

서 론
순환신경망 및 주의집중 메커니즘 개요
장단기기억(LSTM)
양방향 게이트 순환 유닛(BiGRU)
주의집중 메커니즘(AM)
셰일가스 생산량 예측 모델 구축
연구대상 지역 및 전처리 수행
생산량 예측 모델 구축
하이퍼파라미터 최적화
셰일가스 생산량 예측 결과 비교 및 분석
LSTM 및 BiGRU를 활용한 생산량 예측
BiGRU-AM을 활용한 생산량 예측
BiGRU-AMDC를 활용한 생산량 예측
예측성능평가 및 분석
결 론
서 론
유·가스 저류층의 생산성 평가를 통해 추정된 매장량은 개발 가능성 판단의 근거로 활용되며, 정확한 초기 생산량 예측은 석유산업의 상류 및 중류 부문 간의 거래 과정에 있어 합리적인 투자 결정을 위해 필수적이다(Niu et al., 2023; Zhou et al., 2024). 석유 및 천연가스 자원의 생산량 예측을 위해 경험적 수식의 감퇴와 연관된 매개변수를 생산이력을 바탕으로 도출함으로써 간편한 예측이 가능한 생산감퇴곡선분석법(decline curve analysis, DCA)을 광범위하게 이용하고 있으나, 셰일가스 생산 지역에 적용할 경우 생산영향인자 사이에 존재하는 비선형적인 관계성을 반영하지 못하여 큰 변동폭으로 급격히 감퇴하는 생산량 예측에 한계가 존재한다(Lee et al., 2019; Wang et al., 2023).
이러한 셰일가스 생산량 예측에 있어 기존 예측 기법의 단점을 보완하고 입력인자 사이의 상관관계를 고려하기 위해 다양한 기계학습 기법이 도입되고 있으며(Wang et al., 2021; Lee et al., 2022), 순환신경망(recurrent neural networks, RNN)을 시계열 자료 예측에 이용 시 시점에 따른 입력자료의 특징을 순차적으로 학습하여 출력값에 반영할 수 있다. 그중 장단기기억(long short-term memory, LSTM), 게이트 순환 유닛(gated recurrent unit, GRU), 양방향 게이트 순환 유닛(Bidirectional GRU, BiGRU)을 활용하여 단일정을 대상으로 입력 시퀀스 길이(input sequence length)에 따른 생산량 변화를 반영하여 단기 및 장기 생산량을 예측하고 다양한 지역에서의 적용성을 확인한 연구가 수행되어 왔다(Li et al., 2022a; Yang et al., 2022; Vega-Ortiz et al., 2023). 또한, LSTM의 예측 신뢰성을 향상시키기 위해 군집화와 DCA 매개변수를 바탕으로 분석한 다수의 생산정 정보를 모델 학습에 적용한 바 있으며(Vikara and Khanna, 2022), 생산중단 기간(shut-in period), 월별 생산정 운영 일수, 초크 크기(choke size)와 같은 운영조건을 입력자료로 이용한 연구가 진행되었다(Lee et al., 2019; Li et al., 2022b).
이처럼 RNN은 지속된 학습을 바탕으로 신뢰성 있는 예측의 가능성을 보여 유·가스 생산량 예측에 활용되어왔으나, 누적된 정보를 반복 처리하는 구조적 한계로 인해 훈련정보가 소실될 수 있다. 이를 극복하고자 시점에 따른 생산 감퇴경향을 생산량 예측에 적용함으로써 실측치와의 간극을 줄여 LSTM 기반 모델의 예측 결과를 개선하였으며(Lee et al., 2023), 합성곱신경망(convolutional neural network, CNN) 및 MLP(multi layer perceptron)와의 결합을 통해 시계열 자료의 특징 추출을 보완한 연구가 수행되었다(Zha et al., 2022; Qin et al., 2023; Zhou et al., 2024). 또한, 입력자료 처리에 있어 주의집중 메커니즘(attention mechanism, AM)을 결합하여 RNN 기반 예측 모델의 학습 효율을 높인 바 있다(Fargalla et al., 2024a).
기존의 연구들은 생산이력에 영향력 있는 특성을 선정하고 생성하여 활용함으로써 예측 모델의 생산 추세 해석 능력을 개선하거나, 기계학습 알고리즘 결합 및 응용을 통해 예측 정확도를 향상시켰다. 그러나, 생산 초기의 감퇴와 연관된 정보를 바탕으로 AM을 통한 예측 모델의 성능 변화를 분석한 시도는 부족한 실정이다. 이에 이 연구에서는 미국 Barnett Shale의 생산정 자료를 바탕으로 LSTM과의 생산량 예측성능을 비교함으로써 BiGRU의 실시간 셰일가스 생산량 예측에 대한 적합성을 확인하고 BiGRU에 AM을 결합한 BiGRU-AM모델과 초기 생산량에 대비되는 감퇴경향 관련 인자를 고려한 BiGRU-AMDC모델을 활용하여 각 기법에 따른 예측 개선 효과를 파악하고자 한다.
순환신경망 및 주의집중 메커니즘 개요
장단기기억(LSTM)
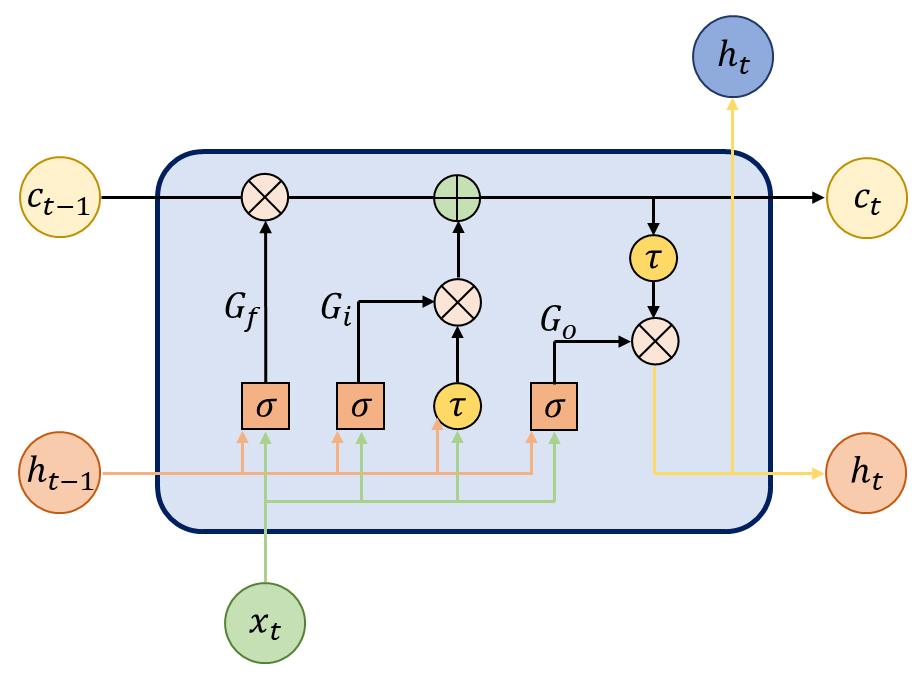
LSTM은 Hochreiter와 Schmidhuber(1997)에 의해 제안된 RNN의 일종으로 기존 RNN의 가중치 최신화 과정에서 발생하는 기울기 소실 문제를 해결하기 위해 복잡한 게이트(gate) 구조를 도입하여 입력된 정보 사이의 장기의존성을 높인 모델이다(Lee et al., 2019). LSTM은 시점에 따라 정보를 저장하고 전달하는 메모리 셀에 기반을 두고 있으며, 메모리 셀은 입력 게이트(), 망각 게이트(), 출력 게이트()로 구성된다(Fig. 1). 에서는 메모리 셀에 저장될 새로운 정보량을, 에서는 입력된 정보 중 유지할 정보량을, 에서는 다음 은닉층으로 전달할 정보량을 결정한다(Ma et al., 2023). 비선형 연산을 통해 현 시점의 입력 정보()와 이전 시점의 hidden state()에 포함된 정보를 cell state()와 으로 전달하며, 그 과정에서 시그모이드(sigmoid, 𝜎) 및 하이퍼볼릭 탄젠트(hyperbolic tangent, 𝜏)함수를 거치면서 각 게이트 구조에서의 정보 전달량을 조절한다(Lee et al., 2022). LSTM은 복잡하고 비선형적인 자료를 효과적으로 학습하는 것이 가능하여 석유 자원의 생산거동 예측에 주로 활용되고 있다(Liu et al., 2020).
양방향 게이트 순환 유닛(BiGRU)
BiGRU는 LSTM보다 간소화되어 연산 효율성이 개선된 GRU로 부터 파생된 인공신경망으로 추가 구성된 역방향 GRU 신경망을 통해 역순으로 시계열 자료의 주요 정보를 학습하여 기존 모델의 훈련정보 소실 문제와 예측의 불확실성을 완화하기 위해 제안되었다(Qin et al., 2023; Zhou et al., 2023). Fig. 2와 같이 BiGRU 신경망은 GRU가 이중으로 구성된 hidden layer 구조를 통해 순방향과 역방향으로 입력된 데이터를 처리하여 hidden state()를 갱신하는 방식으로 작용한다. 이를 통해 BiGRU는 순차적인 시계열 자료의 특성뿐만 아니라 이전과 이후의 값이 특정 시점에 미치는 영향을 고려하여 입력자료를 보다 포괄적으로 학습한다(Liu et al., 2024). 이러한 특성으로 인해 입력 시점에 따른 상관관계 도출에 효과적이며, 양방향으로 복잡한 특징을 결합함으로써 자료 간의 연결성을 높여 보다 세부적인 분석 및 예측이 가능하다(Li et al., 2024). BiGRU는 복잡한 거동이 나타나는 천연가스 생산량 자료 해석에 많이 적용되고 있다(Fargalla et al., 2024a).
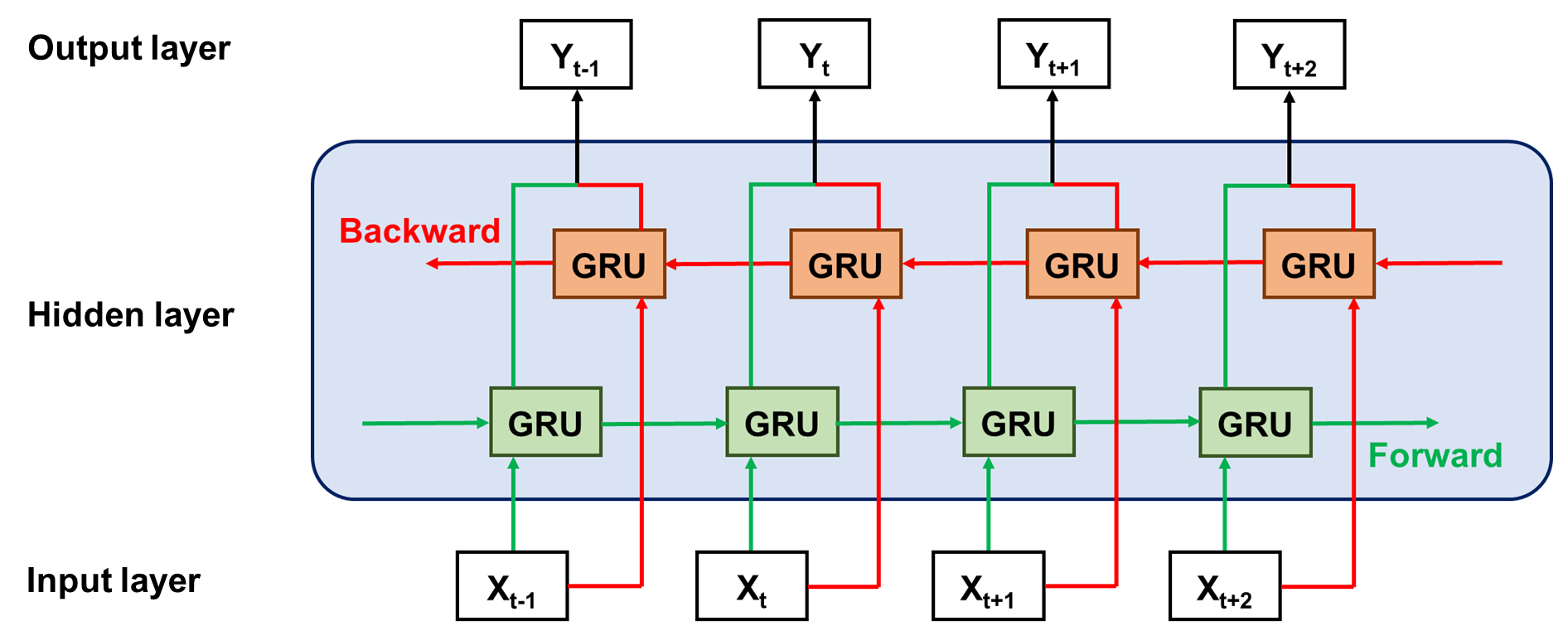
Fig. 2.
Schematic diagram of BiGRU representing the bidirectional flow of information (modified from Li et al., 2024).
주의집중 메커니즘(AM)
AM은 인간이 기호에 따라 관심사에 집중하는 인지 체계를 모방한 정보 처리 기법으로 출력값에 영향력 있는 특성에 가중치를 두어 판단한 중요한 정보를 선택적으로 학습하도록 한다(Liao et al., 2024; Yang et al., 2024). Fig. 3을 통해 입력자료로부터 가중치를 계산하여 선별한 정보를 선택적으로 출력하는 AM의 기능적 원리를 확인할 수 있다. AM은 주의점수(attention score) 계산과 가중치 할당의 두 가지 정보 처리 과정으로 구성되어 주의점수에 따라 우선적으로 훈련할 정보 특성을 결정한다(Kumar et al., 2023; Liu et al., 2023). 가중치에 근거한 AM의 지속적인 선별과정을 통해 중요한 특징을 집중적으로 처리하여 모델의 부분적 부하로 인해 발생하는 정보 처리 지연 문제를 완화할 수 있으며, 입·출력 간의 직접적인 상호 연결을 촉진하여 기울기 소실 문제를 방지하고 모델의 효율성과 예측 정확도를 향상시키는 것이 가능하다(Jung et al., 2020; Wang et al., 2023). AM은 생산량과 연관성 있는 정보를 선별하여 집중적으로 학습하도록 하여 중요하지 않은 특성에 의한 예측값의 신뢰성 저하를 방지한다(Chang et al., 2023). AM을 셰일가스 생산량 자료 학습에 활용함으로써 RNN 기반 모델의 생산 추이 예측성능을 향상시키는 것이 가능하다(Fargalla et al., 2024b).
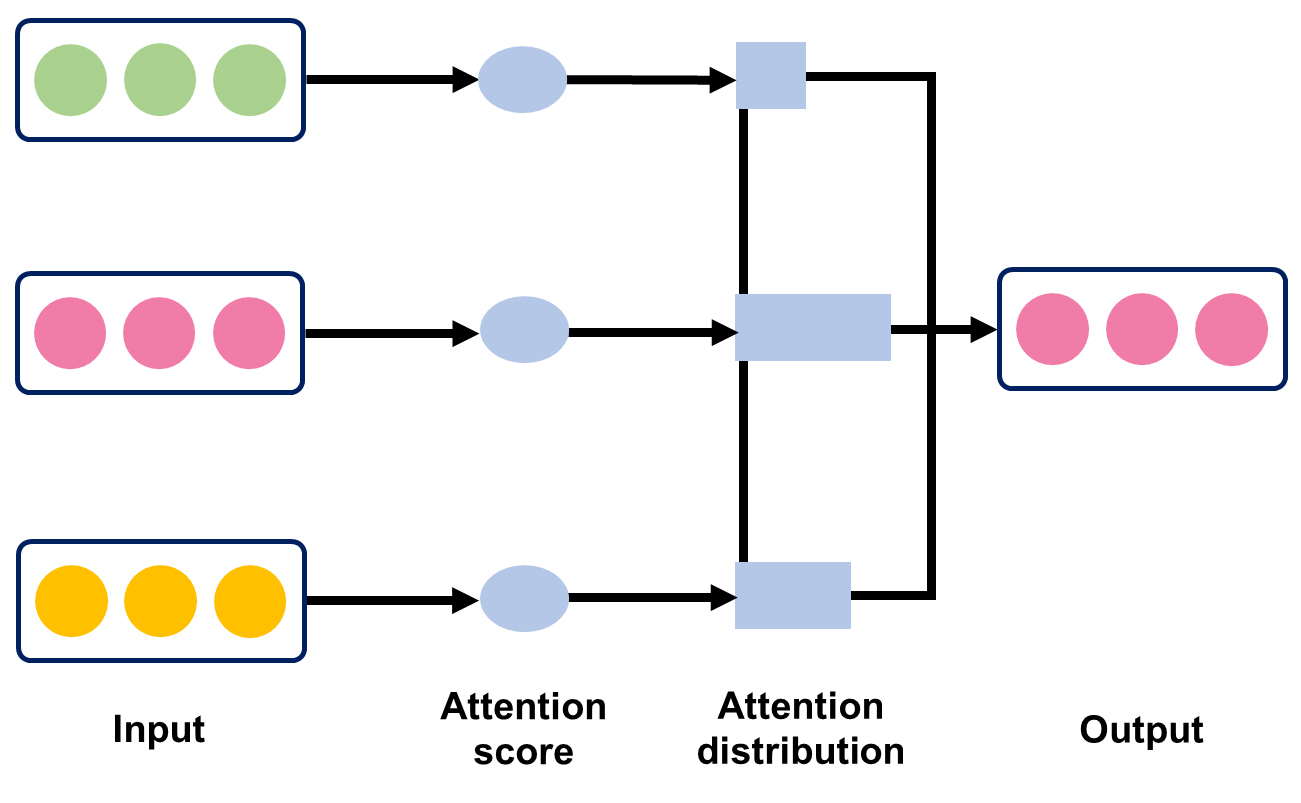
Fig. 3.
Schematic diagram of AM representing the input selection (modified from Fargalla et al., 2024a).
셰일가스 생산량 예측 모델 구축
연구대상 지역 및 전처리 수행
미국 Texas주 Forth Worth 분지에 위치하여 1981년에 발견된 Barnett Shale은 미국에서 개발 규모가 큰 셰일 가스전 중 하나로 197 Tcf 이상의 가스가 부존되어 있으며, 실리카(silica)가 풍부하고 점토 광물이 적은 지층으로 이루어져 수압파쇄가 용이하여 약 44.1 Tcf의 가스가 기술적으로 회수 가능할 것으로 추정된다(Nguyen-Le et al., 2020). Enverus의 Drillinginfo를 통해 Barnett Shale의 가스 수평정의 월별 생산정 자료를 획득하였으며, 기계학습 모델이 전반적인 분포에서 과도하게 벗어난 생산 특성을 학습하는 것을 방지하고자 386개 생산정의 최대생산량(initial peak rate)을 활용한 사분위 범위를 기준으로 정상치의 상한 및 하한값을 도출하여 월별 최대생산량이 약 138.6 MMcf 미만인 생산정 자료를 취득하였다. 현장자료에 대하여 감퇴하는 추세의 월별 생산량 자료를 활용하기 위해 최대생산량 이전의 생산이력을 제거하였으며, 후속 값이 순차적으로 60개월까지 이어지도록 구성하였다. 이후, 생산이력에 이상치가 포함되어 직전 생산량에 대비하여 90% 이상 하강하거나 10배 이상 상승하는 추세가 반복되어 모델 학습에 부정적인 영향을 미칠 것으로 판단되는 생산정 자료를 제외하였다. 최종적으로 총 155개의 생산정 자료를 확보하였으며, 125개 생산정을 훈련, 15개를 검증, 나머지 15개는 테스트 데이터 셋으로 분류하였다.
셰일가스 생산정에서의 생산중단과 이후의 운영에 따른 생산성 변화는 생산곡선의 감퇴 경향에 직접적으로 연관된다(Niu et al., 2023). 이에 Lee et al.(2019)의 연구를 바탕으로 생산중단 개월 수를 합산하여 생산중단 기간을 생성하였으며, 자료 분석 과정에서 셰일가스의 감퇴폭에 대체로 반비례하는 것을 확인한 월별 생산정 운영 일수 자료와 더불어 입력인자로 활용하였다. 또한, 대부분의 생산이 초기에 진행되는 셰일가스의 특성에 따라 초기 24개월까지의 생산이력, 생산중단 기간, 월별 생산정 운영 일수로 구성된 11,160개 자료를 입력자료로 활용하였으며, Min-Max Scaling을 통해 자료 간의 크기 범위 차이로 인한 값의 편향을 방지하고 0에서 1 사이의 값으로 정규화함으로써 서로 다른 입력인자를 동일한 기준으로 연산한 훈련 및 검증 손실을 바탕으로 예측 모델의 최적화가 가능하도록 하였다.
생산량 예측 모델 구축
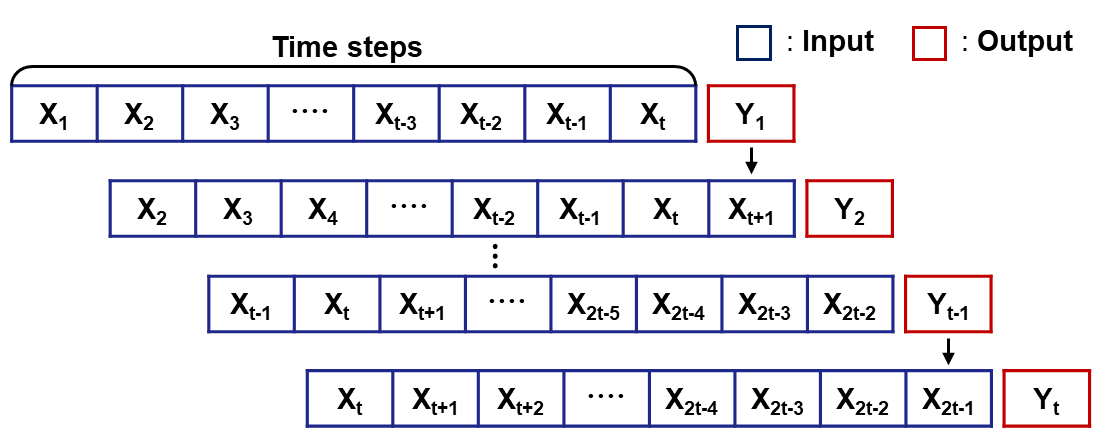
이 연구에서는 방법론에 따라 LSTM, BiGRU, BiGRU-AM, BiGRU-AMDC의 4가지 생산량 예측 모델을 구축하였다. 생산운영조건이 생산이력에 미치는 영향을 반영할 수 있도록 초기 24개월의 생산이력, 생산중단 기간, 월별 생산정 운영 일수를 입력자료로 활용하여 60개월까지의 생산거동을 예측하고자 하였다. 일관된 기준으로 성능을 비교하기 위해 각 예측 모델은 고유의 RNN층을 제외한 모든 구성 요소는 동일하게 설계하였다. 각 모델의 신경망에서 L2 정규화와 Dropout layer를 통해 과적합을 방지하였으며, SiLU(sigmoid gated linear unit)를 활성화 함수로 적용하여 Sigmoid 함수가 결합된 연산 과정을 통해 효율적인 자료 해석과 미세한 상관관계 도출이 가능하도록 하였다(Singh et al., 2023; Li, 2024). 또한, Time steps 길이에 해당하는 t 시점까지의 입력자료 X로 구성된 자료를 학습하여 다음 한 시점의 생산량 예측값 Y를 순차적으로 출력하는 many-to-one 방식을 적용하였다(Fig. 4). 이때 24개월 이후부터는 이전의 출력값을 시점마다 추가하여 입력자료로 활용함으로써 60개월까지의 예측을 수행하도록 하였으며, 이러한 예측치를 각 모델의 성능평가에 활용하였다.
BiGRU-AM 모델의 경우 BiGRU layer와 Dropout layer 사이에 쿼리(query, ), 키(key, ), 값(value, )의 세 가지 벡터(vector) 연산 과정으로 구현된 Self-Attention layer를 추가하여 구축하였다(Fig. 5). BiGRU를 통해 정교한 특징으로 변환된 입력 정보가 Self-Attention layer를 거치면서 비선형 연산을 적용하여 , , 벡터가 계산되며, , 벡터의 내적 결과와 Softmax 함수를 활용하여 계산한 주의 점수를 벡터와 곱해 입력 정보에 대한 가중치를 설정한다(Liao et al., 2024). 이를 바탕으로 학습된 정보가 Dropout layer와 Dense layer를 거쳐 통합되어 출력층으로 전달되면 시계열 자료의 예측을 수행할 수 있다. 이러한 AM 결합을 통해 장기 정보 보존으로 인한 부담을 줄이고 입력 정보로부터 중요한 특성을 추출하도록 연산 과정을 최적화하여 모델의 분석 능력을 향상시킴으로써 BiGRU의 생산이력에 대한 전반적인 학습능력을 높일 수 있다(Zhou et al., 2023; Fargalla et al., 2024a).
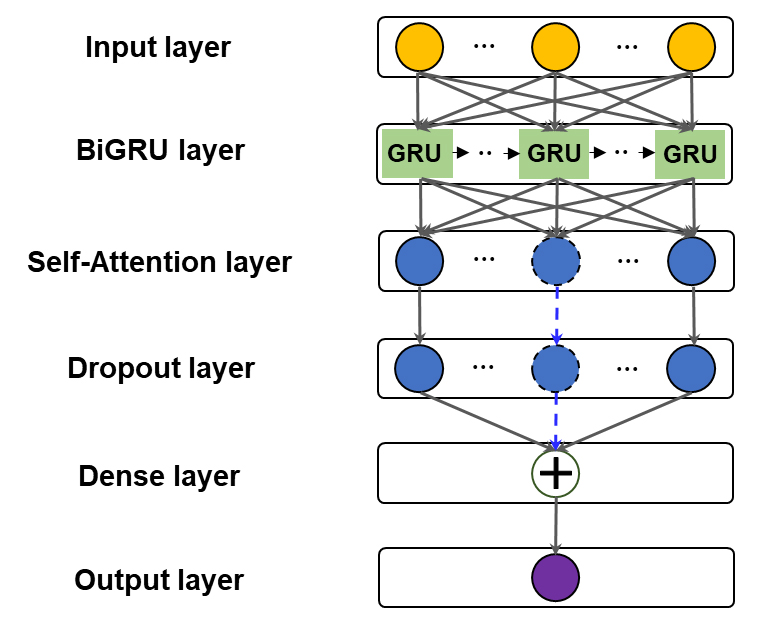
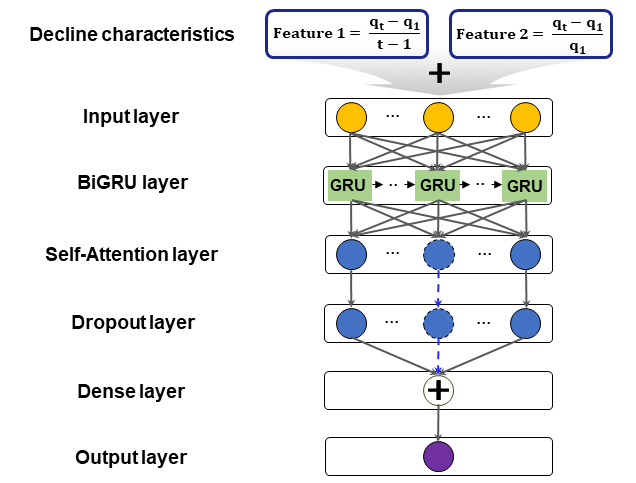
BiGRU-AMDC 모델은 BiGRU-AM 모델의 구조에 기반하며, 생산감퇴특성을 입력데이터 셋에 추가하여 학습할 수 있도록 함으로써 구축되었다(Fig. 6). 이를 통해 생산 관련 인자의 복합적인 영향으로 인한 셰일가스의 급격한 감퇴경향을 예측에 반영하는 것이 가능하다. 이때 생산감퇴특성은 Lee et al.(2023)의 연구에 근거하여 초기 생산량 과 특정 생산 시점 에서의 생산량 를 통해 도출한 기울기(Feature 1) 및 변화율(Feature 2)을 계산하여 도출되었다. Feature 1 및 2는 생산이력, 생산중단 기간, 월별 생산정 운영 일수와 함께 AM과 결합된 BiGRU 신경망을 통해 학습되며, 이 과정에서 생산감퇴특성이 생산 운영 및 중단에 의한 셰일가스 생산량의 복잡한 증감 해석에 활용되어 각 인자가 생산 감퇴에 미치는 영향을 선택적으로 학습하도록 한다.
하이퍼파라미터 최적화
신뢰성 있는 예측과 모델의 성능 향상을 위해 하이퍼파라미터(hyperparameter)를 조정하는 기계학습 모델 최적화 과정은 필수적이며, 이를 위해 정교한 탐색 및 검증을 바탕으로 효과적인 해 도출이 가능한 베이지안 최적화(bayesian optimization)를 적용하였다(Shahriari et al., 2015; Kulshrestha et al., 2020). 이때, Adam(adaptive moment estimation) 최적화기를 활용한 최적화 수행 시 식 (1)과 같이 나타나는 평균제곱오차(mean squared error, MSE)를 통해 훈련 및 검증 손실을 최소화하도록 손실함수를 설정하였다.
여기서 는 실제 생산량, 은 예측된 생산량, 은 전체 자료의 크기를 나타낸다.
베이지안 최적화 알고리즘은 무작위로 선정된 데이터 포인트를 바탕으로 확률적 모델을 활용하여 다음 탐색 지점을 선정하며, 이전 결과를 반영한 반복 연산 과정을 통해 점진적으로 예측의 불확실성을 줄여 개선된 최적해를 도출한다(Shahriari et al., 2015; Kulshrestha et al., 2020). 베이지안 최적화는 격자 탐색(grid search), 무작위 탐색(random search)과 같은 기존의 기법에 비해 비교적 적은 반복 횟수로 복잡한 수식의 최적해 도출이 가능하여 다양한 기계학습 알고리즘의 최적화에 효과적으로 활용될 수 있다(Kulshrestha et al., 2020; Lee et al., 2023).
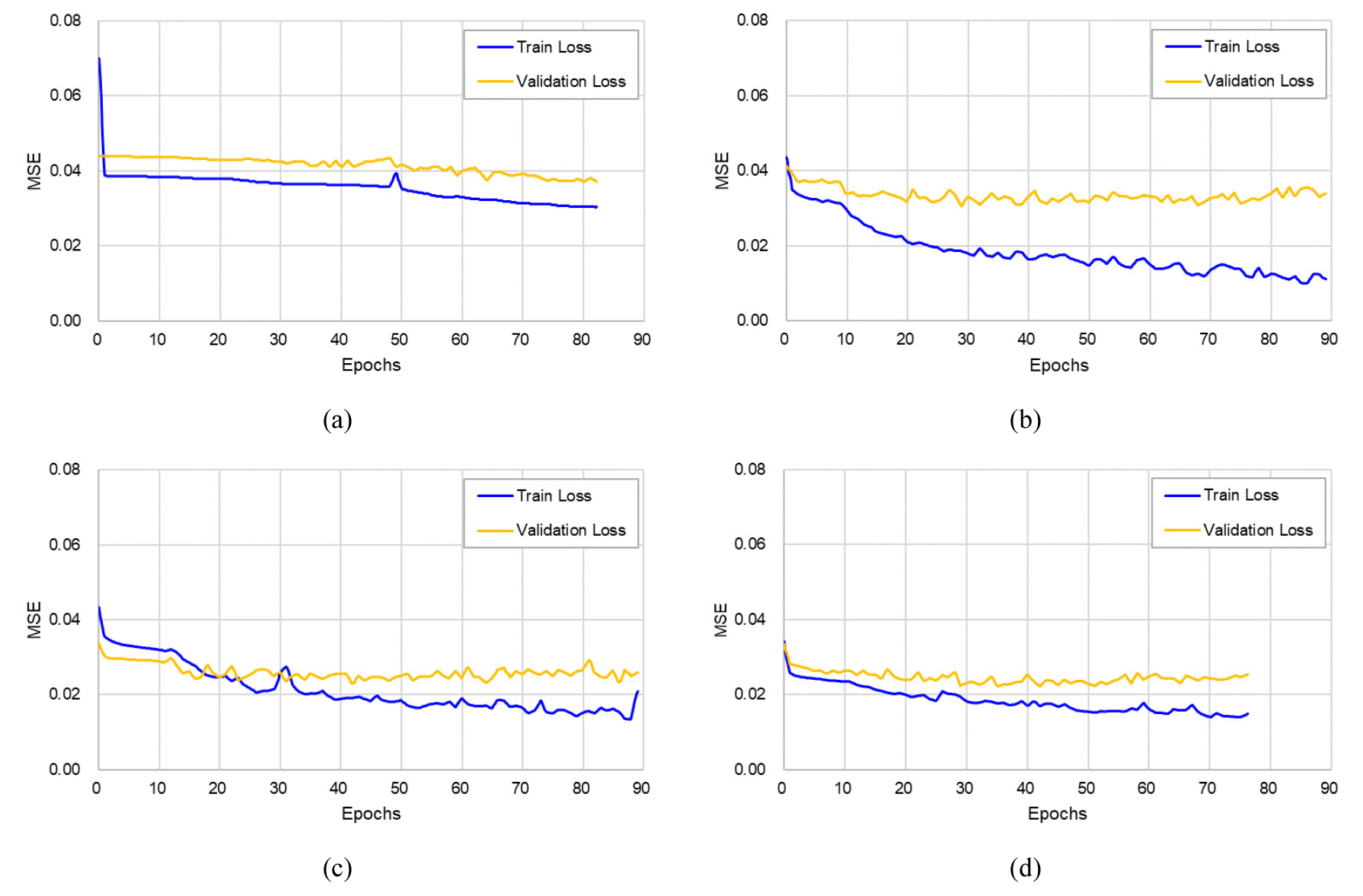
이 연구에서는 총 8가지의 하이퍼파라미터를 통해 신경망 구조와 예측 모델의 학습 방식을 최적화하고자 하였다(Table 1). Num units과 Num layers는 신경망 구조의 복잡성을 조정하여 학습성능을 결정하는 인자로 각각 신경망 내 뉴런(neuron) 수와 은닉층의 개수를 의미한다. 각 값이 증가할수록 모델의 자료 해석능력을 증대시키나 학습 효율이 저하할 수 있어 적절한 수치를 선정하는 것이 필요하다(Qiu et al., 2022; Lee et al., 2023). 또한, 모델의 복잡도로 인한 성능 저하를 완화하기 위한 인자로 Dropout rate와 L2 Reg의 최적값을 활용하였으며(Qiu et al., 2022), Learning rate의 최적해가 0.0001~0.01의 범위에서 도출되도록 설정하여 학습 효율과 결과 수렴 사이의 균형을 이룰 수 있도록 하였다. 이와 더불어 입력자료 훈련 시 모델에 적용될 입력자료의 형태와 연산 반복 횟수를 결정하기 위해 Time steps, Batch size, Epochs를 활용하였다. 그중 Time steps와 Batch size는 각 생산정의 자료 길이인 24를 초과하지 않도록 설정하였으며, Time steps를 기준으로 재구성된 자료에 따라 최적의 Batch size를 도출하도록 하였다. 이러한 각 인자의 최적해를 바탕으로 Epochs에 따른 훈련 및 검증 손실의 변화를 파악하였으며, AM이 학습 과정에 활용된 BiGRU-AM 및 BiGRU-AMDC 모델의 손실이 LSTM과 BiGRU 모델에 비해 낮게 나타나는 것을 확인하였다(Fig. 7).
셰일가스 생산량 예측 결과 비교 및 분석
전처리를 거친 현장 자료를 바탕으로 LSTM, BiGRU, BiGRU-AM, BiGRU-AMDC의 4가지 생산량 예측 모델에 대하여 순차적으로 성능 비교 및 분석을 수행하였다. 이때, 약 3~30 MMcf의 범위에서 다양하게 분포하는 셰일가스 생산량의 예측치를 일관성 있게 분석하기 위해 각 모델의 예측성능평가에 식 (2), (3)과 같이 평균절대백분율오차(mean absolute percentage error, MAPE)와 정규화된평균제곱근오차(normalized root mean squared error, NRMSE)를 활용하였다. MAPE는 예측치가 실측치에서 벗어난 정도를 백분율로 계산하여 상대적인 모델 성능 비교가 가능하며, NRMSE는 실제값의 분포를 바탕으로 큰 폭의 오차를 민감하게 판단할 수 있어 두 지표를 함께 고려한다면 예측 오차의 크기에 따라 상호보완적으로 모델의 성능을 분석하는 것이 가능하다.
여기서 는 실제 생산량, 은 예측된 생산량, 은 예측의 총 횟수를 나타낸다.
LSTM 및 BiGRU를 활용한 생산량 예측
구축한 BiGRU 및 LSTM 모델을 활용하여 테스트 생산정의 생산량 예측을 수행했으며, 대체로 LSTM에 비해 BiGRU의 성능이 더 우수한 것으로 나타났다(Fig. 8). Well 4에서는 LSTM의 예측치가 실측치에 비해 전반적으로 약 1~3 MMcf 정도 낮게 도출되었으나, BiGRU의 일부 예측 결과가 1 MMcf 내외의 차이로 실제의 경향과 유사하여 MAPE 및 NRMSE가 각각 11.6%p, 15.9%p 개선됨으로써 15.3%, 23.3%로 산출되었다. Well 8, 9에서는 LSTM에 의해 11~13 MMcf까지 과대 예측된 결과가 BiGRU에서 2 MMcf 정도 완화되었으며, 특히 Well 8에서의 BiGRU의 MAPE 및 NRMSE는 31.3%, 23.3%으로 나타났고 그 감소 폭은 각각 19.5%p, 14.4%p에 달해 LSTM과 BiGRU의 성능 차이를 극명하게 확인하였다. 이러한 결과들은 학습과 예측의 반복 과정에서 마지막 시점의 입력자료에 주요한 영향을 받는 LSTM과는 달리, 이전과 이후의 값이 특정 시점에 미치는 영향을 고려하는 것이 가능한 BiGRU 신경망을 통해 생산중단과 운영에 의한 셰일가스 생산량의 부분적인 감퇴를 학습하여 나타난 것으로 여겨진다.
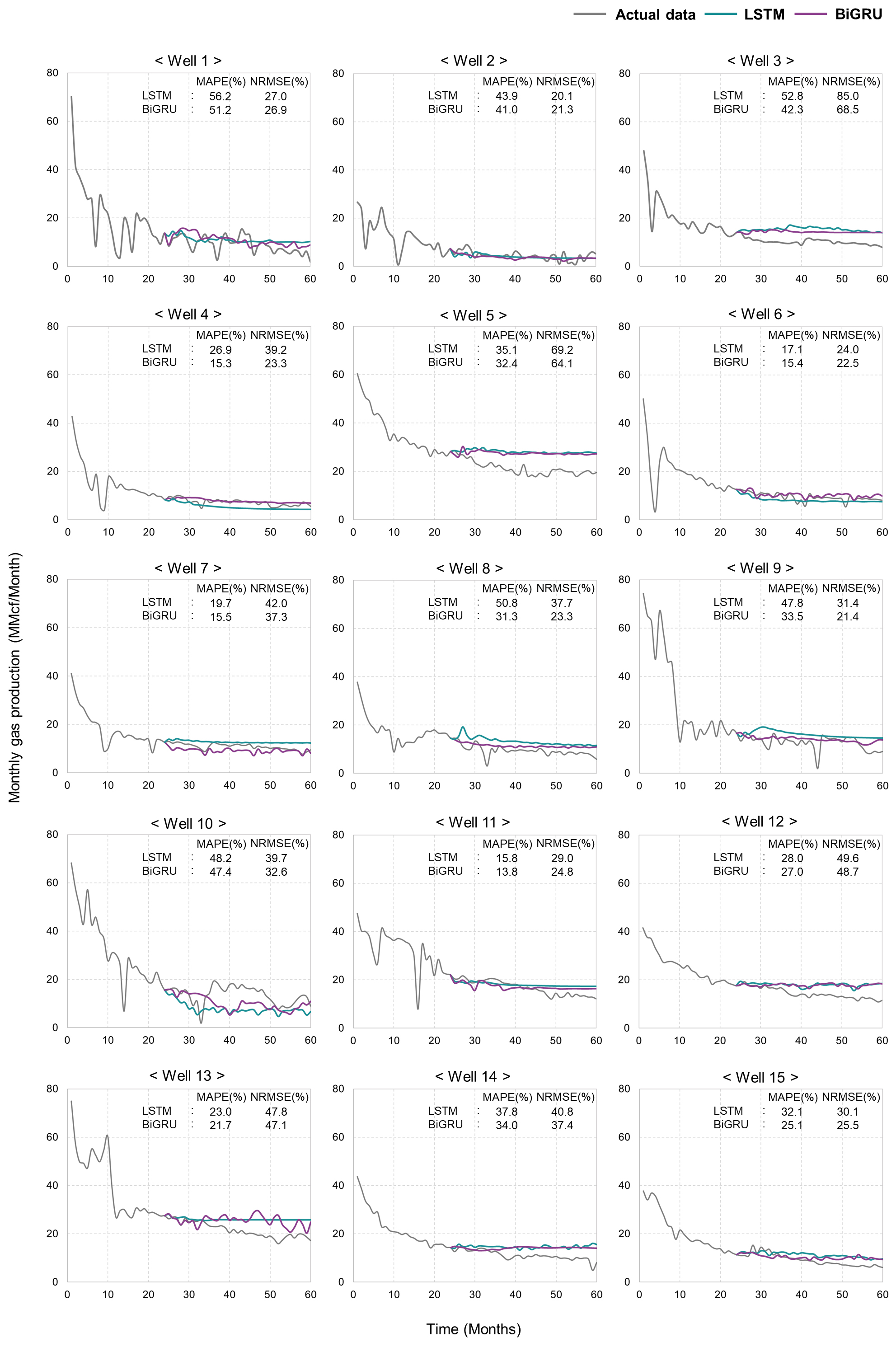
그러나, LSTM 및 BiGRU 기반의 예측치 전반에서 실측치와 상이한 결과가 도출되었으며, 특히 복잡한 생산 경향이 나타나거나 감퇴 추세가 불규칙한 생산정 자료가 예측에 활용될 때 정확도가 하락하였다. Well 1과 10은 각각 13.6 및 17.3 MMcf의 큰 폭으로 복잡한 증감이 발생하였지만 BiGRU 기반 예측치의 변동폭은 각각 8 과 10 MMcf 수준의 변동폭으로 실측치에서 크게 벗어나 두 생산정에서의 MAPE는 각각 51.2%, 47.4%로 높게 계산되었으며, NRMSE는 각각 26.9%, 32.6%로 나타났다. LSTM의 예측 결과는 BiGRU보다 1~5 MMcf 정도 낮은 변동폭에서 분포하여 Well 1과 10에서의 MAPE가 각각 56.2%, 48.2%로, NRMSE는 각각 27%, 39.7%로 높게 산출되었다. 또한, 예측 구간의 감퇴경향이 입력자료 후반 시점과 상이한 Well 3, 5, 12, 13, 14에서의 LSTM과 BiGRU의 결과는 과대 예측되었다. 그중 Well 3에서의 LSTM과 BiGRU의 NRMSE 수치는 각각 85%, 68.5%에 달하였으며, Well 5의 경우 NRMSE가 각각 69.2%, 64.1%로 산출되어 MAPE 수치들에 비해 약 26~34%p 정도 크게 나타났다. 이는 LSTM과 BiGRU 신경망에서 정보 처리가 누적됨에 따라 학습 및 검증된 정보에서 손실이 발생하였고 이를 바탕으로 Well 3과 5의 24개월까지의 자료를 해석하면서 마지막 5개월 동안의 증가하던 경향에 주요한 영향을 받아 예측치를 실제보다 과대 산정한 것으로 판단된다. 이와 같은 결과들을 통해 예측 모델의 학습성능과 신뢰성을 증진하기 위해 초기 정보 소실 방지가 필수적인 것을 파악하였다.
BiGRU-AM을 활용한 생산량 예측
BiGRU-AM을 활용한 예측치의 경향은 BiGRU의 결과 대비 실제 생산거동과 가깝게 나타나 MAPE 및 NRMSE의 수치가 개선되었다(Fig. 9). Well 3, 5에서 BiGRU의 결과가 각각 3~6 MMcf, 4.5~10 MMcf의 폭으로 과대 예측되었으나 BiGRU-AM을 통해 두 생산정에서 예측치와의 생산폭 차이를 약 4 MMcf 미만으로 저하함으로써 약 20%p 수준의 MAPE 감소폭을 확인하였으며, NRMSE는 약 40%p의 높은 폭으로 감소하였다. 이는 자료상에서 일부 나타난 일정한 경향으로 인해 BiGRU와 LSTM의 결과가 상향 예측되었던 결과를 극복한 것으로 AM 기반의 학습이 전반적인 생산 추세 해석과 예측에 효과적임을 의미한다. 그 결과 Well 3의 BiGRU-AM의 MAPE 및 NRMSE는 14%, 26.2%로 나타났고 Well 5에서는 각각 9.58%, 22.1%로 계산되었다. Well 13과 14의 경우, BiGRU에서 실측치와 약 5~10 MMcf 정도의 범위로 편차가 발생했던 부분이 BiGRU-AM에서 약 5 MMcf 미만의 차이로 개선되었다. 그 결과 Well 13의 MAPE는 7.1%p NRMSE는 16.3%p의 폭으로 감소하여 각각 14.6%, 30.8%로 나타났으며, Well 14에서의 두 평가지표의 감소폭은 약 19%p에 달해 각각 15.3%, 18.5%로 산출되었다. 또한, 실측치의 복잡한 거동 특성으로 인해 BiGRU 기반 예측의 한계가 나타났던 Well 1과 10에서 BiGRU-AM을 통해 예측치가 실제 생산량에서 약 10 MMcf의 차이로 크게 벗어나는 정도를 완화하여 MAPE 수치를 각각 13.8%p, 8.8%p 개선하였다. 이러한 결과들을 통해 BiGRU-AM은 장기 연산으로 인한 성능 저하를 방지하여 생산 운영과 중단이 생산에 미치는 영향을 효과적으로 반영할 수 있음을 파악하였다.
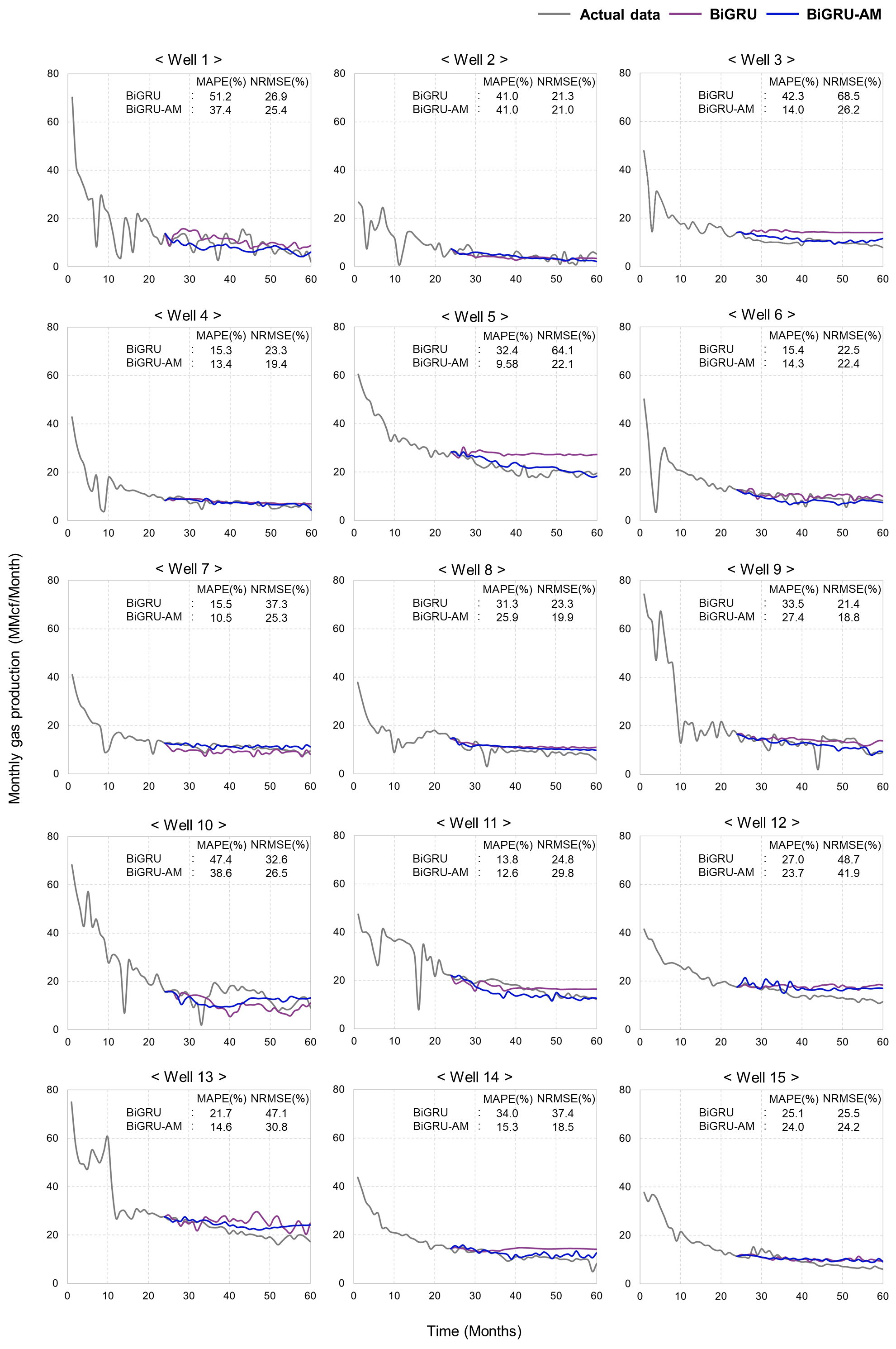
AM 기반의 학습은 대체로 예측 오차를 감소시켰으나, 특정 시점에서 실제의 생산 경향과의 차이가 크게 나타났다. Well 8, 12의 예측치는 전반적으로 상향 예측되었으며, Well 2, 6, 15의 경우에는 오차 개선 폭이 0.01~1.3%p로 유의미한 성능 변화를 확인할 수 없었다. Well 11에서는 BiGRU-AM의 초기 및 후기 예측치가 실측치와 1 MMcf 내외의 차이로 나타났으나 30개월에서 47개월 사이의 값이 과소 예측되어 BiGRU에 대비되는 MAPE의 감소 폭은 1.2%p에 그쳤으며, 일부 BiGRU 예측치와 실측치 사이의 편차에 비해 약 3 MMcf 높게 나타난 BiGRU-AM의 결과가 산출과정에서 오차를 제곱하는 NRMSE가 5%p 폭으로 증가하는 요인으로 작용하여 29.8%로 높게 계산되었다. 또한, 앞서 다루었던 Well 3, 5, 13, 14에서 여전히 부분적으로 하향 및 상향 예측된 결과가 나타났으며, Well 1, 10의 결과는 본래의 복잡한 생산거동과는 상이하게 도출되어 MAPE와 NRMSE가 각각 38% 및 26% 수준에서 높게 분포하였다. 이러한 결과들은 생산의 증감을 학습함에 있어서 그 추세와 연관된 추가적인 특성의 고려가 필요함을 시사한다.
BiGRU-AMDC를 활용한 생산량 예측
BiGRU-AMDC 모델의 예측 결과 실측치의 감퇴경향에서 벗어나는 정도가 완화되었으며, MAPE 및 NRMSE의 감소를 파악하였다(Fig. 10). 생산감퇴특성의 추가 학습은 Well 12의 초기 예측치와 실측치의 차이를 1 MMcf 미만으로 개선하였고 이를 이후 입력자료로 활용하면서 후속의 편차는 2 MMcf 내외로 도출되었다. 이를 통해 BiGRU-AM에 대비되는 BiGRU-AMDC의 MAPE 감소 폭이 약 15%p에 달해 8.98%의 오차율로 정확한 예측이 수행되었고 NRMSE는 24.6%p 감소하여 성능 상승이 가장 뚜렷하게 나타났다. Well 3에서는 마지막 60개월에서 실측치와의 생산폭 차이가 약 2 MMcf로 나타난 것을 제외한 BiGRU-AMDC의 모든 결과가 1 MMcf 내외로 예측되어 MAPE 및 NRMSE가 각각 9.51%, 16.6%로 나타났다. Well 11의 경우 BiGRU-AM에서 약 3~6 MMcf의 차이로 과소 예측되던 부분이 개선되어 실측치와의 차이가 1 MMcf 내외로 나타나 MAPE가 8.5%일 정도로 BiGRU-AMDC의 예측 결과가 실측치의 감퇴경향에 가까웠으며, NRMSE는 29.8%에서 13.7%p의 폭으로 감소하였다. Well 13, 15에서는 BiGRU-AM의 전반적으로 상향 예측된 결과가 BiGRU-AMDC를 통해 실제 생산 경향의 수준으로 개선되었다. Well 13의 BiGRU-AM을 활용한 예측치에서 최대 7 MMcf 수준까지 실측치와 차이가 나타났던 부분을 3 MMcf 내외로 저하시켜 MAPE는 5.95%로 높은 예측 정확도를 보였으며, NRMSE는 16.5%p 감소하여 14.3%로 계산되었다. Well 15의 경우 약 3 MMcf 정도로 나타났던 BiGRU-AM의 예측치와 실제 가스 생산량과의 차이가 BiGRU-AMDC에서 1 MMcf 수준으로 나타나 MAPE는 약 15%p 감소하여 9.05%로 도출되었고 NRMSE는 12.8%로 전체 테스트 결과 중 가장 낮았다. 복잡한 생산 특성이 나타나는 Well 1에 대해서는 BiGRU-AMDC를 활용한 예측치의 변동폭이 13.9 MMcf으로 실측치와 유사하게 나타났으며, 이를 통해 BiGRU-AM에서 부분적으로 약 7 MMcf으로 나타났던 실측치와의 편차를 4 MMcf 수준으로 줄였고 생산폭 차이가 1 MMcf 내외인 예측치의 빈도 수가 증가하여 MAPE가 5%p 정도 감소하였다. AM에 의한 성능 향상이 미세하게 나타났던 Well 2에서는 25~55개월까지의 예측치가 개선되어 MAPE의 감소 폭이 약 5%p로 나타났다. 이러한 결과들은 생산감퇴특성이 초기 생산량 정보를 내포하고 있어 AM과 더불어 훈련정보 소실로 인한 성능 저하를 방지한 것으로 판단된다. 또한, 생산감퇴특성은 생산중단 기간 및 월별 생산정 운영 일수와 더불어 생산량 예측의 주요 인자로 활용할 수 있음을 확인하였다.
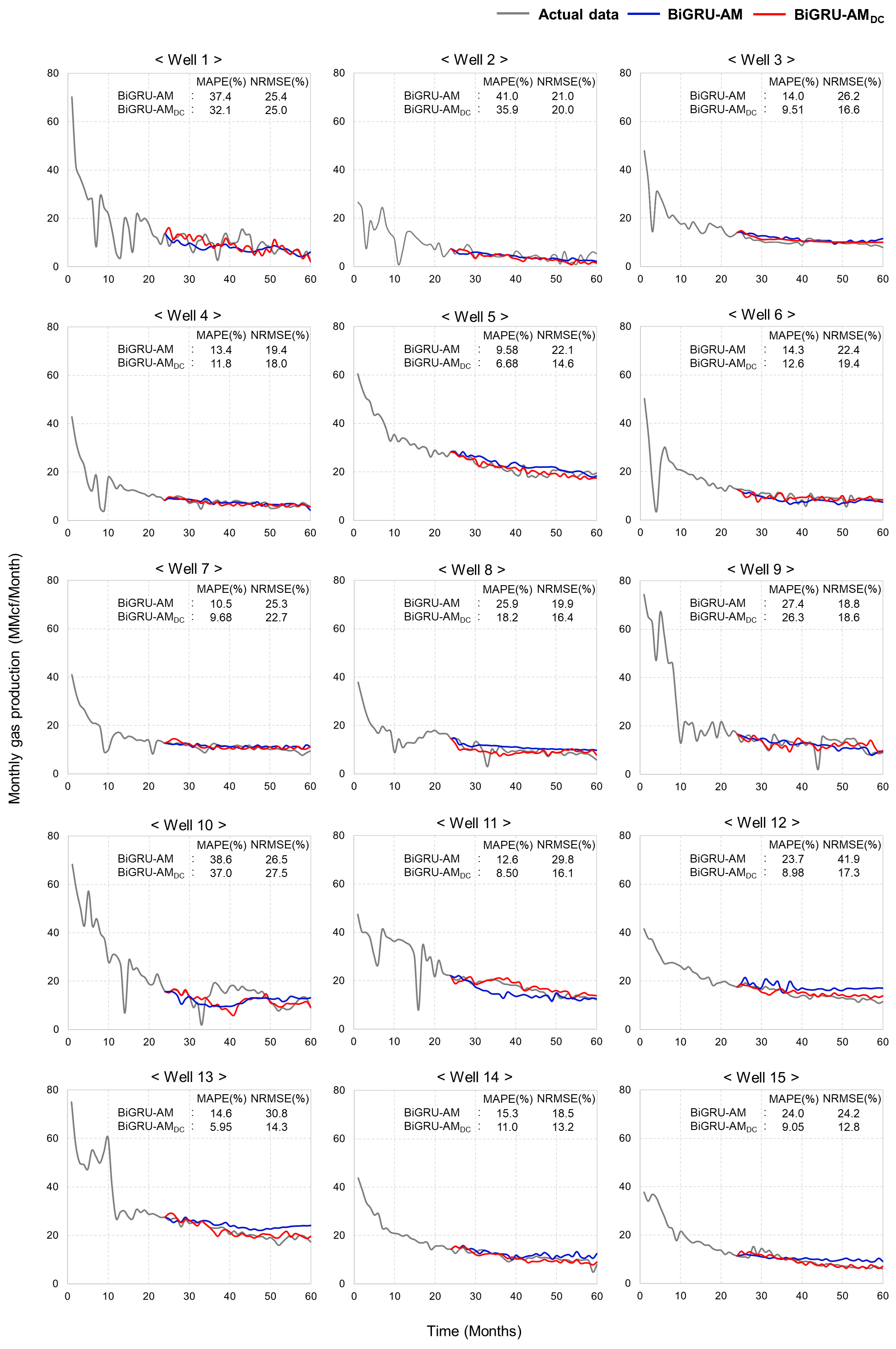
BiGRU-AMDC의 예측 결과는 BiGRU-AM에 대비하여 전반적으로 향상되었으나, 여전히 개선이 필요한 부분을 확인하였다. Well 1의 경우 BiGRU-AMDC의 43~45개월까지의 예측치는 2~5 MMcf의 폭으로 변동하는 실제 경향에 비해 1~2 MMcf의 범위에서 거동하여 MAPE가 32.1%로 비교적 높았고 NRMSE는 BiGRU-AM의 결과에 비해 0.4%p 감소하여 25%로 도출되었다. Well 2는 BiGRU-AMDC의 예측치 중 오차가 2~4 MMcf인 값이 다수 나타났으며, 특히 40개월부터의 값부터 그 빈도가 늘어 MAPE와 NRMSE는 각각 35.9%, 20%로 산출되었다. Well 10에서는 BiGRU-AMDC의 30개월까지의 초기 예측치가 1 MMcf 미만의 차이로 실측치에 가깝게 개선된 듯 하였으나, 이후 최대 약 12 MMcf 까지 차이가 나타나 MAPE는 감소 폭이 1.6%p로 그쳐 37%로 계산되었으며, NRMSE는 오히려 1%p 증가하여 27.5%로 BiGRU-AMDC 모델의 결과 중 가장 높은 오차를 보였다. 이러한 결과들은 시계열 자료를 동등하게 처리하는 BiGRU를 비롯한 RNN의 연산 방식에 의한 것으로 여겨진다. 생산이력, 월별 생산정 운영 일수, 생산감퇴특성은 시점에 따라 연속적인 변화가 나타나는 반면, 생산중단 기간은 일관성없이 산발적으로 분포하여 모든 자료를 동일한 방식으로 학습한다면 셰일가스의 불규칙한 생산 특성을 제대로 반영하지 못할 가능성이 있다. 특히 생산중단 기간은 셰일가스 생산 경향에 직접적으로 관련되므로 이를 사실적으로 예측에 고려하기 위한 추가 연구가 필요할 것이다.
예측성능평가 및 분석
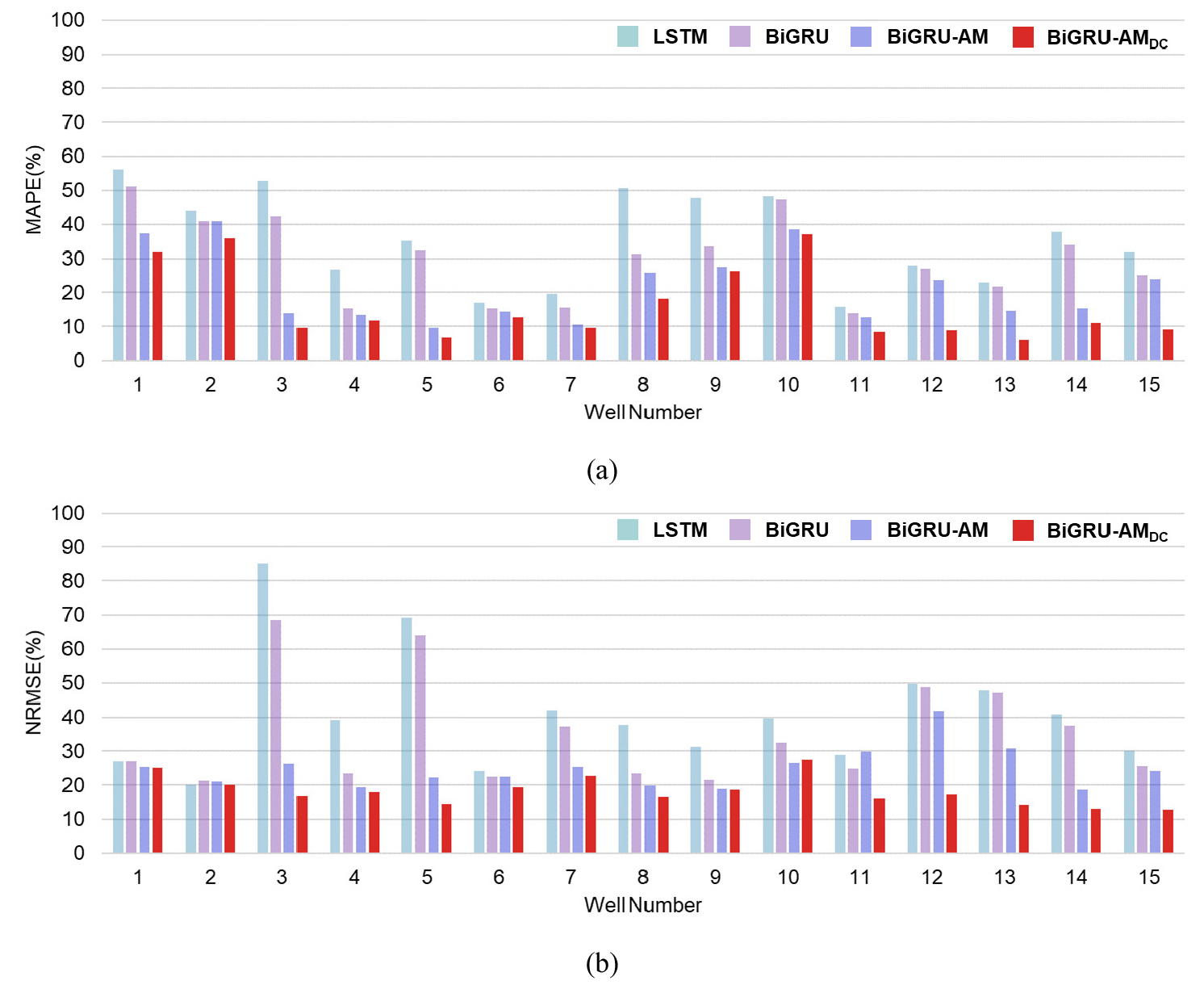
전체 테스트 생산정에서의 MAPE 및 NRMSE 수치가 LSTM, BiGRU, BiGRU-AM, BiGRU-AMDC 순으로 줄어드는 경향을 보였다(Fig. 11). LSTM의 MAPE 수치는 모든 생산정에 대해서 가장 높게 계산되었고 NRMSE는 BiGRU보다 1.2%p 정도로 미세하게 낮았던 Well 2의 경우를 제외한 모든 결과에서 최댓값으로 나타났다. 특히 Well 3의 결과에서 LSTM에 대비되는 BiGRU 신경망의 시계열 해석능력을 파악할 수 있었다. BiGRU-AM의 MAPE는 모든 생산정에서 BiGRU보다 감소하였으며, NRMSE 수치는 Well 11의 경우 5%p 상승하였으나 다른 결과에서 전반적으로 개선되어 AM에 의한 학습성능 향상 효과를 확인하였다. BiGRU-AMDC의 MAPE는 모든 생산정에서 가장 낮았고 NRMSE는 Well 10에서 BiGRU-AM보다 1%p 미세하게 높았던 결과를 제외한 모든 생산정에서 최솟값으로 계산되었다. 또한, Well 3, 5, 7, 11, 12, 13, 15의 7개 생산정에서 BiGRU-AMDC 모델의 MAPE가 10% 미만인 것으로 나타나 생산중단과 운영이 셰일가스 생산량의 감퇴특성에 미치는 영향을 효과적으로 생산거동 예측에 반영할 수 있음을 확인하였다.
각 예측 모델의 MAPE 및 NRMSE의 통계치를 도출하였으며(Table 2), Box plot을 통해 성능평가지표의 분포를 확인하였다(Fig. 12). BiGRU의 평균적인 MAPE 및 NRMSE는 각각 29.8%, 35%로 LSTM에 비해 약 6%p 더 우수한 것을 식별하였고 표준편차 계산 결과 BiGRU의 성능평가지표가 약 1.5%p 정도 더 균일한 것으로 파악하였다. 또한, BiGRU의 MAPE 최대치는 LSTM 보다 5%p 낮게 나타났고 NRMSE 최대치는 16.5%p 낮았다. BiGRU-AM과 BiGRU-AMDC의 예측 오차 분포는 BiGRU 모델의 결과에 비해 낮은 수준으로 나타났다. AM을 결합함으로써 MAPE와 NRMSE의 평균치는 각각 8.3%p, 10.2%p 감소하여 21.5%, 24.8%로 나타났으며, 생산감퇴특성을 추가 고려할 경우 각각 5.3%p, 6.6%p 하락함으로써 16.2%, 18.2%로 산출되어 예측치와 실측치 간의 오차가 점진적으로 완화되었다. 표준편차를 통해 BiGRU에 대비되는 BiGRU-AM 성능평가지표 변화를 분석한 결과 MAPE의 감소폭은 1.4%p로 큰 변화를 확인할 수 없었지만, NRMSE는 약 10%p 정도 감소하여 5.86%로 나타나 비교적 높은 신뢰도를 보였다. 또한, BiGRU-AM의 MAPE 및 NRMSE의 최대치가 BiGRU에 비해 각각 10.2%p, 26.6%p의 폭으로 줄어들어 41%, 41.9%로 나타나 전반적인 분포에서 상향으로 치우친 정도가 완화되어 모델의 신뢰도가 증진되었다. BiGRU-AMDC 모델의 MAPE 및 NRMSE의 표준편차는 각각 10.6%, 4.09%로 BiGRU-AM과 비슷한 수준이었으나, 최댓값, 최솟값, 중간값이 모두 감소하여 예측 오차가 비교적 낮은 범주에서 고르게 분포하였다. 특히 BiGRU-AM에 대비되는 BiGRU-AMDC의 최대 NRMSE 감소폭이 14.4%p에 달해 27.5%로 산출되어 전반적인 경향이 확연히 낮아졌다.
Table 2.
Statistical comparison of prediction performance among four model types
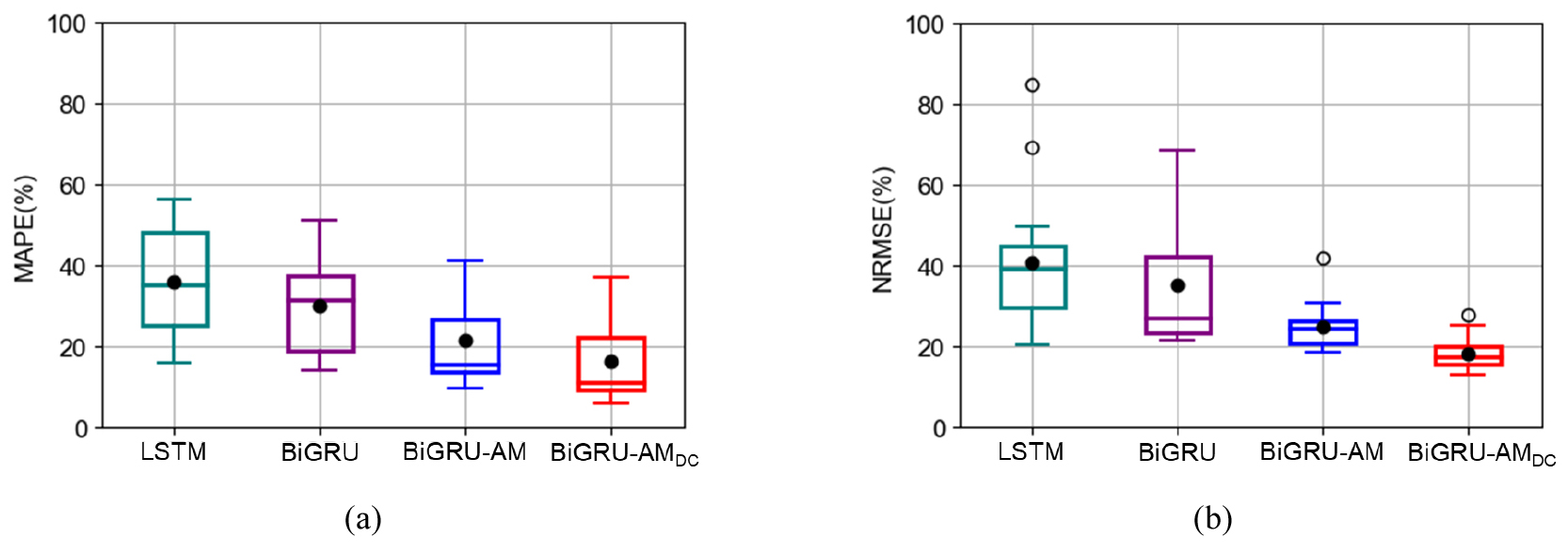
최종적으로 BiGRU-AMDC의 평균적인 MAPE 및 NRMSE 수치 16.2%, 18.2%는 LSTM에 대비하여 각각 19.5%p, 22.6%p 감소한 결과임을 확인하였다. AM을 BiGRU 신경망에 접목한 선택적 학습을 통해 LSTM과 BiGRU를 활용한 예측에서 상향 도출되어 한계가 드러났던 결과를 극복하였고 생산감퇴특성이 예측에 추가적으로 활용됨에 따라 부분적으로 나타났던 실제 생산량과의 차이를 줄여 BiGRU-AMDC 모델은 테스트 생산정 자료에서 일관되고 높은 정확도의 예측성능 도출이 가능함을 파악하였다. 이를 통해 풍부한 자료 바탕의 학습과 검증뿐만 아니라 모델을 구성하고 있는 신경망의 구조나 생산 영향인자의 추가 고려 여부도 예측 정확도 증진의 핵심으로 작용하는 것을 확인하였다.
결 론
기존의 기계학습 기법 기반의 유·가스 생산량 예측 연구에서는 LSTM이 주로 활용되었으나, 순차적인 자료 처리 과정 중 하이퍼파라미터 설정에 따라 초기 훈련정보가 소실될 가능성이 있어 셰일가스의 불규칙적인 생산 경향 학습에 불확실성이 존재한다. 이 연구에서는 미국 Barnett Shale에서의 셰일가스 생산자료를 대상으로 양방향의 정교한 시계열 특성 학습이 가능한 BiGRU에 생산정의 생산이력, 생산중단 기간 및 월별 생산정 운영 일수로 구성된 입력자료를 적용하여 생산량 예측을 수행하였으며, LSTM과의 비교를 통해 BiGRU의 셰일가스 생산거동 학습에 대한 적합성을 판단하였다. 이후 BiGRU-AM 모델을 활용하여 셰일가스 생산량에 영향력이 높은 요인을 선택적으로 학습함으로써 모델의 신뢰성과 정확도를 향상시켜 다양한 생산정 자료에서의 성능개선을 확인할 수 있었다. 이를 통해 모델 학습의 효율성 증대를 위한 AM 결합의 필요성을 파악할 수 있었으며, 초기 훈련정보 소실 문제를 방지하여 신뢰성 있는 장기의 생산량 예측이 가능함을 확인하였다. 또한, 생산감퇴특성을 반영한 BiGRU-AMDC 모델을 통해 실제 감퇴 거동과 예측치 사이의 차이를 줄였다. 이는 AM이 결합된 BiGRU 신경망의 입력 정보 처리 중 실제의 경향에서 벗어난 부분이 생산감퇴특성에 의해 보완되어 나타난 결과로 사료된다.
향후 이 연구에서 제시한 예측성능 개선 방안과 더불어 입력인자 간의 상관성을 바탕으로 생산정 자료를 선별하는 비지도 학습 기법이나, 추가적인 시계열 특성 고려가 가능한 기계학습 알고리즘을 예측 모델 구축에 이용한다면 복잡한 생산 경향 속에서 높은 정확도의 예측이 가능할 것이다. 또한, 이는 셰일가스 저류층의 생산성 파악을 위한 효과적인 기계학습 접근법으로 활용됨으로써 신규 및 생산 중인 수평정의 적절한 개발 전략과 생산 계획 수립에 활용 가능할 것이다.
