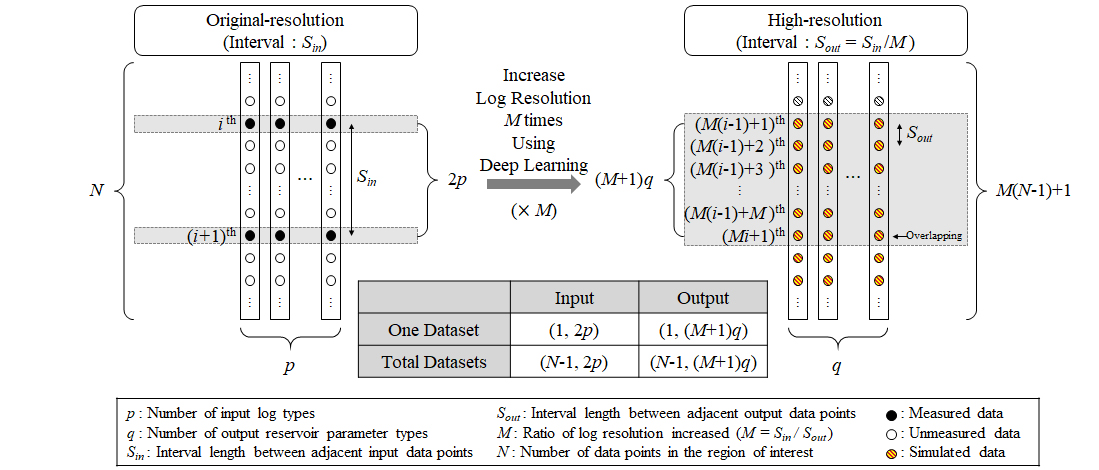
정리하면, M배의 해상도로 합성 검층자료를 생성할 때 알고리듬에 직접 사용되는 입출력자료의 배열 크기는 각각 식 (5), 식 (6)과 같다. 평가가 중복되는 점은 손실함수 계산시 포함한다. 그러나 최종 예측 결과에 나타내는 입출력자료의 배열 크기는 각각 식 (3), 식 (4)와 같으며 중복지점은 하나만을 사용한다. 고해상도 변환 과정을 완료하고 나면 알고리듬 특성에 따라 입력자료의 배열 크기를 조정하는 과정을 수행한다.
알고리듬 특성별 입력자료의 배열 크기 조정
전형적인 모델의 경우, 입력자료의 배열 크기는 식 (1)과 같으며 알고리듬 특성에 따라 배열 크기를 조정한다. DNN의 경우 N × p 크기의 1차원 벡터로 입력자료를 구성하며, CNN의 경우 입력을 이미지로 처리하기 위해 입력자료를 3차원 배열로 구성하므로 (lwN, p, 1)로, LSTM의 경우 입력을 순차 자료로 처리하기 위해 입력자료를 2차원 배열로 구성하므로 (lwN, p)로 조정한다. 이때, CNN과 LSTM의 경우 lw는 윈도우 길이(window length)로 CNN의 경우 이미지 행 개수를, LSTM의 경우 시퀀스 길이를 의미한다. 다만, 입력자료 자체가 1차원인 경우 lw는 사실상 1이다. CNN의 3번째 요소는 이미지가 RGB 컬러인 경우 3으로 설정할 수 있으나, 본 연구에서는 그레이 스케일과 동일하게 1로 설정한다. 입력자료와 달리 출력자료는 신경망 알고리듬 특성에 따라 배열 크기의 제약을 받지 않으며, 일반적으로 출력자료 배열의 크기는 DNN, CNN, LSTM 모두 N × q이다. 본 연구에서 제안하는 고해상도 모델의 경우도 이와 유사하게 입력자료의 배열 크기를 조정한다.
Fig. 6은 고해상도 모델에서 알고리듬별(DNN, CNN, LSTM) 입력자료의 크기를 설명하기 위해 나타낸 예시이다. 배열 크기를 조정하기 전 입력자료의 배열 크기는 식 (6)과 같으며 DNN의 경우 입력자료를 1차원 벡터인 2(N–1)p로, CNN의 경우 입력자료를 3차원 배열 (2(N–1), p, 1)로, LSTM의 경우 입력자료를 2차원 배열 (2(N–1), p)로 조정한다. 이는 lw를 2로 설정한 것과 동치이다. 다만, 출력자료 배열의 크기는 후처리(postprocessing)를 고려하여 편의상 DNN, CNN, LSTM 모두 2차원 배열 (N–1, (M+1)q)로 구성한다. 각 딥러닝 알고리듬별 입출력 자료의 배열 크기를 요약하면 Table 3과 같다.
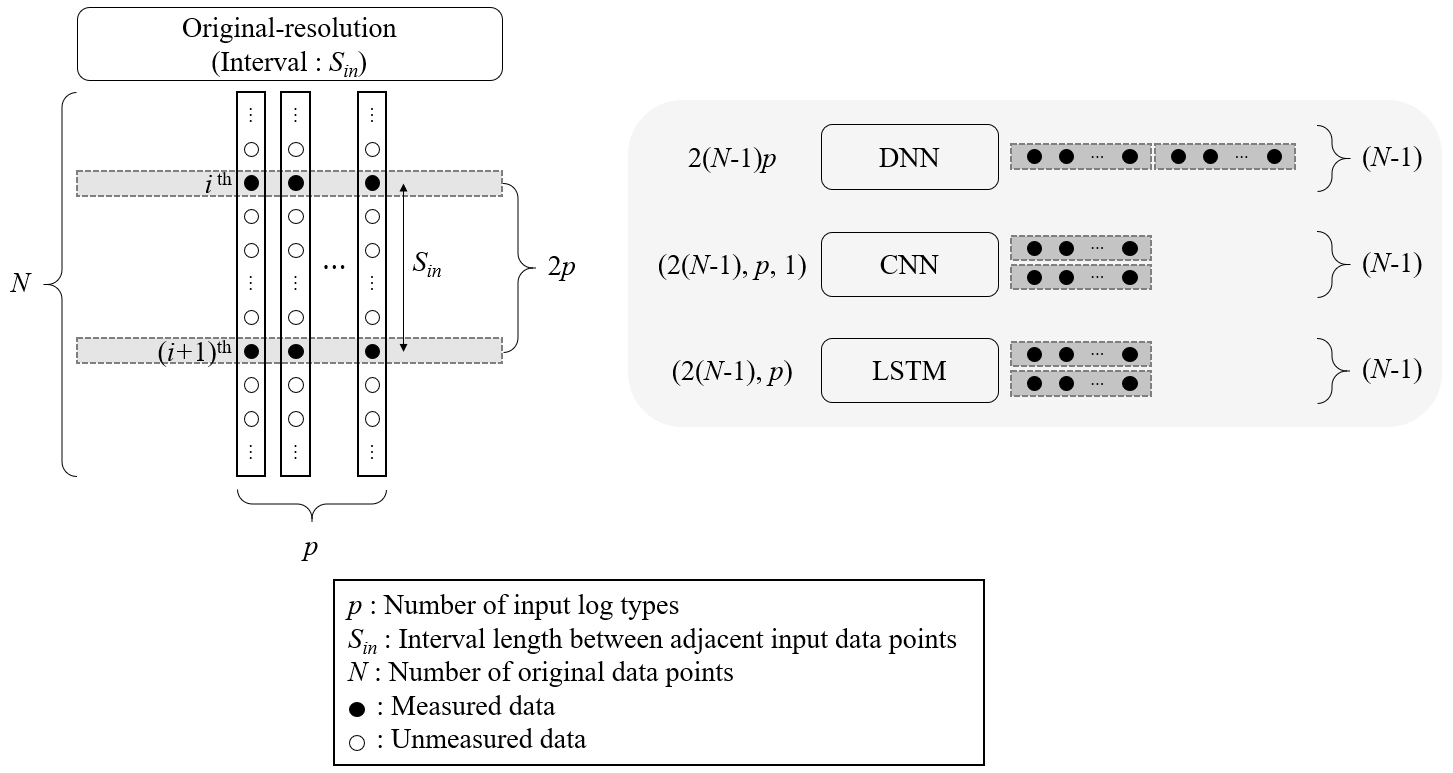
Table 3.
Comparison of input/output array size for the conventional and proposed high-resolution estimation models
고해상도 비율에 따른 학습자료의 구성
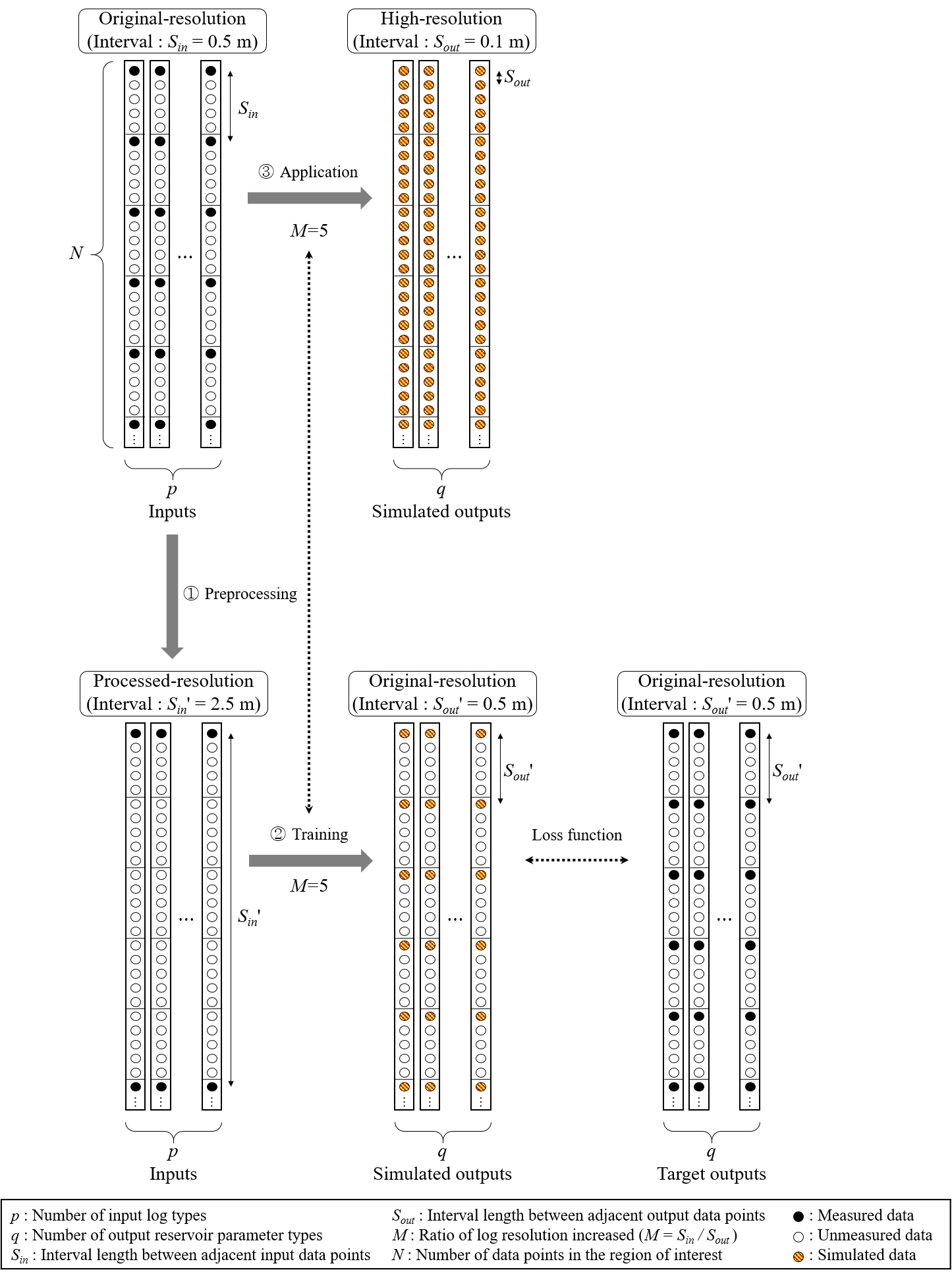
제안하는 딥러닝 모델은 지도학습법에 따라 학습을 진행하므로 학습에 사용할 정답 자료가 참조 자료(reference data)로서 존재하여야 한다. 이 연구의 경우 출력 저류층 인자가 고해상도 합성 물리검층 자료에 해당하므로 정답 자료는 원시 물리검층 자료가 되며, 정답 물리검층 자료는 입력자료와 동일한 해상도를 보인다. 이에 입력자료를 원시해상도로 바로 사용하지 않고 출력하고자 하는 고해상도 비율 M에 따라 입력자료의 원시해상도를 1/M로 가공하여 딥러닝 학습을 진행한다. 학습을 완료한 딥러닝 모델에 원시해상도의 물리검층 자료를 입력하면 목표한 고해상도의 합성 물리검층 자료를 생성할 수 있다.
예를 들어, Fig. 7과 같이 입력자료의 원시해상도(Sin = 0.5 m) 보다 5배 조밀한 해상도로 출력할 때(Sout = 0.1 m), 정답 자료는 Sout만큼의 해상도로 존재하지 않아 지도학습이 불가능하다. 이때, 입력자료의 원시해상도(Sin = 0.5 m)를 인위적으로 일부 자료를 제거하여 1/5로 낮춘다(Sin' = 2.5 m). 가공한 입력자료(Sin' = 2.5 m)는 딥러닝 모델을 통해 5배 해상도의 출력자료(Sout' = 0.5 m)를 추정하게 되며 이는 정답 자료를 통해 학습이 이뤄진다. 딥러닝 모델이 학습을 완료하고 나면 Sin = 0.5 m의 입력자료로 Sout = 0.1 m의 출력자료를 예측할 수 있다. 즉, 원시해상도 보다 낮은 해상도로 가공한 입력자료로 원시해상도의 출력자료를 재현해내도록 딥러닝 모델을 학습하고 동일한 모델을 다시 적용하여 고해상도 출력자료를 추정한다.
신경망의 학습(training), 검증(validation), 시험(test) 단계를 수행하고 나면 각 단계별 학습성능 기준에 따라 딥러닝 기반 예측 모델을 평가한다. 이때 학습성능 기준은 손실함수를 따르며 기준을 만족하지 않는 경우 딥러닝 알고리듬의 초매개변수(예: 은닉층 수, 노드 수 등)를 조정하여 재설계하며, 기준을 만족하는 경우 학습을 종료한다. 학습을 완료하고 난 모델은 학습, 검증, 시험 단계에 사용하지 않은 다른 유정의 물리검층 자료에 대하여 적용(application) 가능하다.
본 연구는 손실함수 외에도 각 딥러닝 알고리듬의 학습성능 평가에 유용한 성능 지표들로 MAPE(mean absolute percentage error), RMSE(root mean squared error), R (Pearson correlation coefficient), R2(Coefficient of determination)를 계산하여 알고리듬 성능을 평가한다.
연구결과
자료 취득 및 선별
개발한 모델을 노르웨이 Volve 유전에 적용하여 타 물리검층 자료로부터 DT 물리검층 자료를 고해상도로 추정하였다. 물리검층 자료의 연속성을 고려하였을 때 3가지 유형의 딥러닝 알고리듬(DNN, CNN, LSTM)을 모두 적용한 결과를 비교 분석하였다.
노르웨이의 국영 석유회사 Equinor는 2018년 Volve 유전 현장자료를 비영리 연구목적으로 대중에 공개하였다. 이는 E&P 산업에서 세계 최초로 저류층 빅데이터를 공개한 사례로 최근 다양한 연구에 활용되고 있다(Kwon et al., 2021). Volve 유전은 Fig. 8과 같이 해저 이산화탄소 지중저장(Carbon Capture and Storage, CCS)로 유명한 북해 Sleipner 가스전 인근에 위치하고 있다. Volve 유전은 1993년 처음 발견된 이후 2005년 개발 및 운영 계획이 승인되었다. Volve 유전은 쥐라기 중기 퇴적된 Hugin Formation 사암층(sandstone layer)으로 해수면 기준 2,700–3,100 m 심도에 위치하고 있으며, 3개의 탐사정과 21개의 관측정, 생산정, 주입정이 8년간 운영되었다. 2008년–2016년 총 8년 동안 총 63 MMSTB의 석유가스를 생산하였으며 이는 매장량 대비 54%의 회수율에 해당한다.
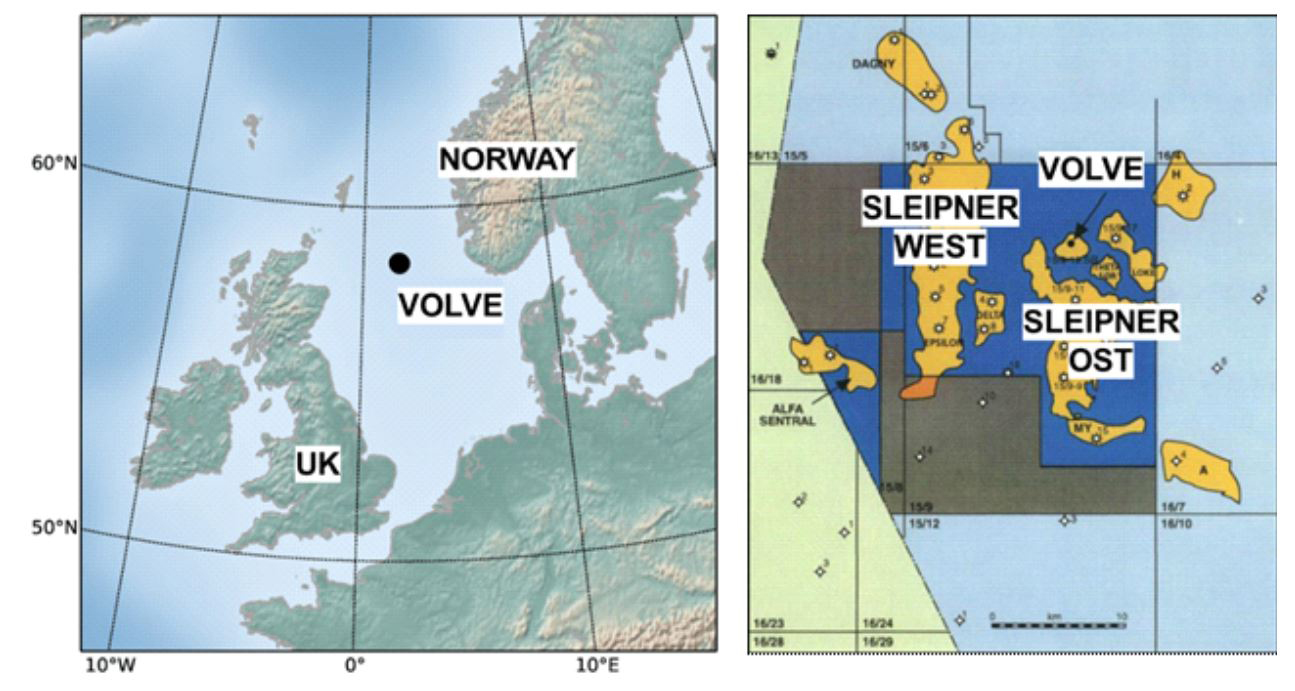
Fig. 8.
Location of the Volve oil field and the Sleipner gas field (Da Costa Filho et al., 2018; Statoil, 1993).
한편, 공개된 Volve 유전의 현장자료는 유정별로 다수의 물리검층 자료를 포함하고 있는 반면, 코어자료는 극히 일부에 불과하다(Table 4). 따라서 본 사례 연구에서는 물리검층 자료만을 활용하여 고해상도 물리검층 자료를 합성하였다. 물리검층 자료는 LAS(Log ASCII Standard) 또는 DLIS(Digital Log Interchange Standard) 형식으로 제공되었다. DLIS 형식은 상용 소프트웨어만을 지원하므로 LAS 형식의 물리검층 자료만을 고려하였을 때, 일부 유정에서만 DT가 측정된 것을 확인하였다. 이에 본 사례 연구는 제안하는 방법론의 신뢰도를 검증하기 위하여 DT가 확보된 4개의 유정 F-1, F-1A, F-1B, F-11A를 선별하였다. 본 딥러닝 모델은 지도학습법을 따르므로, 4개 유정을 각각 딥러닝 모델의 학습, 검증, 시험, 적용에 활용하여 딥러닝 모델의 성능을 평가하였다.
Table 4.
List of available well data from the Volve oil field
자료분석
Fig. 9는 DT의 고해상도 추정에 사용한 4개 유정(F-1A, F-1B, F-1, F-11A)의 위치를 나타낸다. F-1A, F-1B, F-1은 동일한 위치를 보이며 F-11A는 이와 떨어져 있다. F-1A와 F-1B는 F-1에서 2차 시추(side-tracking)된 유정이기 때문에 좌표상 동일한 위치를 보이나 저류층 심도(2,700–3,100 m) 부근부터 다른 경로로 시추된 것을 확인하였다(Fig. 10). 마찬가지로 F-11A는 F-11에서 2차 시추된 유정에 해당한다.
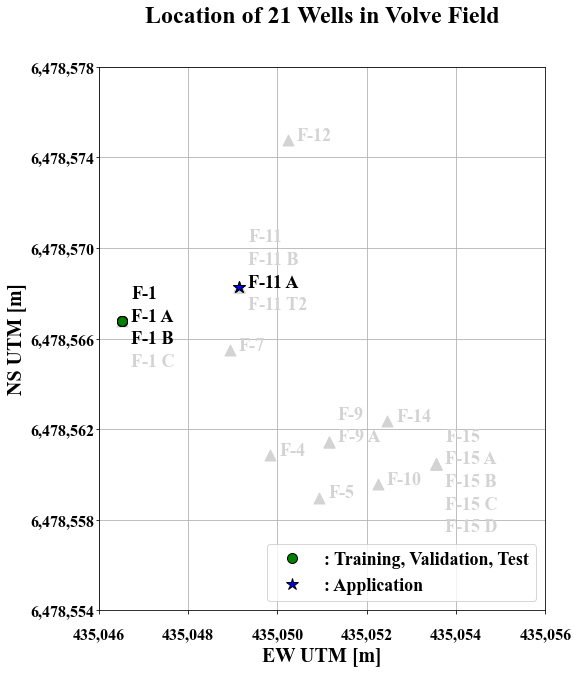
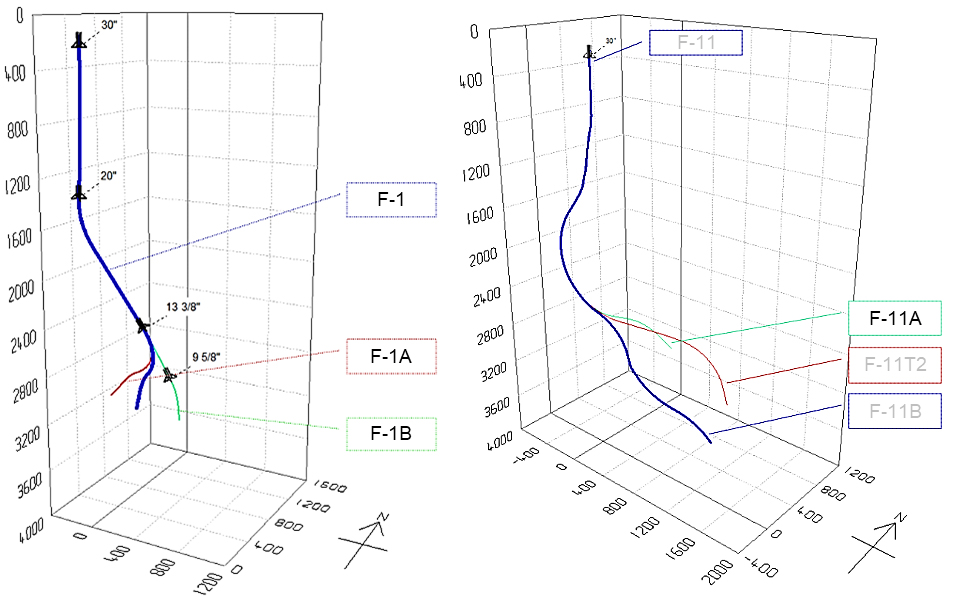
Fig. 10.
Trajectories of well F-1 and well F-11 in the Volve oil field. Well F-1 has two sidetrack wells: well F-1A and well F-1B. Well F-11 has three sidetrack wells: well F-11A, well F-11T2, and well F-11B (Statoil, 2013; Statoil, 2014).
Table 5는 본 사례 연구에서 사용한 물리검층의 측정 심도와 간격, 자료의 개수를 유정별로 나타낸다. F-1B를 제외한 3개의 유정 자료는 Volve 유전의 저류층 심도(2,700–3,100 m)를 포괄하고 있으며, 4개의 유정에서 얻은 물리검층 자료는 모두 0.1 m 간격으로 측정되었다. 유정별 물리검층 자료 수와 측정 심도를 고려하여 F-1A는 학습, F-1B는 검증, F-1은 시험자료로 사용하였다. 상대적으로 먼 거리에 위치하는 F-11A는 적용자료로 사용하였다. 4개 유정은 NPHI, RHOB, GR, RT, DT, CALI, PEF 등 다양한 종류의 물리검층 자료를 포함한다. 가용한 물리검층 종류 중 선행연구 고찰에 따라 DT를 추정하기 위한 입력자료로 NPHI, RHOB, GR, RT를 선별하였다. Table 6은 학습, 검증, 시험에 사용한 유정들의 입출력자료에 대한 통계 인자를 정리하였다. 모든 입출력자료는 학습 및 검증 자료의 평균과 표준편차를 이용한 표준화(standardization)를 통해 동일한 스케일로 변환하는 전처리 과정을 수행하였다. 이 때, RT를 입력자료로 사용하는 경우 RT의 비선형성을 고려하여 로그를 취한 후 분석에 사용하였다.
Table 5.
Measured depth and interval for each well
Table 6.
Summary of statistical parameters of well log data obtained from the wells F-1A, F-1B, and F-1
Fig. 11은 입출력자료 인자 간의 상관관계를 스피어맨 상관 계수(Spearman correlation coefficient)로 나타낸 것이다. 출력자료 DT에 대하여 NPHI와 GR는 강한 양의 상관관계를 보이는 반면, RHOB와 RT는 강한 음의 상관관계를 보이는 것으로 나타났다.
입력자료 조합에 대한 민감도 분석
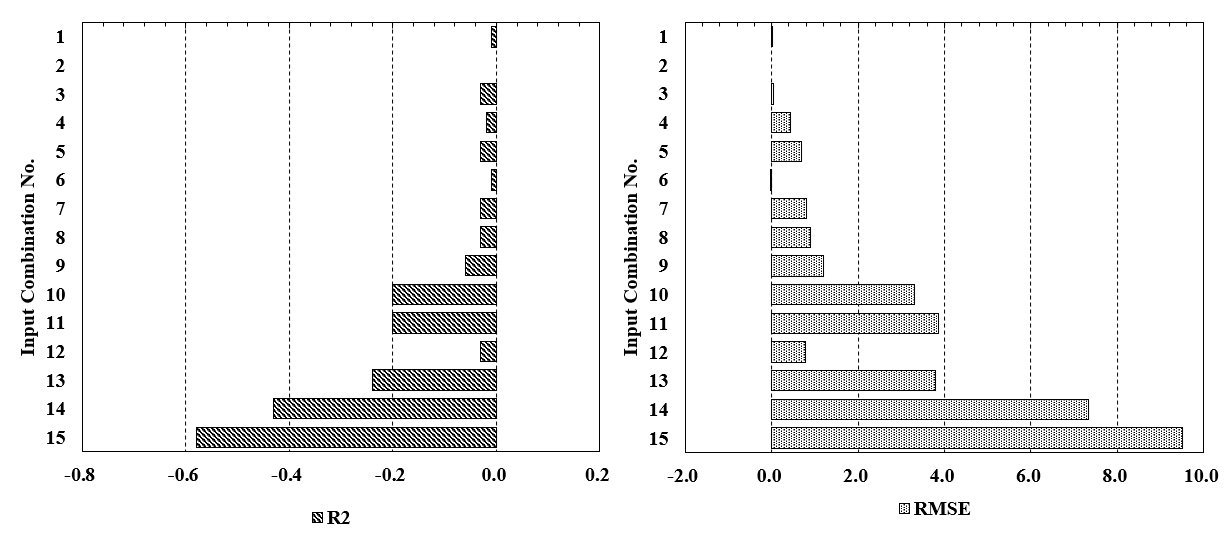
입력자료의 조합은 딥러닝 모델의 성능에 큰 영향을 끼치므로 다양한 입력자료 조합을 구성하여 민감도 분석을 수행하였다. 입력자료는 Fig. 11의 상관관계를 고려하여 총 15가지 조합으로 구성하였으며, 딥러닝 모델(DNN, CNN, LSTM)별로 학습, 검증, 시험하고 설계가 완료된 모델을 F-11A에 적용하였다. Table 7은 F-11A 결과를 RMSE와 R2으로 제시하였으며, 각 결과는 랜덤시드(random seed)를 변경하며 30회 반복 수행한 결과를 평균 µ와 표준편차 σ로 나타냈다. 또한, 신경망에 기반하고 있는 세 가지 딥러닝 모델과의 대조군으로서 선형회귀분석(linear regression, LR)에 대한 결과도 함께 제시하였다.
전반적으로 LR, DNN, CNN, LSTM 네 가지 모델 모두 만족할만한 성능을 얻을 수 있었다. R2을 기준으로 할 때, 입력자료 조합 1번(No. 1)에서 13번(No. 13)까지의 경우 전반적으로 LSTM이 가장 높은 성능을 보였다. 그 중 입력자료 조합 2번(No. 2)으로 NPHI, RHOB, GR을 사용하는 경우 R2의 µ ± σ가 0.94 ± 0.00, RMSE의 µ ± σ가 5.05 ± 0.01로 가장 우수하였다. 한 종류의 물리검층 자료만을 입력하는 입력자료 조합 14번(No. 14)과 15번(No. 15)의 경우 DNN이 4가지 모델 중 가장 높은 성능을 보이긴 하나 R2의 평균이 0.65 이하로 전반적으로 다른 입력자료 조합에 비해 열등하였다. 특히, RT를 입력한 조합 15번(No. 15)은 모든 모델에서 가장 낮은 성능을 보였다. 반면, NPHI를 입력한 조합 12번(No. 12)은 단일 물리검층 자료만 입력함에도 불구하고 모든 모델에서 R2이 0.8 이상이다. 이는 Fig. 11에 나타난 것처럼 Volve 유전에서 출력자료 DT와 NPHI가 0.91의 상관계수 R로 매우 높은 상관관계를 보이기 때문이다. 다만, 랜덤시드의 변화는 결과에 큰 변동을 끼치지 않아 RMSE 및 R2의 표준편차 σ는 대부분 0에 가까운 값이 산출되었다.
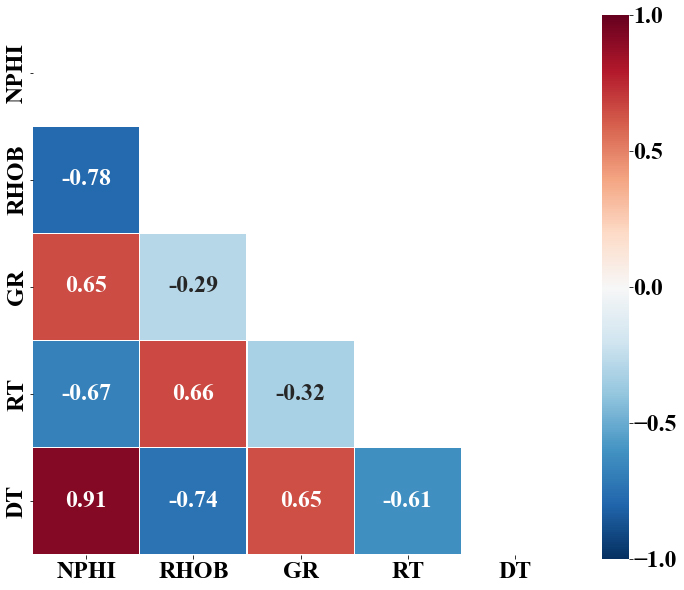
Table 7에 나타난 것처럼 log(RT)로 입력자료를 적용했을 때, R2이 유의미하게 증가한 것을 확인할 수 있다. LR의 경우 입력자료 조합에 RT가 포함된 경우(No. 1, 3, 4, 5, 8, 10, 11, 15) 로그를 적용하지 않은 RT를 입력하면 R2이 0에 가까운 값을 나타내며 성능이 크게 떨어졌다. 이는 매우 큰 RT가 측정된 일부 구간(3,468 m 부근)에서 발생한 오차가 LR의 전반적인 성능에 영향을 주었기 때문이다. 따라서, 비선형성이 높은 RT에 로그를 적용시키는 것이 전반적인 신경망 모델에서 출력자료 결과의 향상을 도모할 수 있음을 확인하였다. 반면, 딥러닝 모델의 경우 RT를 입력하는 경우 또는 log(RT)를 입력하는 경우 모두 상대적으로 유사한 결과를 도출하였다. 이를 통해, 주어진 입출력자료 사이의 비선형성이 강할수록 딥러닝 기반 모델이 유용함을 확인하였다.
Table 7.
Results of sensitivity analysis of each input combination under LR, DNN, CNN, and LSTM applied to well F-11A
한편, 15가지 입력조합 중 대체로 높은 성능을 보인 LSTM에 대하여 입력조합의 순위를 확인하였다. Fig. 12는 가장 우수한 성능을 보인 입력자료 조합 2번(No. 2)를 기준으로 하여 나머지 입력조합의 상대적 성능을 가시적으로 보여준다. 입력자료 조합 1번, 3번, 6번(No. 1, 3, 6)은 조합 2번(No. 2)과 유사한 성능을 보인다. 이상의 민감도 분석 결과를 바탕으로 입력자료를 NPHI, RHOB, GR로 결정하고 딥러닝 모델을 설계하였다.
딥러닝 모델 설계
Table 8은 본 사례 연구에서 설계한 딥러닝 모델(DNN, CNN, LSTM)의 구조를 나타낸다. 상기 모델의 출력 저류층 인자는 합성된 DT에 해당하므로 0.1 m 간격으로 측정된 원시 물리검층 자료를 인위적으로 제거하여 원시해상도를 1/10로 낮춰 사용하였다. 따라서, 입력자료로 1.0 m 간격의 NPHI, RHOB, GR를 사용하였으며, 딥러닝 기반 해석을 통해 DT를 5배의 고해상도로 출력한다. 출력자료의 간격은 0.2 m이며, 지도학습시 원시해상도를 1/5로 낮춘 정답 DT를 통해 학습이 이뤄진다.
물리검층 자료의 구성을 살펴보면, 가용한 유정이 4개이므로 학습, 검증, 시험, 적용자료로 F-1A, F-1B, F-1, F-11A를 각자 하나씩 사용하였고, 이에 입출력자료쌍의 개수는 각각 1,000개, 300개, 900개, 1,100개이다. 딥러닝 모델의 입출력자료의 크기는 알고리듬 특성에 따라 Table 3과 같이 구성하여 Table 8에 나타냈다. DNN은 1차원 벡터의 입력을, CNN은 3차원 배열의 입력을, LSTM은 2차원 배열의 입력을 받아 출력한다.
Table 8.
Structure of the DNN, CNN, and LSTM algorithms
딥러닝 구조를 살펴보면, DNN은 3개의 은닉층이 64-32-8의 노드를 갖도록 설계되었다. 모든 은닉층의 활성화함수는 정규화된 값의 범위를 고려하여 tanh를, 출력층의 활성화함수로는 선형함수를 적용하였다. CNN은 합성곱 단계에서 합성곱층을 2번 반복하였으며 각 층은 각각 8개, 16개의 필터와 활성화함수로 ReLU를 적용하였다. 각 층의 필터 크기는 (3,3)으로 설정하였다. 풀링층은 첫번째 합성곱층 다음에만 1번 사용되었다. 이후 평탄화층(flattening layer)을 거쳐 완전연결 단계에서 노드의 수가 16-8로 은닉층 2개를 거쳐 출력층에 도달한다. 이때 DNN과 마찬가지로 완전연결 단계에서 은닉층의 활성화함수로는 tanh를, 출력층의 활성화함수로는 선형함수를 적용하였다. LSTM은 1개의 LSTM 셀을 32개 노드로 구성하였으며, LSTM 셀 내에서 후보 셀 상태와 은닉 상태 계산에서는 활성화함수로 tanh를, 게이트 계산에서는 활성화함수로 sigmoid를 적용하였다. 그리고 출력층의 활성화함수로는 선형함수를 적용하였다.
상기 3가지 유형의 딥러닝 모델의 손실함수는 MSE를 사용하였다. 학습과정에 사용하는 최적화 기법으로는 Adam (adaptive moment estimation)을 적용하였다. 학습률(learning rate)은 0.001이다. 모델별 학습 횟수(epochs)는 최대 300회이며 과적합(overfitting) 발생시 학습을 종료(early stopping)하도록 설정하였다. 검증 오차 기준 최소 변화량이 0.0001보다 작을 경우 학습이 조기 종료되었다. 학습이 완료된 딥러닝 모델의 성능은 평균 제곱근 오차 RMSE와 결정계수 R2으로 평가한다.
연구 결과분석
Fig. 13과 Fig. 14는 LSTM을 30회 반복 수행한 결과 중 시험 자료의 R2이 평균 µ와 가장 유사한 성능을 보이는 특정 1회에 대한 손실함수와 산점도를 도시하였다. 학습자료 및 검증자료에 대한 손실 MSE는 표준화한 자료에 대한 MSE이며, 초기에 급격하게 감소하고 난 후 완만하게 감소하는 형태를 보였고 과적합을 방지하여 60회에서 학습을 종료하였다. 학습, 검증, 시험, 적용자료에 대한 RMSE는 3.29, 6.60, 4.96, 4.97, R2은 0.94, 0.92, 0.87, 0.92로 높은 예측 성능을 보였다.
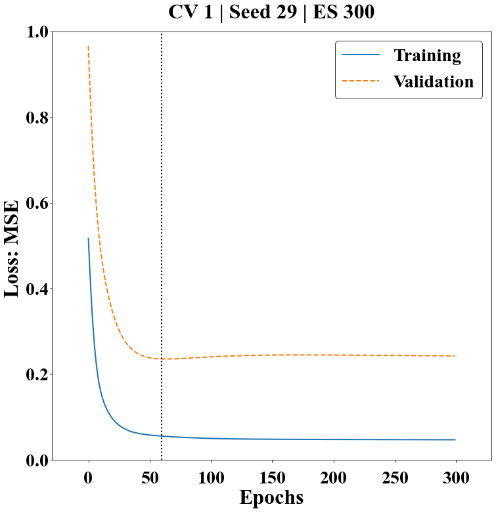
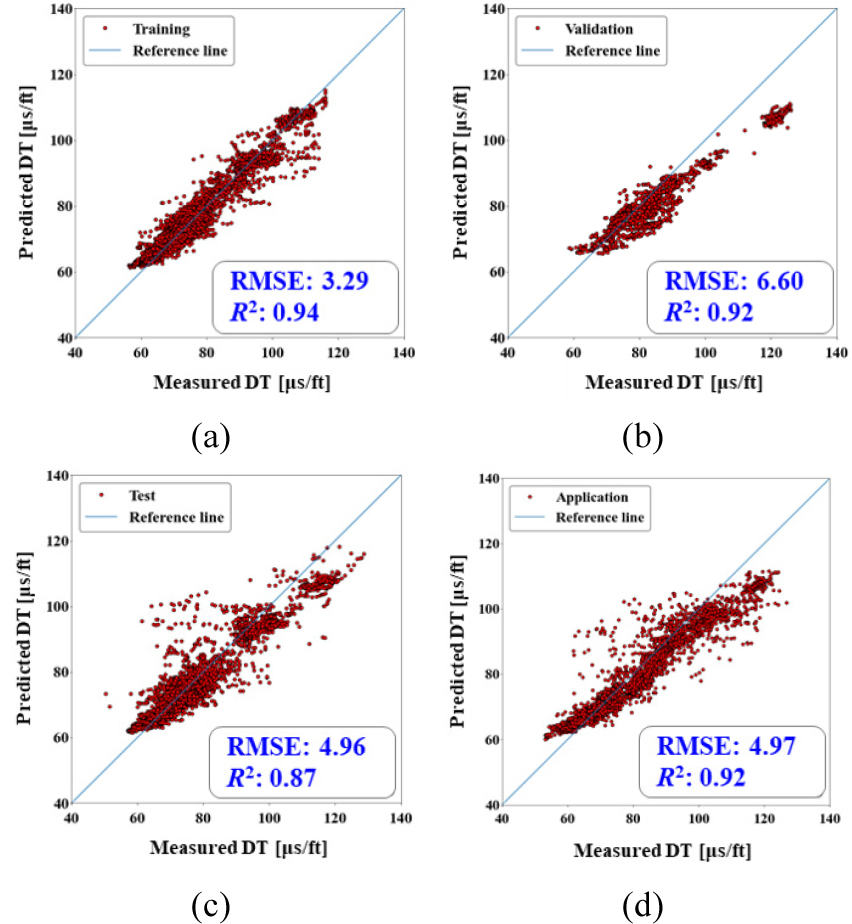
Fig. 15는 Fig. 13, Fig. 14에 나타낸 결과를 유정별로 도시한 것으로 입력자료의 해상도(1.0 m)의 5배 해상도(0.2 m)를 보인다. 실제 측정값과 LSTM으로 예측한 결과는 각각 빨간색과 파란색으로 나타냈다. DT를 통해 심도에 따른 지층변화를 유추할 수 있으며, 유정별로 지층 두께가 상이함에도 전반적으로 예측 결과가 측정 결과를 잘 따르는 것을 확인할 수 있다. 다만, DT가 큰 변동성을 보이는 상부(2,600–2,800 m)에서는 예측 정확도가 다소 감소하는 편이었으며, DT가 140 µs/ft에 가까운 큰 값을 보이는 부분(F-1B의 3,200 m, F-1의 3,300 m, F-11A의 3,550 m 부근)에서는 예측 결과가 과소 추정되는 경향이 있었다.
Fig. 16과 Fig. 17은 Fig. 15에 나타낸 결과 중 적용자료로 사용된 F-11A 출력자료 DT를 세부적으로 살펴보기 위하여 25 m 길이로 추출하여 입력자료 NPHI, RHOB, GR와 함께 나타냈다. 25 m 길이 구간을 추출할 때 Fig. 16은 DT 예측 결과가 실제 측정 결과와 유사도가 가장 높은 경우를, Fig. 17은 가장 낮은 경우를 보여준다. 상기 모델은 의도한대로 5배의 해상도로 DT를 예측하였으며, 실제 측정 결과와 비교하였을 때 국부적인 경향 예측에는 다소 미흡하나 F-11A 전체 구간에 대한 전반적인 경향 예측은 RMSE가 4.97 µs/ft, R2이 0.92로 우수한 것으로 평가하였다. 이는 F-11A를 적용자료로 사용하여 LSTM을 30회 반복 수행한 결과(RMSE 4.98 ± 0.02 µs/ft, R2 0.93 ± 0.01) 중 특정 1회에 대한 결과이며, 나머지 29회에서도 유사한 결과를 보임을 확인하였다(Table 9). 국부적 경향 예측의 정확도는 후속 연구에서 고해상도 물리검층 자료를 바탕으로 추정한 고해상도 저류층 물성(공극률, 수포화도 등)을 코어자료와 매칭시키거나, 학습자료의 추가 확보, 초매개변수 최적화, 앙상블 딥러닝 도입 등 신경망 구조를 보다 효율적으로 자동 설계함으로써 개선할 수 있을 것으로 기대한다.
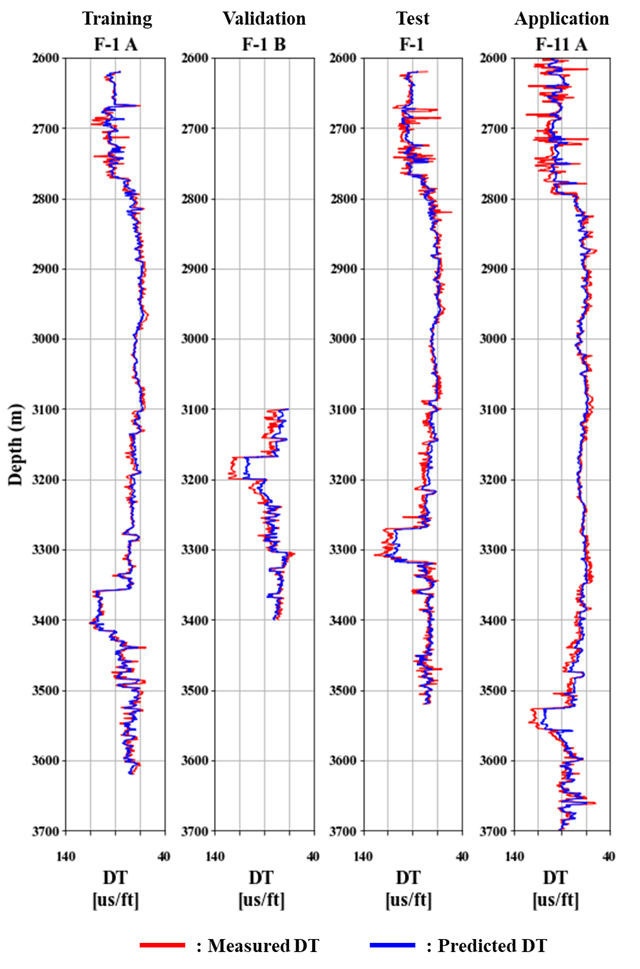
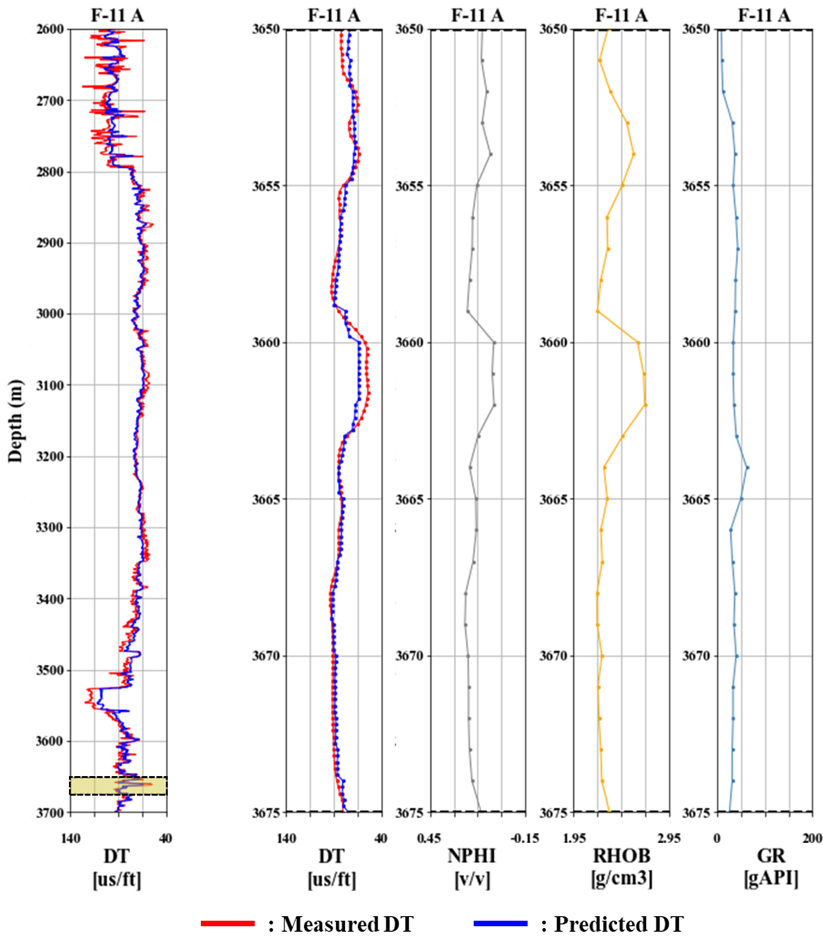
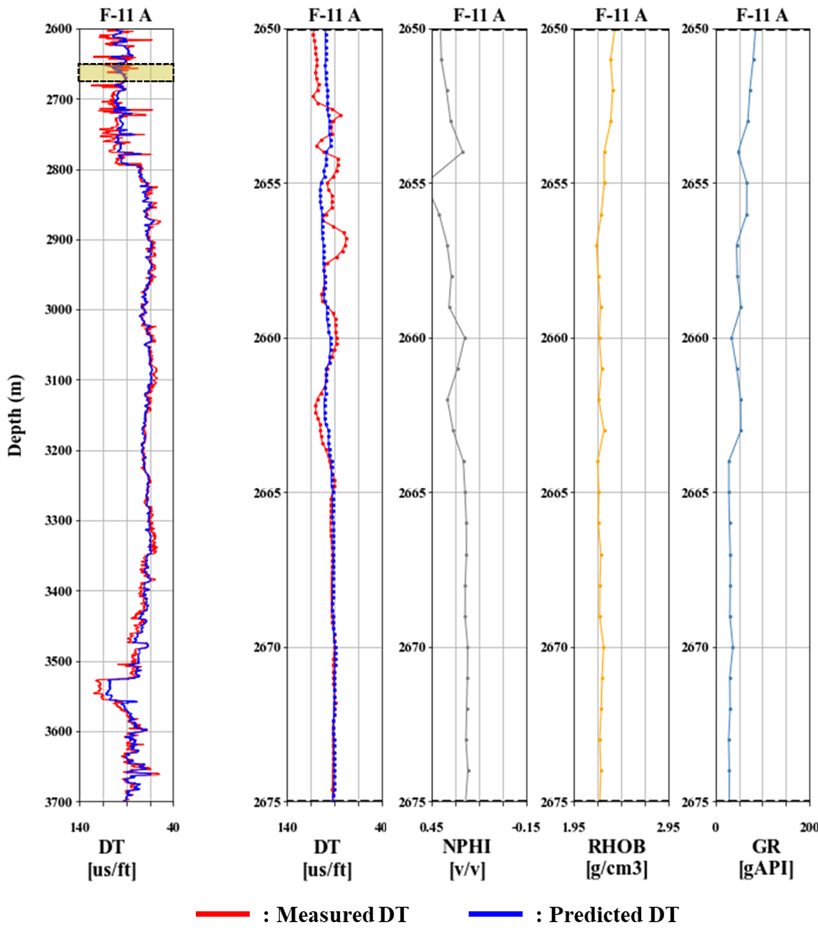
Table 9는 입력자료 조합 2번을 적용한 결과를 모델별로 제시하였으며, 각 결과는 30회 반복 수행한 결과를 평균 µ와 표준편차 σ로 나타냈다. Table 7은 적용자료로 사용된 F-11A에 대한 결과만을 제시한 반면, Table 9는 학습, 검증, 시험자료로 사용된 F-1A, F-1B, F-1에 대한 결과를 함께 제시하였다. 전반적으로 평균 R2이 0.8 이상, RMSE가 8 µs/ft 이하로 높은 성능을 보였다. 학습자료로 사용된 F-1A에 대해서는 LR R2가 0.92, DNN이 0.95, CNN의 R2이 0.91, LSTM이 0.95를 가지며, 검증자료로 사용된 F-1B에 대해서는 LSTM, DNN, LR, CNN 순으로, 시험자료로 사용된 F-1에서는 LR, DNN의 R2가 0.91, CNN이 0.86, LSTM이 0.94로 나타났고, 적용자료인 F-11A에 대해서는 각각 LSTM, DNN, LR, CNN 순으로 R2이 높았다. 이에 학습자료 F-1A, 검증자료 F-1B, 시험자료 F-1, 적용자료 F-11A에 대해 가장 높은 성능을 보인 LSTM을 본 사례 연구의 최적 모델로 선정하였다. Table 10은 입력자료 조합 2번과 LSTM 모델을 유정 F-11A에 적용한 예측 결과와 측정값을 나타낸다. 예측된 DT와 측정된 DT의 분포를 비교하였을 때, RMSE가 6% 이하의 차이를 보이는 것으로 확인하였다.
Table 9.
Results of training, validation, test, and application
Table 10.
Statistical parameters of measured and predicted DT in well F-11A using LSTM
한편, 상기 모델은 해상도 증가 비율 M을 5가 아닌 다른 비율로 설정하여 적용할 수 있다. Table 11은 Table 9의 LSTM과 동일한 조건하에 M을 2배, 5배, 10배로 다르게 설정하여 각각 학습을 진행하고 적용자료로 사용한 F-11A 결과만을 30회 반복 수행하여 평균 µ와 표준편차 σ로 나타냈다. 학습, 검증, 시험자료에 대한 결과는 생략하였다. 그 결과, M을 5배, 2배, 10배로 설정하였을 때 순으로 R2이 높았다. 이를 통해 M을 5가 아닌 다른 비율로 설정하여도 LSTM의 성능이 일관성있게 우수함을 확인하였다.
결 론
본 연구는 딥러닝 기반 해석을 통해 원시 해상도의 물리검층 자료로부터 고해상도의 물리검층 자료를 생성할 수 있는 방법론을 제안하였다. 제안한 방법론을 노르웨이 Volve 유전에 적용하여 검증한 결과를 바탕으로 다음의 결론을 도출하였다.
전통적인 합성 물리검층 자료 생성 방식의 경우 입출력자료가 동일한 해상도를 가지므로 생성한 물리검층 자료보다 높은 해상도를 갖는 코어자료와 직접적인 비교가 어렵다는 한계가 있었다. 이에 본 연구는 이러한 문제를 해결하기 위하여 물리검층 자료를 입력자료 해상도의 M배 고해상도로 예측할 수 있는 방법론을 제시하였다. 고해상도 모델링을 위해서는 입출력자료의 변환 과정을 필요로 하며, 이를 위해 본 방법론에서는 인접한 두 지점의 입력자료 쌍 (N–1, 2p)으로부터 같은 심도에 대응하는 M개 지점의 출력자료 쌍 (N–1, (M+1)q)을 예측하도록 설계하였다. DNN, CNN, LSTM 알고리듬별 특성에 따라 입력자료의 배열 크기를 조정하였다.
상기 세 가지 딥러닝 모델을 적용하여 노르웨이 Volve 유전에서 DT를 원시 해상도 대비 2배, 5배, 10배의 고해상도로 추정하였다. 또한, 딥러닝 모델의 비교군으로서 LR에 대한 결과를 함께 제시하였다. 15가지 입력자료 조합에 따라 민감도 분석을 수행한 결과, NPHI, RHOB, GR 조합이 가장 우수한 성능을 보였으며 해당 입력자료 조합에서는 LSTM, CNN, LR, DNN 순으로 높은 예측 성능을 보였다. 또한, 대부분의 입력자료 조합에서 LSTM이 가장 우수한 성능을 보였다. 이는 물리검층 자료가 심도에 따라 순차적으로 측정된 1차원 자료라는 특성이 반영된 결과로 해석된다. 제안한 고해상도 모델에서 해상도 증가비율 M은 다양하게 설정할 수 있으며, LSTM 모델에 대하여 2배, 5배, 10배와 같이 출력 해상도를 다르게 학습하여 적용한 결과 세 경우 모두 R2이 0.91이상으로 우수한 성능을 보였다.
본 연구는 딥러닝 기반 모델에 입출력자료의 고해상도 변환 과정을 접목하여 합성 물리검층자료 생성에 있어 입력자료보다 높은 해상도로 출력이 가능하도록 고해상도 모델을 제안하였다. 본 연구는 저류층 해석에서 전통 물리검층 측정 간격보다 얇은 지층 특성까지 고려할 수 있는 기반을 마련한 의의가 있다. 제안한 고해상도 모델은 합성 물리검층 자료 생성과 저류층 물성 추정과 관련한 연구에서 입출력자료의 구성과 딥러닝 알고리듬을 달리하여 다양하게 적용 가능하다는 측면에서 범용성을 확보할 수 있다. 연구 성과는 고해상도 물리검층 자료에 기반한 저류층 물성과 코어자료에 기반한 저류층 물성을 통합하여 저류층 물성을 추정하는 후속 연구로 발전시키고자 한다. 또한, 초매개변수 최적화, 앙상블 딥러닝 등 머신러닝 자동화를 도입하여 딥러닝 모델의 구조를 보다 개선할 수 있을 것으로 기대한다. 제안한 방법은 향후 국내외 가스하이드레이트 부존층을 비롯하여 비전통 저류층에 대한 물리검층 해석의 신뢰도 향상에도 기여할 것으로 기대한다.
Nomenclature
CALI: Caliper log
DPHI: Density porosity
DT: Sonic log
DTb: Borehole compensated sonic log
DTh: High-resolution sonic log
DTCO: Compressional wave sonic transit time
DTSM: Shear wave sonic transit time
EPHI: Effective porosity
GR: Gamma-ray log
lw: Window length of array
M: Ratio of log resolution increased (M = Sin/Sout)
NEUT: Neutron log
NPHI: Neutron porosity
p: Number of input log types
PEF: Photoelectric effect log
q: Number of output log types
RHOB: Density log
Rxo: Resistivity of the flushed zone
RT: Resistivity log
Sgh: Gas hydrate saturation
Sin: length between adjacent input data points
Sout: Interval length between adjacent output data points
Sw: Water saturation
SFL: Spherically focused log
SP: Spontaneous potential log
vp: Compressional wave velocity
Vsh: Shale volume
ϕ: Porosity
