

서 론
LSTM 기반 생산량 예측모델 설계
장단기기억 신경망(LSTM)
LSTM 모델 설계
LSTM 기반 셰일가스 생산량 예측
연구대상 지역 및 자료 전처리
생산이력의 길이에 따른 LSTM 모델의 생산량 예측
LSTM 모델과 Arps Hyperbolic의 예측성능 비교
생산관련인자를 이용한 LSTM 기반 생산량 예측
결 론
서 론
셰일가스(shale gas)가 부존되어 있는 저류층은 유체투과도가 낮아 수압파쇄(hydraulic fracturing)로부터 발생한 균열을 통해 생산이 이루어지며, 수압파쇄 직후 생산 초기에는 가스 생산량과 생산량의 감퇴경향이 크게 나타나고 시간이 지남에 따라 감퇴율이 매우 작아지고 장기간의 천이유동(transient flow)이 발생한다(Kim et al., 2014, Luo and Su, 2022). 이러한 셰일 저류층에서의 특수한 유동 특성과 수압파쇄 인자, 유정완결(well completion) 조건 등과 같이 복합적인 영향을 미치는 생산관련인자(production-related factors)로 인해 생산량 예측에 어려움이 존재하며, 각 생산정은 동일한 셰일층에 위치하더라도 생산관련인자에 따라 저류층의 생산성에 영향을 미쳐 생산거동 변화의 범주가 크다(Kang et al., 2017; Shin et al., 2021). 일반적으로 생산량 예측 시 과거 생산이력(production history)을 이용하는 생산감퇴곡선분석법(Decline Curve Analysis, DCA)이 활용되고 있으나, 이는 생산운영조건을 반영할 수 없다는 한계가 존재한다(Li et al., 2020). 또한, DCA 기법 중 널리 활용되고 있는 Arps(1945) 방정식은 경계영향유동(boundary dominated flow)을 가정하여 장기간의 천이유동이 발생하는 셰일 저류층에 적용할 경우 생산량을 과대예측하는 등의 부정확한 결과가 나타날 수 있으며(Kanfar and Wattenbarger, 2012; Paryani et al., 2016; Tan et al., 2018), 경우에 따라 Arps 방정식의 감퇴지수(decline exponent, b)가 음의 값으로 나타나 생산량이 증가하는 비현실적인 결과가 도출될 수 있다(Mosobalaje et al., 2014).
석유 E&P 산업에서도 데이터 기반 분석(data-driven analysis)이 적용되고 있으며, 셰일 저류층의 생산량 예측에 관한 정확도를 높이기 위해 자료로부터 특징을 도출하여 학습과 예측을 수행할 수 있는 기계학습(machine learning)을 활용하고 있다. 셰일가스의 생산량과 저류층 물성, 수압파쇄 인자 등의 자료를 바탕으로 인공신경망(Artificial Neural Networks, ANN), 랜덤 포레스트(Random Forest, RF) 등을 적용하여 특정 시점의 누적생산량(cumulative production)과 궁극가채량(Estimated Ultimate Recovery, EUR)을 예측하는 다양한 연구가 진행된 바 있다(Alabboodi and Mohaghegh, 2016; Wang et al., 2019; Biswas, 2020). Luo et al.(2019)은 미국 Bakken Shale에 위치한 생산정들의 저류층 물성 및 수압파쇄 인자 등을 입력하여 생산 초기 1년간의 누적생산량을 예측할 수 있는 ANN 모델을 구축하였고 해당 모델이 다중회귀에 비하여 높은 예측성능을 보임을 확인하였다. Shin et al.(2021)은 미국 Eagel Ford의 현장자료를 바탕으로 주성분분석(principal component analysis)을 수행하여 다수의 입력인자 중 주요인자를 파악했을 뿐만 아니라 퍼지군집(fuzzy clustering)을 활용하여 생산특성에 따른 그룹을 분류하고 이를 바탕으로 신규 유정의 생산량을 예측할 수 있는 ANN 모델을 개발하였다. Oh et al.(2021)은 미국 Barnett Shale의 수평정 자료를 취득하여 일정 생산량 이하의 생산이력을 가지는 경우와 최대 생산량 이전의 생산이력을 제거하는 등 자료를 전처리하였으며, 저류층 물성, 유정완결 조건, 생산정 정보 및 생산량 등을 입력자료로 하여 셰일가스의 EUR을 예측할 수 있는 RF 모델을 구축하였다.
최근에는 시간에 따른 생산량의 변화를 예측하기 위해 시계열 자료 처리에 이점이 있는 순환신경망(Recurrent Neural Network, RNN) 기반의 딥러닝(deep learning)이 적용되고 있다. 이 중에서도 장기기억을 보존함으로써 정확도 높은 시계열 예측이 가능한 장단기기억(Long Short-Term Memory, LSTM) 구조를 바탕으로 생산량 예측모델을 제시하는 연구가 활발히 진행되고 있다(Zhan et al., 2019; Song et al., 2020). Kocoglu et al.(2021)은 미국 Marcellus 셰일층을 대상으로 LSTM을 비롯하여 양방향 LSTM(Bidirectional Long Short-Term Memory, Bi-LSTM)과 게이트 순환 유닛(Gated Recurrent Unit, GRU)을 활용하여 생산 초기 24개월간의 셰일가스 생산량을 입력하여 이후 25~64개월 월간 생산량을 예측하였다. Lee et al. (2019)은 캐나다 Duvernay 층의 현장자료를 바탕으로 셰일가스 생산량 예측을 위한 LSTM 기반 예측모델을 구축하였으며, 생산이력 중 생산중단(shut-in)이 발생한 기간 내 자료를 제외하여 생산이력을 전처리하고 생산중단 기간에 대한 시계열 자료를 추가로 구축하는 등의 생산이력에 관한 전처리및 특징 추출을 통해 생산량 예측모델의 성능 개선이 가능함을 파악하였다. Li et al.(2020)은 LSTM과 GRU를 통해 일정 길이의 생산이력 자료를 입력하여 직후에 해당하는 단일 시점의 생산량 예측하고, 예측한 값을 실제값으로 가정하여 입력자료로 이용함으로써 장기의 석유 생산량 예측이 가능함을 확인하였다. 또한, 생산이력 외에도 생산중단 기간, 튜빙 압력(tubing pressure), 초크 사이즈(choke size) 등의 생산운영조건을 추가로 사용하여 생산량 예측성능을 높일 수 있음을 파악하였으며, RF를 이용하여 예측 오차와 생산관련인자 간 관계를 학습시켜 예측모델의 오차를 줄였다. 이러한 연구들에서는 순환신경망 기반의 모델을 활용하여 생산량을 예측할 경우, 생산량만을 이용하거나 생산운영조건과 같은 시계열 자료를 함께 활용하여 유 ․ 가스의 생산량 예측성능을 개선하고자 하였다. 반면에 셰일 저류층의 생산거동에 복합적인 영향을 미치는 생산관련인자를 동시에 고려할 수 있는 방법에 관해서는 연구가 부족한 상황이다.
이 연구에서는 셰일 저류층에서의 시간에 따른 생산량 변화를 예측하고자 하였으며, 생산이력만을 사용한 경우와 생산관련인자를 함께 활용한 경우를 나누어 LSTM 모델을 구축하였다. 생산이력을 이용한 경우 활용 가능한 생산이력의 길이에 따른 생산량 예측을 수행하고자 하며, 일반적으로 생산량 예측에 활용하는 Arps 방정식의 생산량 예측 결과와 비교를 통해 셰일가스 생산량 예측모델로써 LSTM 모델의 활용 가능성을 확인하고자 한다. 또한, 생산관련인자를 추가 입력인자로 사용하여 구축한 LSTM 기반 모델의 예측성능 개선 여부를 파악하고자 한다.
LSTM 기반 생산량 예측모델 설계
장단기기억 신경망(LSTM)
단순한 구조의 RNN은 정보의 순환적인 흐름을 바탕으로 과거 시계열 자료의 특징을 고려하여 예측치를 도출할 수 있다(Ji et al., 2021). 하지만, 시계열 자료가 많아짐에 따라 발생하는 기울기 소실 문제로 인해 예측에 있어 어려움이 존재하며, 초기의 입력정보가 후기의 예측 결과에 제대로 반영되지 않아 학습성능이 저하되는 문제가 발생한다(Alom et al., 2019; Kocoglu et al., 2021). 이를 보완하고자 Hochreiter and Schmidhuber(1997)에 의해 LSTM이 제안되었으며, 이는 cell state(C), hidden state(H)를 통해 이전 시점으로부터 장기, 단기상태의 정보가 전달되어 기울기 소실 문제를 극복하였다(Fig. 1). LSTM의 내부에서는 특정 시점의 입력자료(X)와 이전 시점의 장단기상태의 정보가 시그모이드(sigmoid, 𝜎), 하이퍼볼릭 탄젠트(hyperbolic tangent, tanh)함수를 거치며 출력값과 다음 시점으로 전달할 장단기 정보를 도출하게 된다. 이러한 LSTM 신경망은 장기 시계열에 대한 학습이 가능하다는 이점을 바탕으로 유 ․ 가스 개발 시 생산량, 정두압(wellhead pressure), 왁스 집적 및 저류층 내 수포화율 예측 등의 연구에 활용되고 있다(Ki et al., 2019; Lee et al., 2019; Ji et al., 2021; Yao et al., 2021).
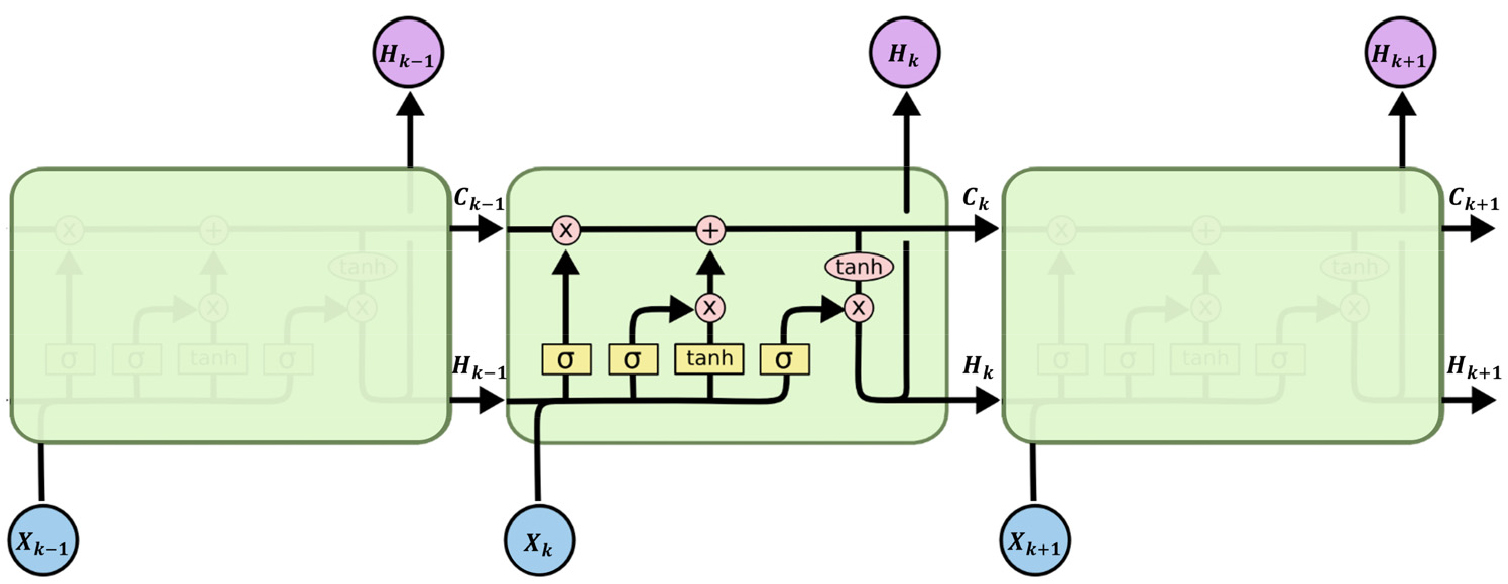
Fig. 1.
Schematic of LSTM cell structure representing the flow of information for each timestep (modified from Olah (2022)).
LSTM 모델 설계
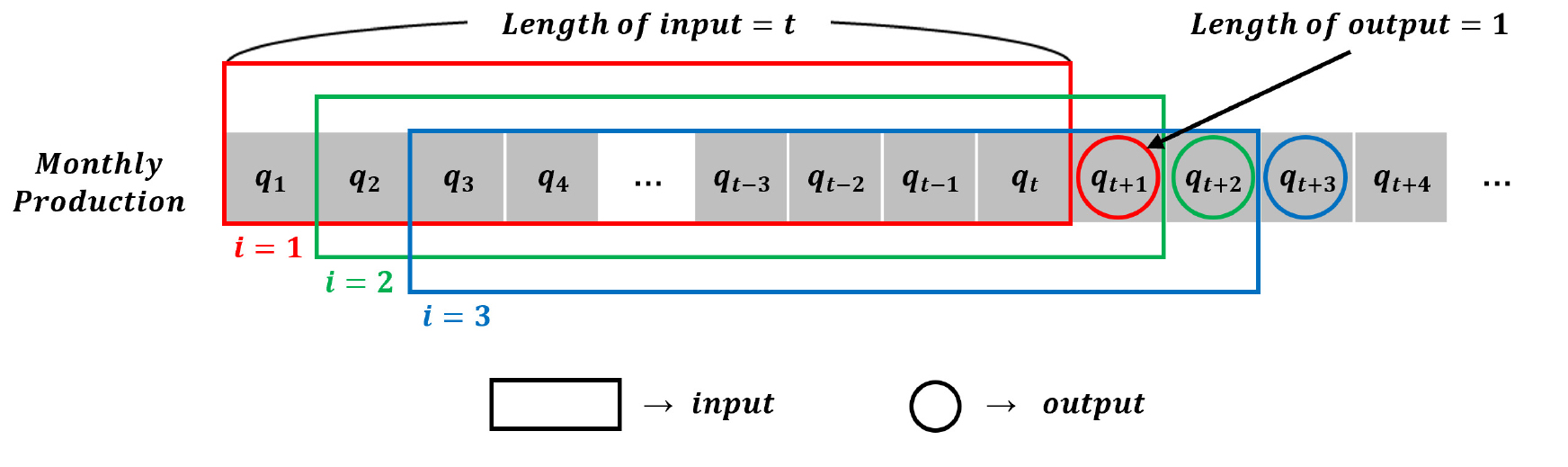
일반적으로 RNN 모델은 목적에 따라 입 ․ 출력자료를 다양한 형태로 구성할 수 있으며, 유 ․ 가스정 생산량 예측에서는 일련의 시계열을 입력하여 하나의 출력을 예측하는 many-to-one 방식이 적용되고 있다(Ki et al., 2019; Li et al., 2020). 이 연구에서는 개월 간의 생산량을 입력하여 직후의 단일 시점 생산량을 출력할 수 있는 LSTM 예측모델을 MathWorks社의 MATLAB R2022a를 사용하여 설계하였으며, 테스트 시에는 첫 번째 예측에서만 실제 생산량을 사용하고 이후에는 예측한 생산량을 실제 생산량으로 가정하여 입력자료로 활용하는 방식을 반복함으로써 장기간의 생산량을 예측하고자 하였다(Fig. 2).
이 연구에서는 예측모델의 구조와 학습 관련 hyperparameter를 Table 1과 같이 고정하였다. 또한, 예측모델의 복잡도를 낮추어 과적합(overfitting)을 방지하고 예측성능을 향상시킬 수 있도록 LSTM층의 수, Dropout의 비율, L2 Regularization의 값을 대상으로 총 3개의 hyperparameter를 최적화하고자 하였다. 해당 hyperparameter 최적화 시, 과거의 탐색을 통해 습득한 사전지식을 바탕으로 다음 탐색 지점을 선정하여 효율적으로 해를 도출할 수 있는 베이지안 최적화(bayesian optimization)를 적용하였으며, 평균 제곱근 오차(Root Mean Square Error, RMSE)를 최소화할 수 있는 조건을 기준으로 값을 도출하고자 하였다.
LSTM 기반 셰일가스 생산량 예측
연구대상 지역 및 자료 전처리
2021년 12월을 기준, Appalachia 분지는 미국 내 전체 천연가스 생산량 중 약 31%를 차지하고 있으며(EIA, 2022), 해당 분지 내 위치한 Marcellus Shale은 Pennsylvania, West Virginia, Ohio, New York 주에 약 140,000 km2의 면적에 걸쳐 분포하고 있다(Gihm et al., 2011). 해당 지층에는 500 Tcf(trillion cubic feet) 이상의 원시부존량이 존재하고 있으며(Engelder and Lash, 2008), Enverus의 Drillinginfo를 통해 Pennsylvania 주에 위치한 셰일가스 수평 생산정의 생산이력 자료를 획득하였다.
이 연구에서는 예측모델 구축 시 최대생산량을 기점으로 지속적인 감퇴경향이 나타나는 자료를 활용하기 위해 기존의 연구에서 수행된 전처리 방식을 고려하여 취득한 현장자료를 아래와 같은 조건을 바탕으로 전처리를 수행하였다.
1. 최대 생산량(initial peak rate) 이전의 생산이력 제거
2. 생산이력이 48개월보다 짧은 생산정 제외
3. 주 생산유체는 가스로 1 MBOE 이하의 월간 생산량을 포함하는 생산정 제외
4. 48개월의 전체 생산이력 기준, 매월의 생산량에 대하여 이상치(outlier)로 분류되는 생산량을 기록한 생산정 제외
5. 직전 시점 대비 생산량이 300% 이상 증가하여 일정한 감퇴경향을 보이지 않는 생산정 제외
이와 같은 자료 전처리 과정을 통해 48개월간의 생산이력을 가진 총 242개의 생산정 자료를 확보하였으며, 전체 자료를 무작위로 배열한 뒤 학습(195개), 검증(24개), 테스트(23개) 자료로 나누었다.
생산이력의 길이에 따른 LSTM 모델의 생산량 예측
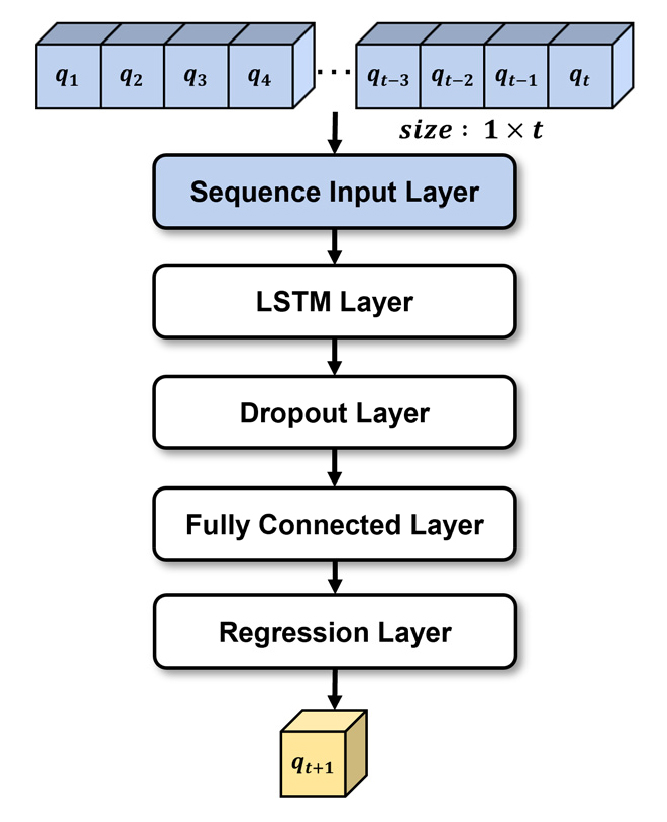
이 연구에서는 생산초기로부터 특정 생산시점까지의 활용 가능한 전체 생산이력을 사용하여 셰일가스 생산량을 예측할 수 있는 LSTM 모델을 구축하고 예측성능을 확인하고자 6, 12, 18, 24개월의 생산시점을 가정하여 서로 다른 길이의 생산이력을 입력자료로 활용하였다. 모델 구축 시 생산 변동성이 큰 셰일층의 특성을 고려하고자 여러 생산정의 다양한 생산거동을 하나의 모델에 학습시켜 다수의 생산정에 활용할 수 있도록 하였다. 활용 가능한 생산이력의 길이에 따라 학습, 검증, 테스트에 이용한 자료의 수는 Table 2와 같으며, 학습 및 검증 자료를 바탕으로 LSTM층 수, Dropout 비율, L2 Regularization의 값을 최적화하여 총 4개의 LSTM 예측모델을 구축하였다(Table 3). 각 모델은 시계열 자료 입력층(sequence input layer), LSTM층, Dropout층, 완전 연결층(fully connected layer)과 회귀를 통한 출력층으로 구성하였다(Fig. 3).
Table 2.
Data number depending on the length of production history
| Type | Length of production history (Months) | |||
| 6 | 12 | 18 | 24 | |
| Training | 8,190 | 7,020 | 5,850 | 4,680 |
| Validation | 1,008 | 864 | 720 | 576 |
| Test | 966 | 828 | 690 | 552 |
Table 3.
Optimized hyperparameter of LSTM models using production history
| Hyperparameter | Length of production history (Months) | |||
| 6 | 12 | 18 | 24 | |
| Depth of LSTM layer with dropout | 1 | |||
| Dropout rate | 0.0087 | 0.0033 | 0.0182 | 0.3847 |
| L2 regularization | 0.0174 | 0.0053 | 0.0003 | 0.0009 |
LSTM 예측모델에 테스트 자료를 적용하여 미래의 생산거동을 추정하였으며, 각 생산정에 대한 예측성능을 정량적으로 분석하기 위하여 식 (1)과 같은 평균 절대비 오차(Mean Absolute Percentage Error, MAPE)를 활용하였다.
여기서, 는 LSTM 모델을 통해 도출한 번째의 예측값 즉, 예측한 생산량에 해당하며, 는 실제 생산량, 은 예측의 총횟수를 나타낸다.
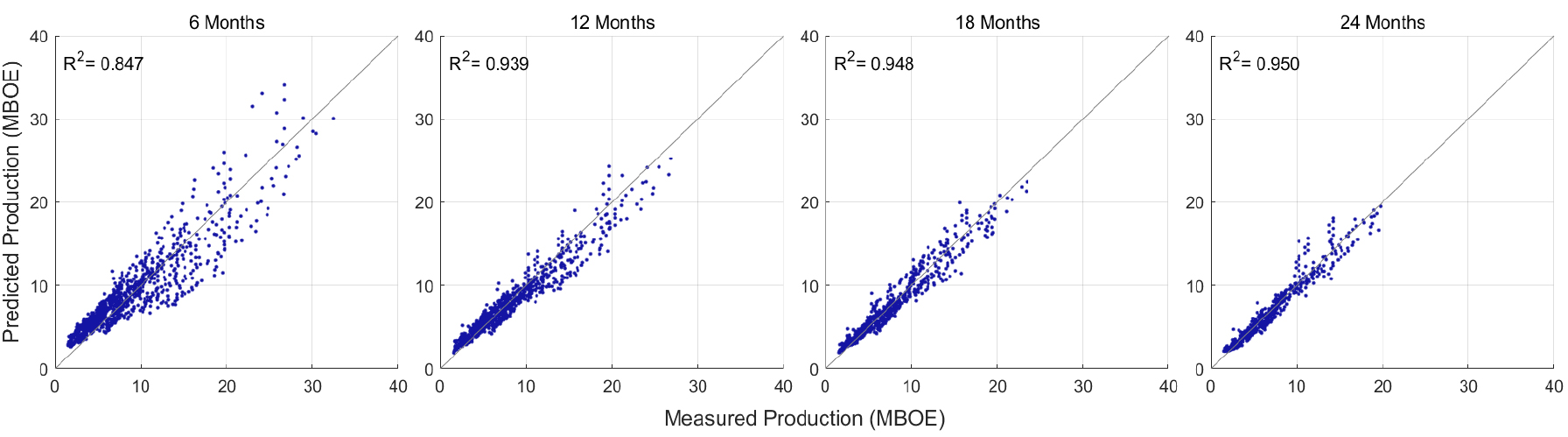
Fig. 4와 같이 활용 가능한 생산이력이 많아질수록 다량의 자료를 이용할 수 있어 MAPE가 줄어드는 경향을 보였으며, 급격히 감소하는 생산거동을 보이는 경우에 예측에 한계가 있음을 파악하였다. 이는 LSTM 모델이 주어진 입력자료를 기반으로 생산량을 예측하기에 시계열 자료의 마지막 시점에 해당하는 생산량이 예측에 주요한 영향을 미치기 때문인 것으로 사료된다. 이처럼 활용 가능한 생산이력의 길이에 따라 예측성능의 차이가 존재하지만, LSTM 모델이 다수 생산정의 감퇴거동을 학습하여 새로운 생산정에 대한 셰일 저류층의 생산거동 예측이 가능함을 확인하였다.
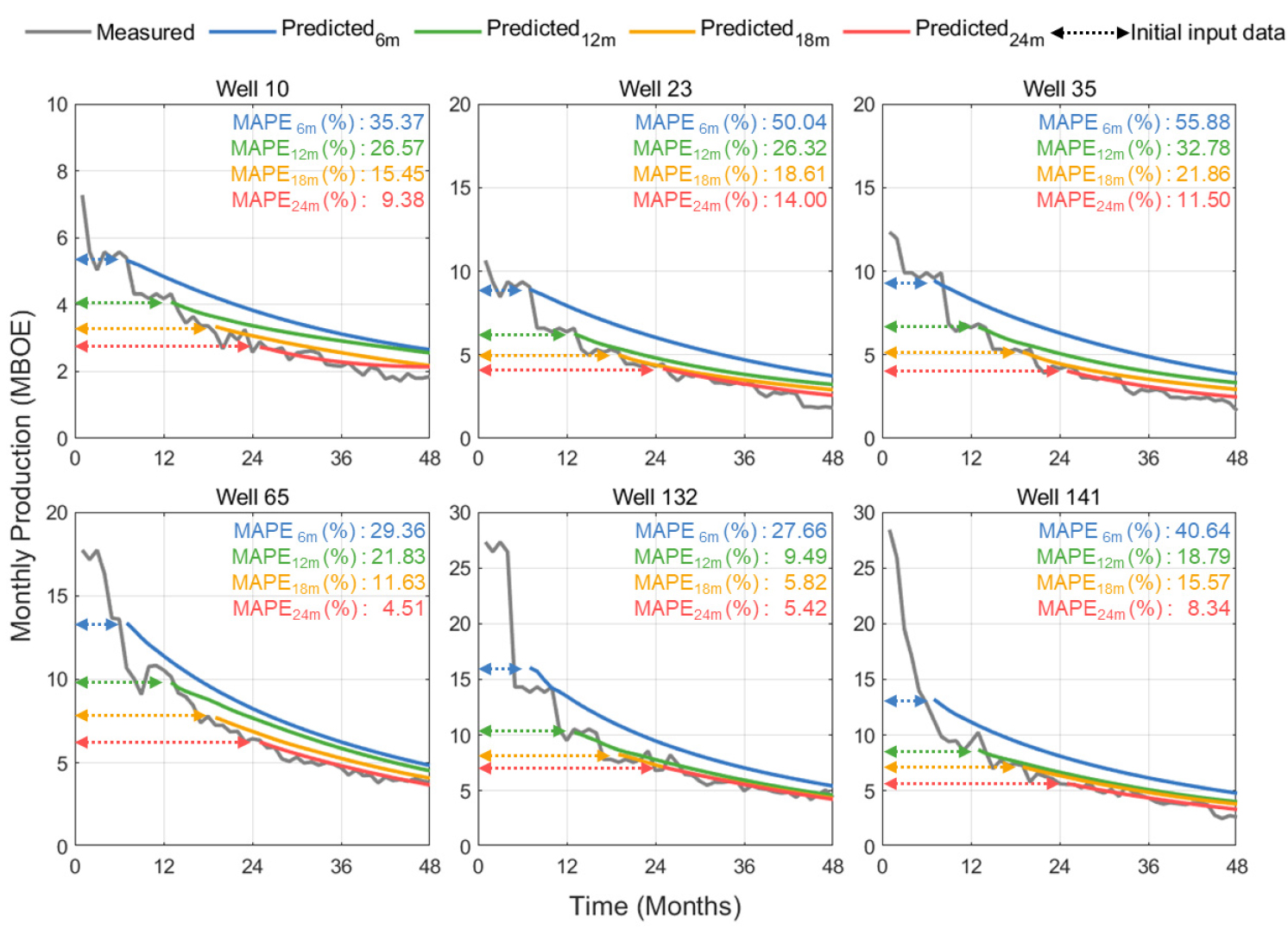
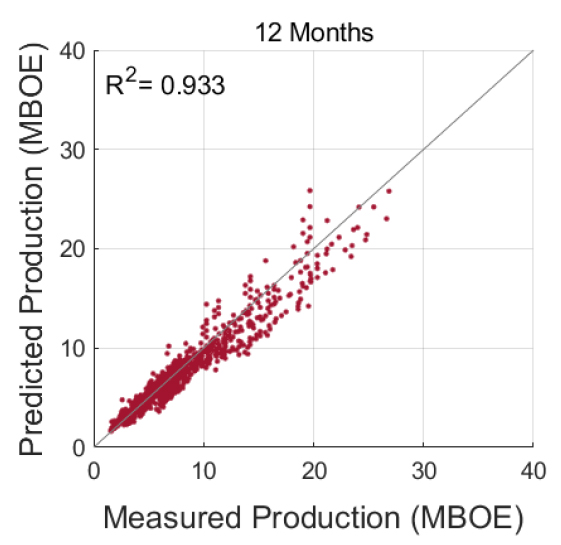
추가적으로 전체 테스트 자료에 대한 실제 생산량과 예측한 생산량을 비교하고자 결정계수(coefficient of determination, R2)를 이용하였다(Fig. 5). 생산 시작으로부터 12, 18, 24개월의 생산이력을 이용한 경우 약 0.93 이상의 R2을 보이며 실제 생산량과 유사한 예측치를 도출할 수 있었으며, 6개월의 생산이력을 활용한 모델의 예측 결과는 R2이 약 0.84로 비교적 낮게 나타났다.
LSTM 모델과 Arps Hyperbolic의 예측성능 비교
현장에서 생산량 예측 시 일반적으로 활용되고 있는 Arp 방정식 중 Hyperbolic의 감퇴지수는 의 범위를 가지고 있지만, Beyond Hyperbolic이라는 개념으로 인 셰일 저류층에서도 적용되고 있다(Rezaee, 2015; Gupta et al., 2018). 이러한 Hyperbolic과 구축한 LSTM 모델 간 예측성능을 비교하고자 테스트 자료에 대한 예측 결과의 MAPE의 통계치를 도출하였다(Table 4). 6, 12개월의 생산이력을 활용하여 Hyperbolic을 적용할 경우 감퇴지수가 음수로 나타나 생산량이 비정상적인 값으로 도출이 되어 추정에 어려움이 존재하였으며, 24개월의 생산이력을 활용하였을 때 18개월보다 MAPE의 평균치가 감소하였다. 하지만, 24개월의 생산이력을 기준으로 Hyperbolic은 LSTM 예측모델에 비하여 상대적으로 높은 평균 오차율을 가질 뿐만 아니라 최댓값 및 최솟값이 약 8배의 차이를 보이며 예측성능에 있어 큰 편차가 발생하였다. 이렇듯 생산이 이루어지고 있는 초기에 LSTM 모델이 Hyperbolic보다 낮은 오차율의 예측 결과를 도출할 수 있음을 확인하였다.
Table 4.
MAPE of LSTM model and Hyperbolic depending on the length of production history
생산관련인자를 이용한 LSTM 기반 생산량 예측
생산이력과 같이 시계열 자료만을 활용할 수 있는 LSTM에 특징 자료 입력층(feature input layer)을 결합하여 생산관련인자를 고려할 수 있는 생산량 예측을 수행하고자 하였다. 이때, 12개월의 생산이력만을 가지고 있는 생산 초기의 상황을 가정하여 예측모델을 설계하였으며, 최적화된 모델의 LSTM층 수, Dropout의 비율과 L2 Regularization의 값은 Table 5와 같고 이외의 hyperparameter의 경우는 Table 1과 동일하게 설정하였다. 생산이력과 생산관련인자는 각각 시계열 자료 및 특징 자료 입력층을 통해 예측모델에 입력된 후 완전 연결층을 통과하여 총 2개의 출력값을 도출하도록 구성하였다(Fig. 6). 이후 2개의 출력값은 결합층(concatenation layer)을 통해 하나의 벡터로 결합되고 다시 완전 연결층을 지나 최종적으로 다음 시점의 생산량을 예측할 수 있다.
Table 5.
Optimized hyperparameter of LSTM model using production history and production-related factors
| Hyperparameter | Value |
| Depth of LSTM layer with dropout | 1 |
| Dropout rate | 0.0166 |
| L2 regularization | 0.0019 |
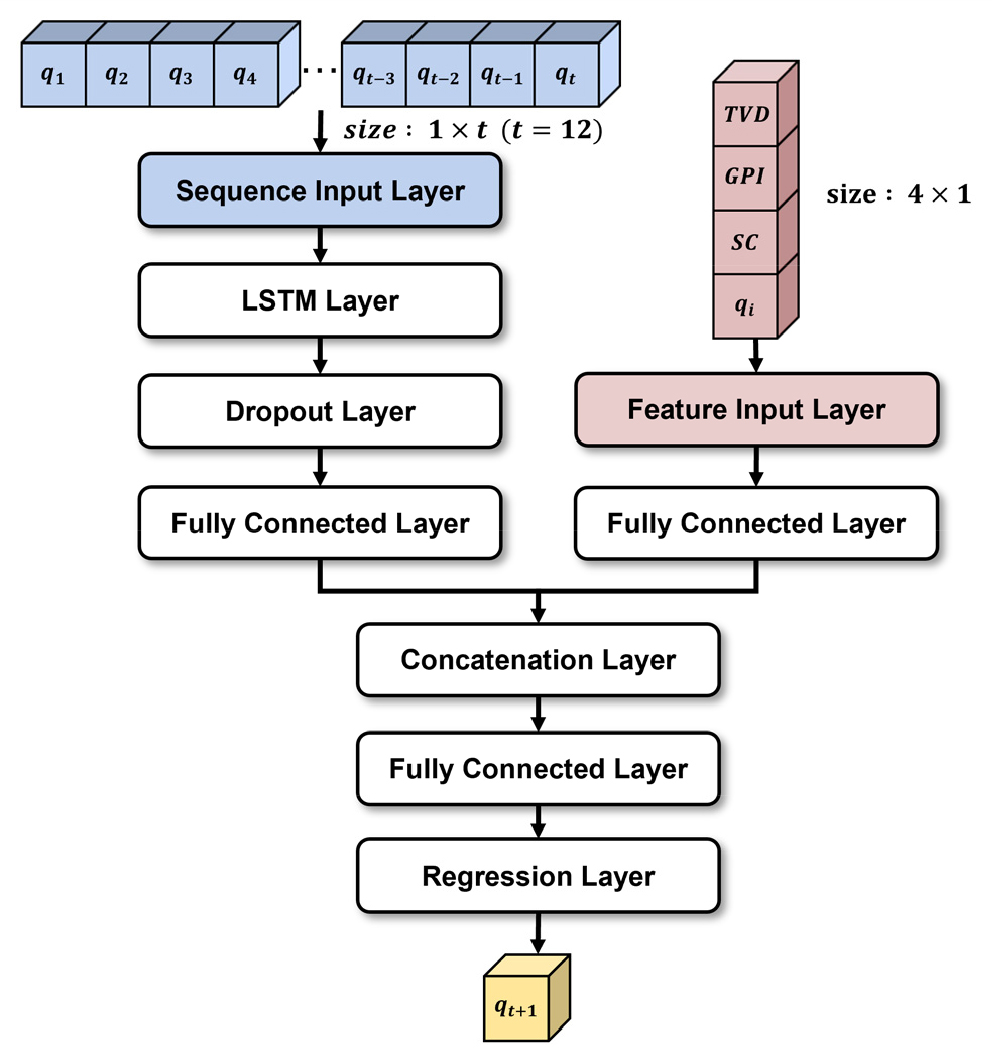
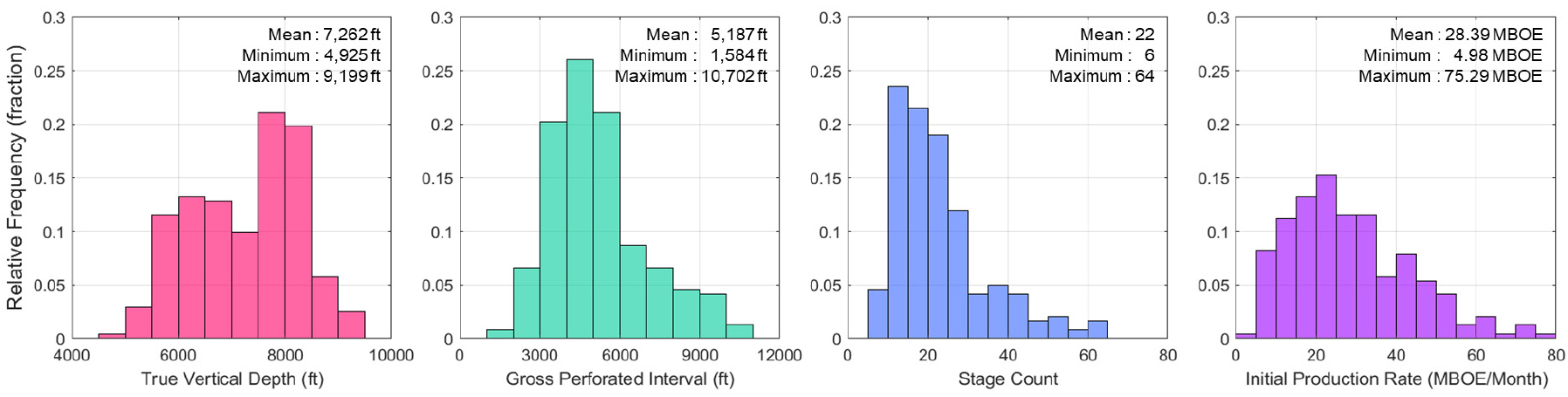
생산관련인자의 경우 취득 가능한 현장자료 중 생산정의 수직 시추 깊이를 나타내는 정보인 실수직심도(True Vertical Depth, TVD), 시추 구간 내 총 천공 길이에 해당하는 유정완결 조건인 총천공간격(gross perforated interval), 수평정 내에서의 수압파쇄 횟수(stage count)를 활용하였다. 또한, 생산량 예측을 위한 반복적인 계산이 수행됨에 따라 생산정의 주요 특성으로 볼 수 있는 초기 생산량(initial production rate, )에 대한 정보를 잃어버리기에 이를 추가하여 총 4가지의 생산관련인자를 이용하였다. 각 생산관련인자 간에는 수치의 크기나 범위에 차이가 존재하며(Fig. 7), 이로 인해 예측모델의 학습성능 저하가 발생할 수 있기에 학습자료 기준 각 인자의 최대값 및 최소값을 바탕으로 모든 값을 0~1 사이로 정규화(normalization)한 후 입력자료로 활용하였다.
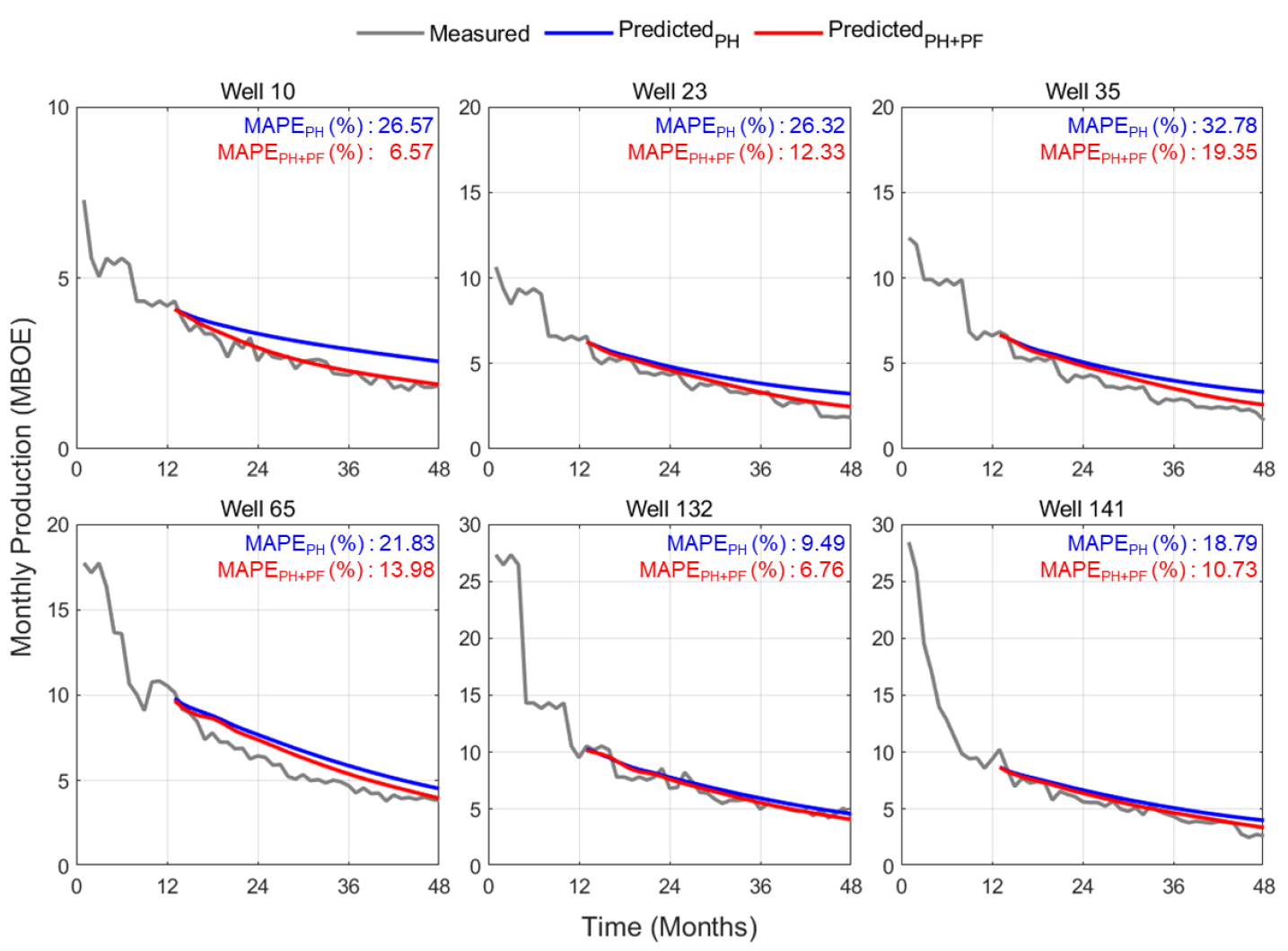
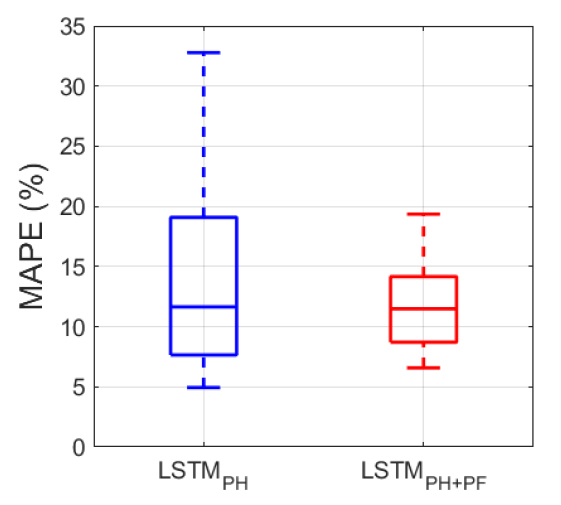
생산이력과 생산관련인자를 활용한 LSTM 모델(LSTMPH+PF)을 이용하여 테스트 자료를 바탕으로 생산량을 예측하였다. 입력자료에 따른 예측모델의 성능 개선여부를 파악하기 위하여 LSTMPH+PF 모델과 12개월의 생산이력만을 이용한 LSTM 모델(LSTMPH) 간 생산량 예측 결과를 비교하였다(Fig. 8). 비교적 생산량을 크게 예측하였던 LSTMPH와 달리 LSTMPH+PF의 예측 결과는 실제 생산경향에 가까워지는 것을 확인할 수 있었다. 또한, 전체 테스트 자료에 관한 LSTMPH+PF의 R2은 0.933으로 LSTMPH와 유사하였으나(Fig. 9), 각 모델의 MAPE는 평균적으로 LSTMPH가 약 14.02%, LSTMPH+PF는 약 11.89%로 생산관련인자를 이용한 경우 오차율의 변동 폭이 작아진 것을 알 수 있다(Fig. 10). 이와 같은 결과를 종합해 볼 때, 생산관련인자를 추가 입력자료로 사용할 경우 테스트 자료에 대한 LSTM 모델의 전반적인 오차율을 개선할 수 있었으나, 일부 생산정에서는 MAPE가 증가하였다. 이는 생산변동성이 큰 셰일가스의 특성에 기인한 것으로 사료되나, 생산이력 내 생산량의 크기 및 감퇴경향를 고려한 추가적인 분석이 필요할 것으로 보인다. 또한, 각 생산정의 다양한 감퇴거동으로 인하여 단일의 예측모델로 전체 테스트 생산정에 대한 예측 결과를 동시에 개선하기 어려운 것으로 생각되며, 생산이력의 감퇴특성 또는 생산관련인자의 특징을 바탕으로 생산정을 군집화하여 예측모델을 구축한다면 예측성능을 높일 수 있을 것으로 기대된다.
결 론
유 ․ 가스전에서의 생산량 예측 시 현장에서 적용되고 있는 Arps 방정식은 장기간의 천이유동이 발생하는 셰일 저류층에 적용할 경우 과대 혹은 과소 예측하는 결과가 도출될 수 있다. 이 연구에서는 생산량의 변동성이 큰 셰일가스 생산량을 예측하기 위하여 LSTM 기반의 모델을 구축하였으며, 입력인자의 구성에 따른 예측성능을 확인하였다. 생산이력을 활용한 결과 LSTM 예측모델이 다수의 생산정을 바탕으로 생산감퇴를 학습함으로써 셰일 저류층의 생산거동을 모사할 수 있음을 확인하였으며, 활용 가능한 생산이력이 늘어날수록 신뢰할 수 있는 예측 결과를 도출할 수 있음을 파악하였다. 또한, Arps Hyperbolic의 적용이 어려운 6, 12개월과 같은 생산 초기에 LSTM 모델을 통해 생산량 예측이 가능함을 파악하였으며, 셰일가스 생산량 예측 시 LSTM 예측모델의 활용 가능성을 확인할 수 있었다. 생산관련인자를 추가로 활용한 LSTM 모델의 경우 예측한 생산거동이 실제 생산량과 유사한 경향을 보였으며, LSTM 모델의 내부적인 연산 및 학습 과정에 의해 생산량 예측 시 생산관련인자가 개별 생산정의 특성을 반영하여 생산량 예측의 오차를 보정하는 역할을 한 것으로 사료된다.
기존의 연구에서는 생산량 정보, 생산관련인자를 활용하여 궁극가채량 및 누적생산량을 예측하거나 생산이력 및 생산운영조건과 같은 시계열 자료를 바탕으로 시간에 따라 변화하는 생산량을 추정하였으나, 본 연구에서는 생산량 예측에 있어 생산이력뿐만 아니라 생산정의 생산관련인자를 반영하였다는 의의가 있다. 이 연구에서는 제한적인 현장자료로 인하여 생산운영조건과 저류층 물성 등과 같이 생산량에 직 ․ 간접적으로 영향을 미치는 다양한 인자를 분석에 반영하지 못하였으나, 취득한 생산관련인자를 활용하여 예측모델의 성능이 개선되는 것을 파악하였다. 추후 생산관련인자의 영향 파악을 위한 추가적인 분석이 필요할 것으로 보이며, 다양한 생산관련인자를 활용하여 연구에서 제안한 방식을 통해 LSTM 기반의 예측모델을 구축한다면 신뢰성 있는 예측 결과를 도출할 수 있을 것으로 사료된다.
