

서 론
4차 산업혁명
4차 산업혁명의 재해석
시민사회와 공공기술의 공진화
GeoCPS
스마트 마이닝과 GeoCPS
ISA-95 레벨과 마이닝 발전 단계
GeoAI
AI와 지질자원 분야 활용 사례
Why GeoAI, not AI
물리모델과 AI의 결합: 이론기반 데이터과학모델
결 론
서 론
세계경제포럼(WEF)에서는 2016 다보스포럼을 통해 현재 제 4차 산업혁명 단계에 접어들고 있으며 미래에 혁신적이고 파괴적인 변화를 가져올 것이라는 점을 강조한 바 있다(Schwab, 2016). 또한 4차 산업혁명을 주도하는 혁신기술로 인공지능(Artificial Intelligence, AI), 메카트로닉스, 사물인터넷(Internet of Things, IoT), 3D 프린팅, 나노기술, 바이오기술, 신소재기술, 에너지저장기술, 퀀텀컴퓨팅 등을 지목한 바 있다. 한편, KCERN1)에서는 4차 산업혁명을 ‘인간을 위한 현실과 가상의 융합’ 혁명으로 정의하고, 4차 산업혁명의 현실과 가상의 융합과정을 데이터화, 정보화, 지능화, 스마트화라는 4단계로 구분하였으며, 사물인터넷(IoT), 생체인터넷(IoB), 클라우드(cloud), 빅데이터(BigData), 인공지능(AI), 0213기계지능(MI) 등 6가지 디지털 트랜스폼 기술을 제시하고 있다(Lee, 2018).
이러한 기술들은 지질자원기술 및 자원산업 분야에서도 다양한 혁신적 시도와 그 가능성을 현실화시키는 데 큰 역할을 하고 있으며 학제의 패러다임 변화에까지 영향을 미치고 있다. 따라서 4차 산업혁명에 대한 해석은 패러다임 전환기에 있는 지질자원기술의 지속가능한 발전과 새로운 역할 및 그 확장성을 찾는 출발점이 될 수 있다.
광물 및 석유·가스자원 산업분야에서 전주기 공정 통합화 및 자동화를 통한 생산 효율화 및 안전 강화는 오래 전부터 주요한 산업적 관심사이자 기술 개발의 주요 목적이 되어 왔다. 광물자원 산업분야에서는 2010년대부터 미래 광업의 형태로 디지털 혹은 스마트 마이닝이라는 개념이 도입되기 시작하였다(McGagh, 2014). 이는 전 주기적 관점에서 각 공정을 연결하고 이를 자동화함으로써 광산 자산을 효율적으로 운영하고 나아가 수익을 극대화하고 개발 환경을 유지하는 데 그 목적을 두고 있다. 앞서 석유·가스자원 산업분야에서는 2000년대부터 디지털 오일필드(DOF, Digital Oil Field)의 개념이 제시되었는데 이는 분야 이론(혹은 기술), 데이터, 엔지니어링과 통합된 작업 흐름 관리 체계가 함께 자동화되어야 가능한 개념이다. 디지털 오일필드는 자동화와 정보 기술의 집합체로서 운영 작업 프로세스의 효율화를 통해 석유·가스자원 자산 관리법에 대한 철학을 변화시켜 왔다(Dickens et al., 2012; Saputelli et al,, 2013).
국내 자원산업의 디지털 변환(digital transforming) 시기에 대비하기 위해서는 디지털 자원산업의 기술 구현 수준을 체계화할 필요가 있다. 이에 본고에서는 관련 기술개발 및 사업화 마일스톤 수립과 기술개발 목표와 대상을 계획하기 위해 ISA2)-95 레벨에 기초한 자원산업의 디지털 변환 수준 정의를 소개하고자 한다.
또한 IoT의 확장된 개념으로서 가상물리시스템(cyber-physical system, CPS)이 적용되는 스마트 팩토리(smart factory)와 스마트 마이닝의 산업 환경적 차이를 비교함으로써 GeoCPS의 개념적 정체성을 찾고자 한다.
그리고 자원산업의 디지털화 및 공공기술 패러다임 변화에 있어 AI는 정보의 지능화 측면에서 매우 중요한데, 지질자원 분야에서의 대표적 AI 활용사례를 살펴봄으로써 이 분야의 새로운 융합기술 가능성을 고찰한다. 더불어 지질자원 분야 특성과 데이터 환경에 따른 GeoAI의 도전적 이슈를 정리하고자 한다.
4차 산업혁명
4차 산업혁명의 재해석
일반적으로 산업혁명을 기계 혁명(제조산업), 전기 혁명(서비스산업), 정보 혁명(지식서비스), 지능 혁명(지능사회) 등 기술 혁신의 과정으로 정의한다. 특히 4차 산업혁명은 IoT, 클라우드, AI 등 다양한 기술들의 융합으로 해석한다. 산업혁명을 단순히 산업이나 기술 혁신의 과정에 국한하여 바라보는 시각은 현재를 이해하고 미래를 예측하는 데 한계가 있다.
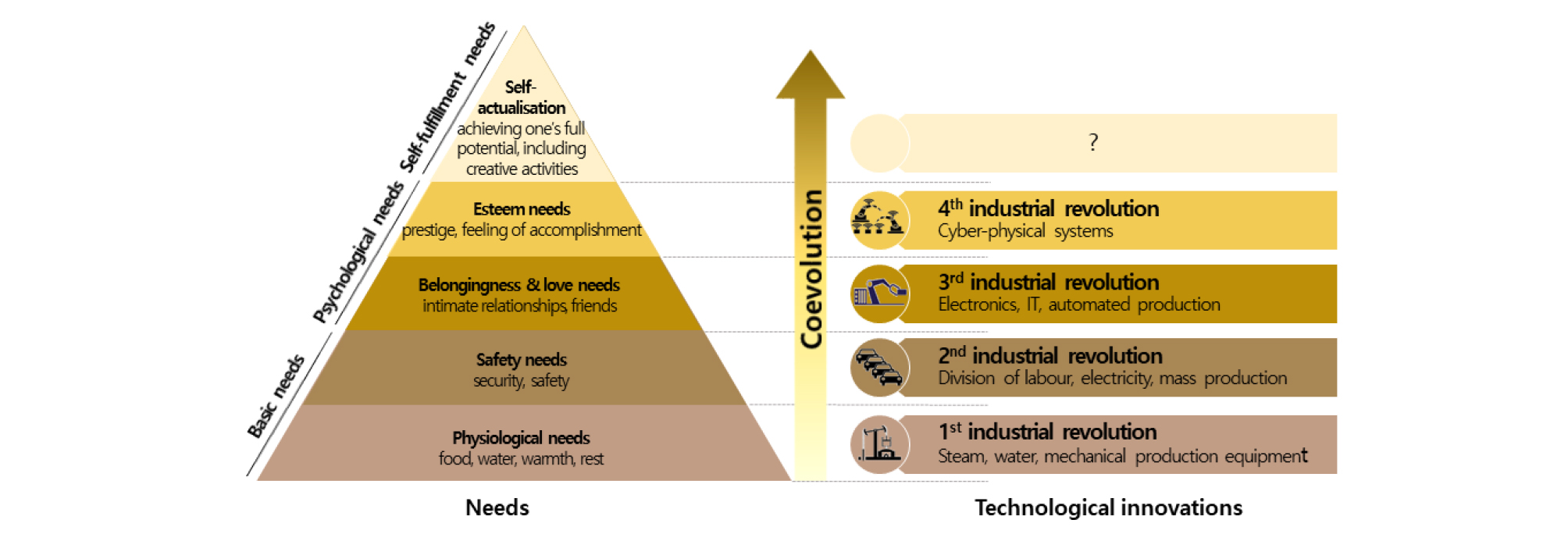
4차 산업혁명을 보다 명확히 이해하기 위해 산업혁명을 기술의 관점이 아니라, 생산(기술)과 소비(욕망)의 순환이란 관점에서 욕망과 기술의 공진화 과정으로 해석하는 모델이 제시된 바 있다(Lee, 2018). 이는 Maslow(1943)의 욕구이론에 기초한 ‘KCERN Model’의 해석 관점으로, 인문학적(인간욕망), 경제사회학적(사업지속성), 과학기술적(기술혁신) 관점을 함께 고려하고 있다. 1차 산업혁명을 생존 욕구 충족, 2차 산업혁명을 물질적 욕구 충족, 3차 산업혁명을 온라인 연결을 통한 사회적 욕구 충족, 나아가 4차 산업혁명을 자기표현과 자아실현의 욕구 충족으로 연결하여 해석한다(Fig. 1). 또한 4차 산업혁명을 ‘인간을 위한 현실과 가상의 융합’ 혁명으로 정의하고, 4차 산업혁명의 현실과 가상의 융합과정을 데이터화, 정보화, 지능화, 스마트화라는 4단계로 제시하고 있는데 단계별 핵심기술은 다음과 같다(Lee, 2018):
- (1단계) 현실 세계의 데이터를 수집하여 가상으로 옮기는 과정(IoT)
- (2단계) 수집된 데이터를 가상의 세계에서 빅데이터로 구축하는 과정(클라우드, 빅데이터)
- (3단계) 가상의 세계에서 AI를 가지고 다양한 시뮬레이션을 통하여 예측하는 과정(AI)
- (4단계) AI가 분석한 결과를 아날로그 트랜스폼 기술을 통하여 현실화하는 과정(제어)
4단계의 아날로그 트랜스폼 기술은 현실 물리 세계를 제어한다는 의미로 볼 수 있으며, 산업적 측면에서는 자율주행자동차 및 스마트 팩토리 등의 CPS와 연결시킬 수 있다.
KCERN에서 정의하고 있는 4차 산업혁명은 공공성이 강한 지질자원 기술 및 산업의 미래를 예측하고 관련 기술 발전의 방향을 모색하는 데 도움이 된다.
시민사회와 공공기술의 공진화
기술과 욕망의 공진화 과정으로서 산업혁명을 바라보는 시각은 시민사회와 공공기술의 공진화로 확장할 수 있다. 최근 과학기술에서 두드러진 특징 중 하나로 오픈소스코드, 오픈데이터, 오픈에세스 등 오픈사이언스를 들 수 있다.
이는 과학기술 분야의 접근성을 높이고 학제 간 융합의 기회를 제공함과 동시에 과학기술에 대한
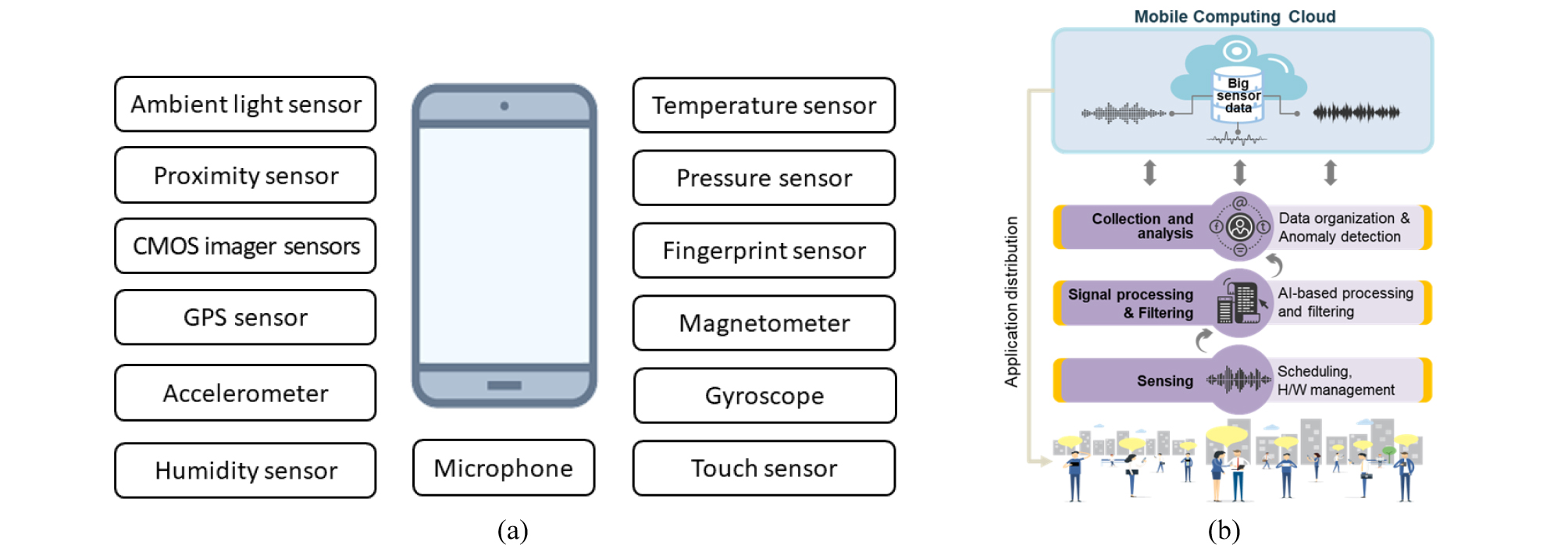
시민들의 이해도를 높일 수 있다. 나아가 ICT의 발전은 시민들에게 다양한 방식으로 과학기술 분야에 참여할 기회를 제공하며, 이를 통해 방대한 양의 데이터를 수집하고 의사결정에 필요한 유용한 정보를 가공·처리할 수 있다. 대표적인 예로서 스마트폰은 핵심 컴퓨팅 및 통신장치만 제공하는 것이 아니라 가속도계, 디지털 나침반, 자이로스코프, GPS(global positioning system), 마이크, 카메라 등 다양한 내장형 센서 세트도 함께 제공하며, 이는 교통, 의료, 소셜 네트워크, 안전, 환경 모니터링 등 다양한 영역에서 크라우드센싱의 개념으로 발전하여 이미 활용되고 있다(Table 1과 Fig. 2). 이런 변화는 시민이 공공기술 분야에 참여할 수 있는 기회를 열어 주며, 공감할 수 있는 공공서비스에 대한 기대 수준을 높인다.
Table 1. Representative crowdsensing applications and their characteristics
| Applications | Project or App | Summary | Function or Characteristics | Reference |
| Transportation | VTrack project |
A system for travel time estimation 25 GPS/WiFi equipped cars, 800 hours | Thiagarajan et al., 2009 | |
| Mobile Millennium |
From 2008 GPS Mobile app: 5000 users, 1 year |
Using machine learning to infer traffic conditions for large metropolitan areas from crowdsourced data | Hunter, et al., 2011 | |
| TrafficSense |
Predictive multimodal personal mobility assistant Users: Small test groups Cities/countries: 3/1 |
User contributes to smoother and more sustainable traffic and transportation for all | Heiskala et al., 2016 | |
|
Environmental monitoring | CitySee project |
From 2011 A real-time CO2-monitoring system using sensor networks for an urban area around 100 km2 (Wuxi City, China) |
Measuring the carbon absorbance and emissions, supporting the government's policy decision in energy saving and emission reduction, and offer citizens with convenient daily living services. | Liu et al., 2013 |
| SONYC |
A system for monitoring, analyzing, and mitigating urban noise pollution (New York, U.S.) |
Leveraging the latest in machine learning technology, big data analysis, and citizen science reporting | Bello et al., 2019 | |
|
PEIR (Personal Emergency Information Report) |
App uploads GPS signal and motion classification and server combines data such as GPS traces, GIS maps, weather data, traffic data, vehicle emission modeling |
Personal Environmental Impact Report (CO and PM2.5 emission impact analysis, PM2.5 exposure analysis) | Mun et al., 2009 | |
|
Earthquake monitoring |
ESA (Emergency Situation Awareness) |
All-hazard information are captured, filtered and analysed from Twitter |
Alert monitoring, impact assessment visualisation, incident report visualisation | Yin, J. et al., 2012, Robinson et al., 2013 |
|
MyShake (Android) / MyQuake (iOS) |
From 2016 downloaded by nearly 200,000 users 8,000 phones/day are providing data | Kong et al., 2016 | ||
|
Earthquake early warning(EEW) |
Demonstration of the EEW via crowdsourcing through controlled test of consumer devices, simulated data and real data |
Mw (moment magnitude) 7 earthquake on California's Hayward fault, and real data from the Mw 9 Tohoku-oki earthquake | Minson et al., 2015 | |
|
Earthquake network project |
From 2013 Real-time alerts on earthquakes detected by the smartphone network Real-time earthquake reports from users |
Automatically sending your coordinates to a list of trusted contacts | Finazzi, 2016 |
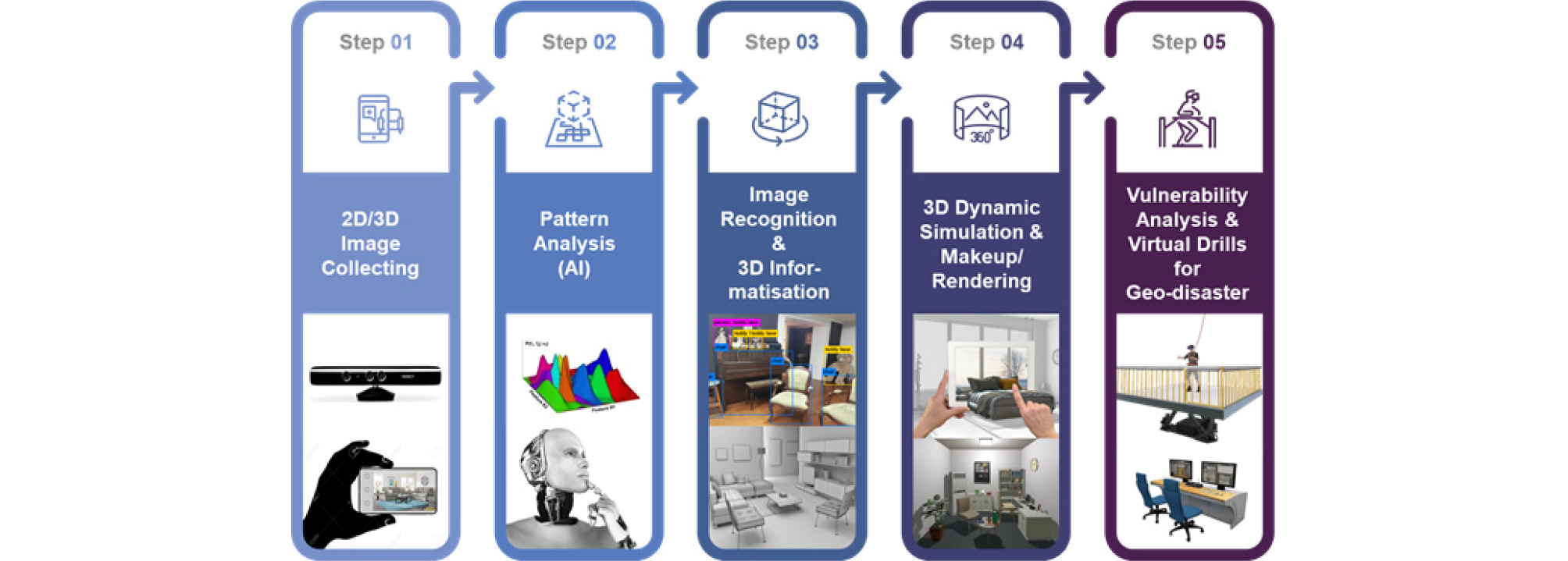
지질자원 분야가 제공하는 공공기술은 수요기반 기술로 전환되어야 하며, 새로운 역할과 서비스를 통해 공공수용성(public acceptance)의 제고에 기여할 수 있어야 한다. 지진과 같은 지질재해와 관련하여 그동안 모션 플랫폼을 통한 단순 체험 학습이란 서비스에서 나아가 가상현실(VR, virtual reality) 기술과 지진공학 및 지구물리학과 같은 지식기반 콘텐츠를 결합하는 시도가 필요하다. 이로써 위치, 주거 환경 및 생활객체와 같은 비구조 요소 등 다양한 시민들의 생활환경을 반영한 가상공간에서 실감도 높은 지진 대응 훈련 서비스를 제공할 수 있다. 또한 지질학, 지구물리, 지진공학 및 지반공학과 같은 과학기술분야 지식(domain knowledge)을 기반으로 온라인 상 사용자 환경 정보를 통해 생활환경 내 지진에 대한 취약성을 평가해주는 서비스도 제안할 수 있다(Fig. 3).
지질자원 분야가 지닌 공공성은 시민사회의 요구와 함께 공진화를 통해 강화될 수 있으며, 4차 산업혁명의 혁신 기술과 지질자원 분야 지식의 융합화를 가속화시키는 계기가 된다.
GeoCPS
스마트 마이닝과 GeoCPS
IoT는 실세계(real world)의 디지털화 과정이며, 빅데이터는 디지털 데이터의 정보화 과정으로, AI는 정보의 지능화 과정으로 각각 이해할 수 있다. 이러한 전체 과정은 실세계 현상의 분석과 이해 및 예측에 그 목적이 있다.
이러한 혁신 기술의 발전과 함께 4차 산업혁명의 중심에 있는 CPS는 디지털화 및 정보화 과정을 통해 내린 의사결정이 다시 현실 세계로의 아날로그화를 통해 의사결정, 제어 및 조정 과정이 추가된 스마트화의 개념이다. CPS에서는 실제 물리환경에서 관측된 방대한 자료를 이용하여 실제 물리환경과 유사한 가상환경을 구축하고, 가상환경 내에서의 다양한 분석 및 예측을 통해 실제 물리환경에서 필요한 최적의 문제해결 방안을 도출할 수 있다. 이는 제조업 분야의 스마트 팩토리(smart factory), 교통 분야의 자율주행 시스템(autonomous driving system), 자원산업 분야의 디지털 마이닝(digital mining) 혹은 스마트 마이닝(smart mining) 등으로 적용되고 있다.
일반적으로 광산은 제조업 공장과는 다른 특수성을 지니고 있다. 스마트 팩토리가 적용되는 제조업 공장은 고정형 기반시설로 비교적 공정별 설비의 불확실성이 낮고 각 설비의 계측이 용이하며, 오랫동안 검증된 유효한 프로세스 모델에 기초하여 운영되는 특징이 있다. 반면 광산은 고정된 설비와 함께 거대한 모빌리티 장비가 하나의 독립적 개체로 운영되고 있으며, 광체를 포함한 지질, 기후, 환경 등과 관련된 다양한 불확실성에 항상 노출되어 있다. 또한, 변화하는 지형 및 지질 환경 내 경험적 프로세스 모델이 적용되고 있다. 따라서 이와 같은 지질자원 분야의 특수성이 반영되고 기능화된 개념으로 GeoCPS가 필요하다.
GeoCPS는 지구시스템에서 생산되는 대용량의 다양한 데이터를 수집-분석-해석하고, 지구시스템에서 일어나는 현상을 예측하기 위해 지질자원 분야에 기능화 되고 지질자원 지식에 기반한 ICT 융합 기술이며 나아가 지구환경을 제어할 수 있는 시스템을 목표로 한다. 이와 같은 GeoCPS를 통해 기존 전통적인 광물자원 생산공정을 실시간으로 제어함으로써 생산비용을 절감하고 효율성을 향상할 수 있으며, 스마트 마이닝과 가상광산을 구현할 수 있다.
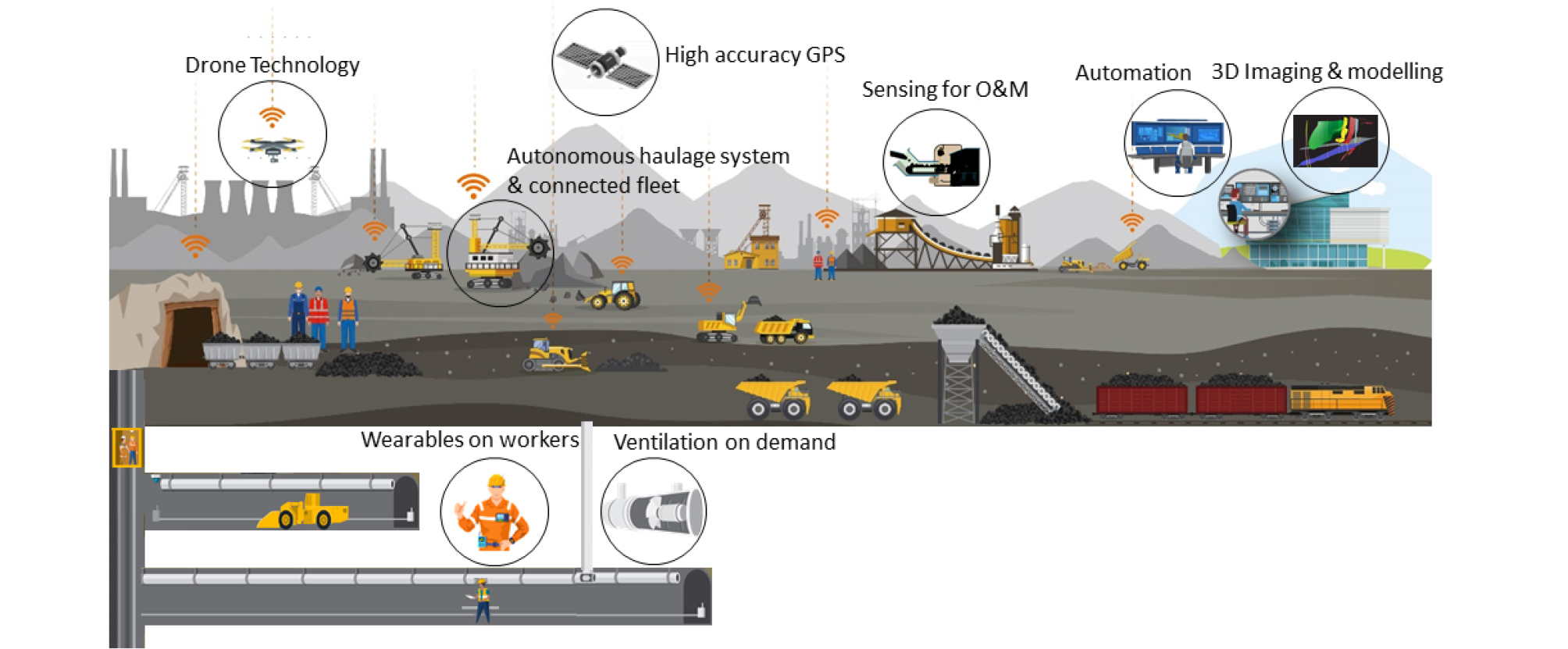
스마트 마이닝은 고도의 엔지니어링과 IoT, 빅데이터, AI를 통해 광산의 전주기 운영에 관여하는 모든 요소가 서로 연결되어 있다. 그리고 디지털 정보화 및 지능화가 가능하여 생산, 안전, 책임, 환경 유지 및 지역 사회 지원을 포함한 모든 측면에서 최적화된 광산 운영 체계라 할 수 있다. 국내 자원산업의 경우 가행광산 원격관리 및 공정최적화를 위한 토탈솔루션의 개념보다는 근접 경보 시스템(proximity warning system), 맞춤형 통기시스템(ventilation on demand), 센싱기반 광석처리 O&M(operation & maintenance), 3D 지질모델 등 광산 프로세스 단위별 안전 확보 및 운영 효율화를 목표로 하고 있다(Fig. 4).
유사한 개념인 가상광산(virtual mine)은 물리세계가 투영된 가상환경을 만드는 디지털트윈 개념으로 이해할 수 있다. 광산의 가상화를 위해 광산을 구성하는 요소(entity)는 ① 광산을 포함하는 지형구조, 지질구조 그리고 광체(품위 분포 포함) 등의 지질 개체, ② 개별 기계장비, 운송유닛, 광산 작업자들 등의 모바일 개체, ③ 사면, 갱도, 고프(goaf), 작업장 등 광산 구조 개체, ④ 갱내의 가스, 미세먼지, 지하수 등 광산 환경요소 개체, ⑤ 환경관련 설비 개체 등으로 분류할 수 있다(Table 2). 가상광산은 실제 광산을 구성하는 각 개체들을 컴퓨터(사이버) 상에 사상한 복제체(twin entity)들의 집합으로 재구성할 수 있다. 그리고 이를 이용하여 사이버 공간 상에서의 다양한 환경 및 채광 시나리오에 따라 시뮬레이션을 수행함으로써 전주기 광산운영을 최적화 할 수 있다.
Table 2. Mining entity classification for digital twining
ISA-95 레벨과 마이닝 발전 단계
ISA-95는 제조업의 생산공정 감지(레벨 1)에서 ERP 솔루션(레벨 4)까지 4단계를 포괄하는 표준 기술 아키텍처로서 프레임워크와 관련된 용어로 정의된다(ANSI/ ISA-95.00.01, -95.00.02, -95.00.03, -95.00.05). 레벨 1은 생산공정 감지 및 생산공정 조작을 목적으로 공정에 영향을 미치는 주요 인자(예: 유동, 온도 또는 압력), 즉 단변량 계측과 공정 조정 기술을 의미한다. 레벨 2는 공정 계측 시스템 간 그리고 데이터 관리 시스템과 모델링 시스템 간의 연결 기능을 통해 생산공정을 관리·감독하는 자동화 설비 시스템이다. PLC(programmable logic control)과 SCADA (supervisory control and data acquisition) 시스템을 활용할 수 있으며, 이 시스템들은 공정을 시각화하고 제어 시스템을 통해 공정과의 상호 작용을 제어하는 역할을 한다.
레벨 3은 PAT(process analytical technology) 데이터 관리 시스템으로 작업 흐름과 제조법 제어, 공정의 단계화를 통한 최종 제품 생산에 관여하며, 공정별, 시간/분/초 단위별 기록의 유지 및 생산 공정 최적화를 지원한다. 레벨 4는 생산, 자재 사용, 납품 및 출하 등 기본 생산 일정을 수립하고 재고 수준을 결정하는 ERP(enterprise resource planning) 솔루션을 의미한다.
일반적으로 광산 개발에서 판매까지의 일련의 과정은 광구 확보, 광산 설계, 계획 수립, 천공/발파, 적재/운송, 비축, 분쇄, 처리, 운송, 판매 등으로 단계화할 수 있다. ISA-95 프레임워크에 따라 마이닝의 발전 단계를 분류할 수 있다(Fig. 5). 디지털 마이닝은 ISA-95 레벨 3에 해당하는 것으로 전주기 지질자원 분야 지식과 IoT 및 AI 기술이 적절한 통신환경 하에서 융합되어 하나로 체계화되는 과정을 통해 구현 가능하다.
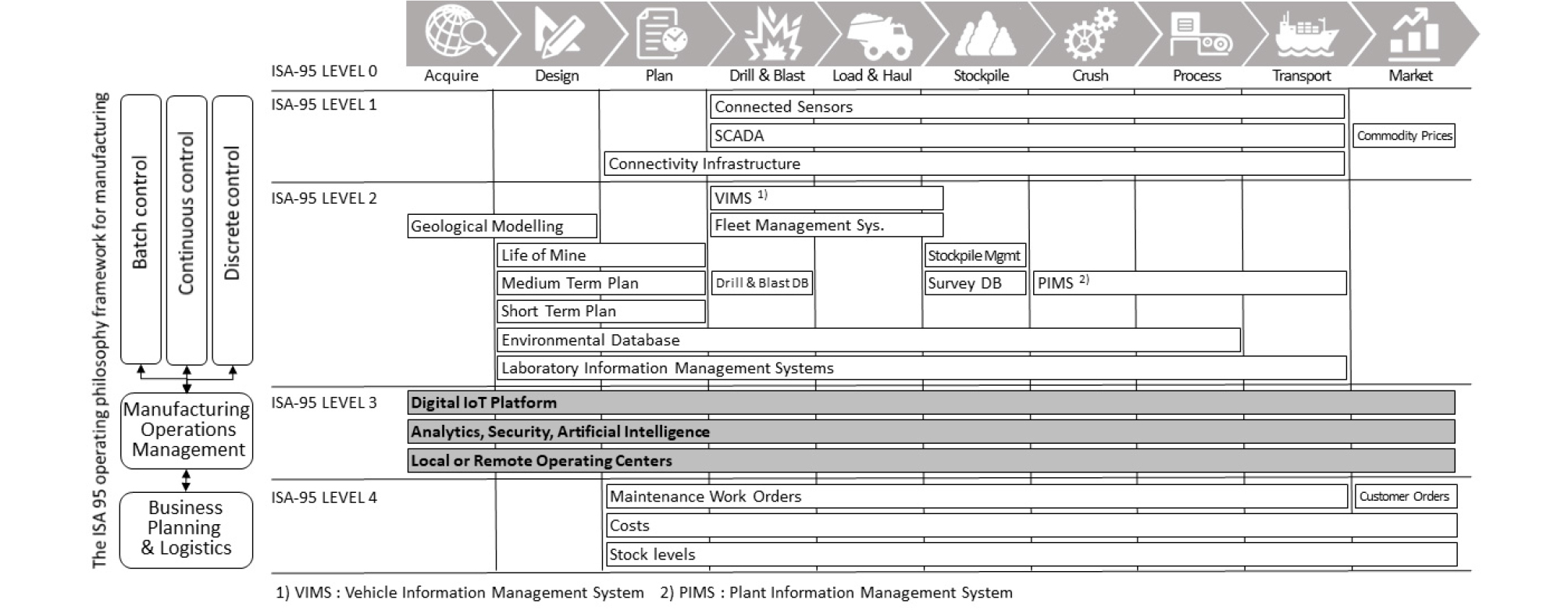
국내 자원산업의 환경과 초기 투자비를 고려할 때 전체 시스템을 구축하기보다는 광산보안 분야와 개발, 처리, 운송 등 각 공정 단계별로 맞춤식 스마트화를 진행시키는 것이 효과적일 것이다. 또한 국내 광산의 높은 외산장비 의존성을 고려했을 때 완전 무인화의 목표보다는 장비 간 혹은 장비와 작업자 간 맞춤형 커넥티드 마이닝(connected mining)의 구현이 보다 현실적이다. 이를 위해 현재 구축되어 있는 유선망과 무선 네크워크 간 통합화와 같은 갱내 통신 네트워크 효율화 및 갱내 무선 통신 가이드라인 재정이 선행될 필요가 있다.
GeoAI
AI와 지질자원 분야 활용 사례
AI는 학습, 문제 해결, 패턴 인식 등과 같이 주로 인간 지능과 연결된 인지 문제를 해결하는 데 주력하는 컴퓨터 공학 분야로 학자들마다 다양하게 정의하는 면이 있다. Bellman(1978)은 인간의 사고, 의사결정, 문제 해결, 학습 등의 활동과 연관 지을 수 있는 자동화로 정의했으며, Kurzweil(1990)은 인간이 지금까지 해 왔던 기능적인 작업들을 대신할 수 있는 기계의 제작을 위한 기술이라고 하였다. 또한 Winston(1992)은 인지와 추론, 행위를 가능하게 하는 연산에 대한 연구로 정의한 바 있다. 최근 과학기술정보통신부 4차산업혁명위원회는 AI를 인지, 학습 등 인간의 지적능력(지능)의 일부 또는 전체를 ‘컴퓨터를 이용해 구현하는 지능’이라고 정의했다(Ministry of Science and ICT, 2018). 이를 종합하면 AI는 인지, 추론 등을 통한 학습과 문제해결 등 인간의 사고 능력을 기계적으로 구현하여 자동화한 시스템을 의미한다.
일반적으로 공학에서 정의하는 프로그램이란 특정 목적을 위해 만들어진 소프트웨어에 인간이 알고리즘을 구상하여 입력한 그대로 행동하는 것인 반면, AI는 기계 스스로 학습하여 최적의 알고리즘을 만들어 나가는 것을 의미한다. AI의 기법은 크게 지도학습(supervised learning)과 비지도학습(unsupervised learning) 그리고 강화학습(reinforcement learning)으로 분류할 수 있다(Fig. 6).
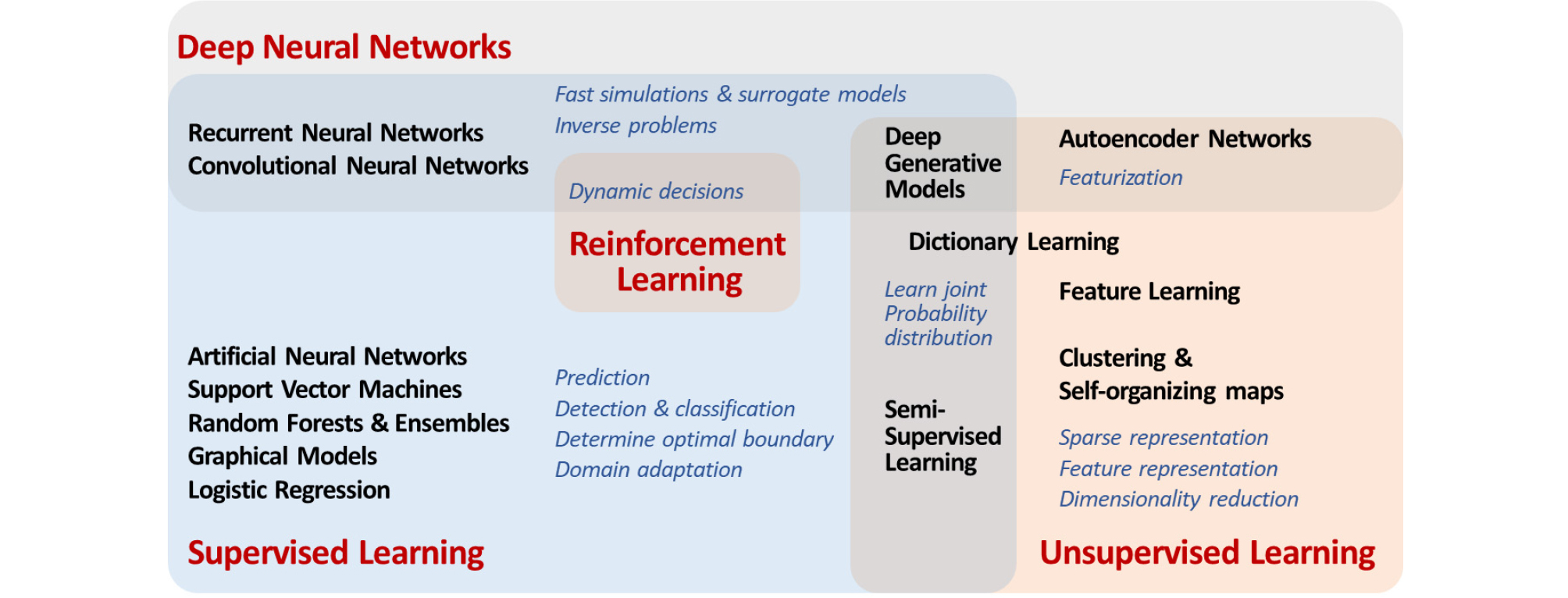
지도학습으로 분류할 수 있는 기법에는 로지스틱 회귀(logistic regression), 그래프 모델(graphical model), SVM (support vector machine), RF(random forest), 인공신경망(artificial neural network, ANN), 심층신경망(deep neural network, DNN) 등이 있다.
로지스틱 회귀는 독립변수와 이항의 종속변수 간의 관계를 함수로 표현한 모델이라 할 수 있다.
그래프 모델은 시계열적 의존성이 높은 지구과학 데이터를 다루는 데 특화된 기법으로서 순차적 자료를 모델링하는 데 적용된 HMM(hidden Markov models)이 대표적이다.
SVM은 주어진 학습 데이터를 비선형 매핑을 통해 고차원으로 변환한 후, 새로운 차원에서 초평면(hyperplane)을 최적으로 선형 분리하여 가장 적합한 의사결정 영역(decision boundary)을 찾는 기법이다(Cortes and Vapnik, 1995).
일반적인 의사결정나무(decision tree)는 의사결정규칙과 그 결과들을 트리 구조로 도식화한 지도학습 기법이다. 그런데 RF는 다수의 의사결정나무들을 생성한 다음, 각 개별 트리의 예측치들 중에서 가장 많은 선택을 받은 클래스(또는 label)로 예측하는 알고리즘으로서 앙상블(ensemble) 학습 방법의 일종이다(Cracknell and Reading, 2013; Cracknell and Reading, 2014).
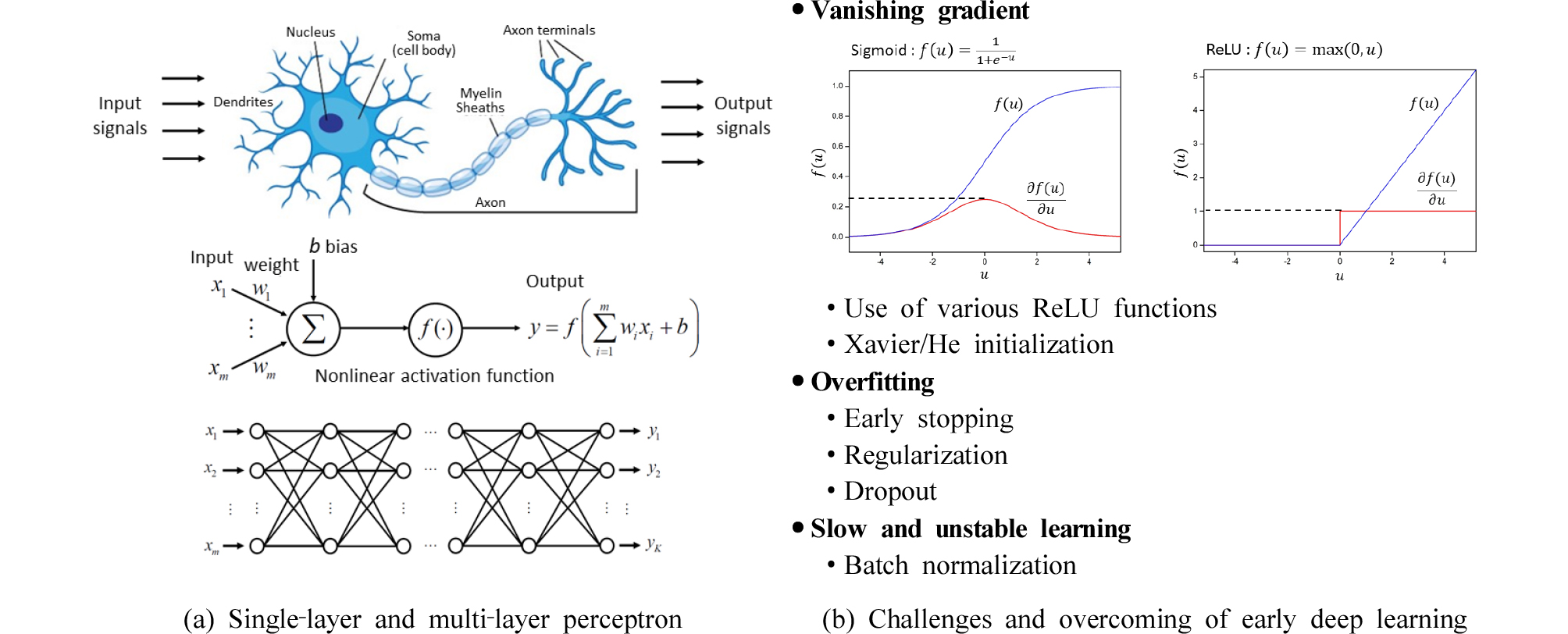
ANN은 1960년대의 퍼셉트론(perceptron) 알고리즘에서 출발하여 다층구조 형태의 신경망 기반의 심층 아키텍처인 딥러닝(deep learning)에 이르기까지 60년 이상의 긴 연구 역사를 지니고 있다(Goodfellow et al., 2016). ANN은 일련의 가중치로 연결된 노드(뉴런) 집합으로 표현되며, 입력층, 은닉층, 출력층으로 구분된다. ANN의 비선형 관계 모델링이라는 강점으로 인해 다양한 지구과학자료에 적용된 바 있다(Van der Baan and Jutten, 2000; Poulton, 2002). DNN 혹은 심층학습은 확장된 ANN 기법으로 일련의 가중치로 연결된 노드(뉴런) 집합으로 표현되며, 입력층, 출력층과 그 사이의 다중의 은닉층으로 구성된다. 심층학습은 지도 및 비지도학습 방법을 포괄하며 다양한 네트워크 아키텍처를 가진 광범위한 기법을 의미한다. 초기 DNN에는 기울기 값 소실 문제(vanishing gradient problem), 과적합(overfitting), 높은 연산량 및 불안정한 학습 등의 문제들이 있었다.
이에 초기 신경망 학습에 사용되었던 sigmoid 함수 또는 tanh 함수 대신 ReLU(rectified linear unit)를 사용하고, 가중치의 초깃값 설정 문제를 DBN(Deep Belief Network), RBM(Restricted Boltzmann Machine) 또는 Xavier 초기화를 활용하여 기울기 값 소실 문제를 해결할 수 있었다. 그러나 학습을 위한 많은 연산량과 과하게 학습하여 실제 데이터에 대한 오차가 증가하는 느린 학습 및 불안정 학습 등의 문제가 발생할 수 있다. 2000년대 이후부터는 드롭아웃(drop-out), ReLU, 배치 정규화(batch normalization) 등의 기법이 적용되면서 딥러닝의 핵심 모델로 활용되고 있다(Fig. 7).
생성모델은 자료에 대한 결합확률분포를 학습하는 기계학습의 한 종류로 지도학습과 비지도학습 모두에 해당한다. 최근에는 생성적 적대 신경망(generative adversarial network, GAN)에 대한 연구가 활발히 진행되고 있다(Goodfellow et al., 2014). GAN은 서로 반대되는 목적을 가진 두 개의 신경 네트워크인 훈련 자료를 사용하여 모델을 학습하는 생성자 네트워크(generator network)와 실제 훈련 자료와 합성 자료를 구별하는 판별자 네트워크(discriminator network)로 구성된다(Mosser et al., 2017). 심층생성모델의 비지도학습 능력은 라벨을 종종 이용할 수 없는 지구과학의 많은 역산문제를 해결하는 데 특히 효과적인 면이 있다. 또한 신경망을 사용하면 수치 시뮬레이션 모델과 비교하여 합성지진자료 생성에 필요한 계산 비용을 상당량 줄일 수 있다(Krischer and Fichtner, 2017).
비지도학습으로 분류할 수 있는 기법에는 군집분석과 SOM(self-organizing maps), 표상학습(feature learning 혹은 representation learning), 사전학습(dictionary learning)이 있으며, 심층신경망으로 분류할 수도 있는 오토인코더(autoencoder) 네트워크와 심층생성모델(deep generative model)이 있다.
SOM은 차원 감소 또는 군집화에 사용할 수 있는 비지도학습 인공신경망의 일종이다(Kohonen, 2013). 표상학습은 자료에 대한 낮은 차원 또는 희소 특성(sparse feature)을 학습하는 데 사용할 수 있으며, 사전학습은 기본 요소들의 선형 조합 형태로 표현하여 표상을 학습하는 방법이다.
AI는 딥러닝의 발전과 더불어 강력하고 사용이 용이한 기계학습 툴박스 및 오픈소스코드 등으로 지질자원 분야 연구자들의 새로운 관심의 대상이 되어 왔다. 대용량 메모리를 가진 초고속 컴퓨터의 결합, AI 알고리즘의 급속한 발전, 그리고 대용량 자료의 접근 가능성이 높아지면서 지질자원 기술은 진일보할 수 있는 기회를 가질 수 있다. AI 적용을 통한 지질자원 분야의 기술적 진전은 크게 자동화(automation), 모델링(modeling 혹은 역산문제), 그리고 발견(discovery) 등 3가지 범주로 살펴볼 수 있으며(Bergen et al., 2019), 각 범주별 대표적 활용 사례는 Table 3과 같다.
Table 3. Categories and cases of AI application for geoscience
| Categories | AI methodology | Application geoscience fields (Objective) | References |
| Supervised learning | |||
| Automation | CNN | Seismology (Earthquake detection) | Perol et al., 2018 |
| CNN | Volcanology (Classification of volcanic ash) | Shoji et al., 2018 | |
| SVM | Seismology (Earthquake warning) | Ochoa et al., 2017 | |
| ANN | Seismology (Earthquake warning) | Kong et al., 2016 | |
| SVM | Seismology (Earthquake warning) | Reddy and Nair, 2013 | |
| Modeling | ANN |
Seismology (Building relationship between earthquake and ground motion) | Trugman and Shearer, 2018 |
| RF and SVM |
Hydrology (Flow and transport simulation in porous media) | Valera et al., 2018 | |
| DNN | Rheology (Viscoelastic calculations) | DeVries et al., 2017 | |
| ANN | Seismology (Solving the inverse problem) | Käufl et al., 2016 | |
| RF |
Seismology (Building relationship between earthquake and ground motion) | Derras et al., 2014 | |
| Discovery | CNN | Seismology (Earthquake classification) | Kang et al., 2019 |
| Gradient boosted tree | Seismology (Earthquake prediction) | Hulbert et al., 2019 | |
| Gradient boosted tree |
Geology and Seismology (Discovering unexpected patterns; Fault's position) | Rouet-Leduc et al., 2018 | |
| RF | Seismology (Earthquake prediction) | Rouet-Leduc et al., 2017, Rouet-Leduc et al., 2019 | |
|
Discover & Automation | RF | Lithology (Lithological mapping) | Kuhn et al., 2018 |
| Unsupervised learning | |||
| Discovery |
K-means (unsupervised) and HMM (supervised) |
Geology and Seismology (Identification of temporal earthquakes patterns) | Holtzman et al., 2018 |
| GAN | Hydrology (Reconstruction of porous media) | Mosser et al., 2017 | |
| PCA and SOM | Geology (Geologic pattern recognition) | Roden et al., 2015 | |
| SOM |
Geology (Identification and Mapping geophysical data) | Carneiro et al., 2012 | |
| SOM | Seismology (Earthquake detection) | Köhler et al., 2008 | |
|
Discovery & Modelling | Dictionary learning |
Seismology (Development of 2D travel time tomography) | Bianco and Gerstoft, 2017 |
자동화는 영상인식과 같이 명시적인 일련의 명령어로 설명하기 어려운 복잡한 작업을 수행하는 데 AI를 활용하는 것을 의미한다. 대용량 고차원 데이터 패턴을 처리하고 추론할 수 있는 AI 알고리즘의 강점을 이용하면 지질자원 분야의 대용량 데이터 분석 및 처리과정을 자동화할 수 있다. 특히 지진감지 및 지진 조기 경보와 같이 대용량 데이터 분석 단계를 자동화하거나 화산재 입자 분류와 같은 많은 시간이 소요되는 분석에 있어서 전문적이고 반복적인 작업 수행을 위해 적용된 바 있다(Perol et al., 2018; Kong et al., 2016; Reddy and Nair, 2013; Ochoa et al., 2017; Shoji et al., 2018).
모델링은 데이터 세트 간 관계 및 구조를 파악하는 작업에 AI를 활용하는 것을 의미한다. 지진동 예측을 위해 지진원과 관련한 매개변수와 최대지반가속도(peak ground acceleration, PGA)의 관계처럼 대상 변수와 데이터 간의 복잡한 미지의 관계에 대한 모델을 생성할 수 있다. 또한 전산 시뮬레이션 및 역산문제와 같은 대규모 연산 속도를 높이기 위한 근사 모델로 활용할 수도 있다(DeVries, et al., 2017; Valera et al., 2018; Käufl et al., 2016). 역산문제는 관측 데이터, 연산 모델 및 물리이론을 연결하여 지구시스템을 추론하는 것을 목적으로 한다. 딥러닝은 역산의 비정치성(ill-posedness) 문제를 극복할 수 있는 방안을 제공할 수 있으며 역산문제를 푸는 데 유용한 방법이 될 수 있다(McCann et al., 2017).
데이터에서 새로운 정보를 추출하는 능력은 과학적 응용을 위한 AI의 가장 흥미로운 능력 중 하나이다. 일반적으로 AI는 전통적인 기법들에서 쉽게 드러나지 않는 새로운 패턴이나 구조 및 관계를 발견하기 위한 도구를 제공한다. 또한 이전에 확인할 수 없었던 신호 또는 물리적 프로세스를 나타내거나, 데이터를 표현, 해석하고 시각화하기 위한 주요 특징을 추출하는 데 사용된다(Rouet-Leduc et al., 2017; Rouet-Leduc et al., 2018; Hulbert et al., 2019; Rouet-Leduc et al., 2019; Valentine and Trampert, 2012; Carneiro et al., 2012; Wu and Hale., 2016). AI는 직관에 반하거나 예기치 못한 패턴을 발견함으로써 편향된 결과를 피할 수 있고, 실험의 설계나 데이터 수집에 효과적으로 기여할 수 있다(Rouet-Leduc et al., 2018; Kuhn et al., 2018).
Why GeoAI, not AI
지질자원 분야에서 다루는 현상(혹은 프로세스)과 데이터가 지닌 특성 및 환경으로 인해 전통적인 AI는 최근의 기술적 발전에 비해 지질자원 분야에 제한적으로 적용되어 왔다. 따라서 지질자원 분야가 지닌 특성에 대한 이해는 지질자원 분야에 기능화 된 AI 혹은 이의 활용 체계에 대한 연구개발 방향을 모색하는 출발점이 될 수 있다. 전통적 AI가 지질자원 분야 활용에서 제한이 있었던 원인은 크게 현상 혹은 대상과 데이터 특성에서 찾을 수 있다.
현상 혹은 대상의 특성은 무정형성(amorphousness), 시공간 구조(spatiotemporal structure), 고차원성(high dimensionality), 시공간적 이질성(heterogeneity), 희소성(scarcity) 등을 들 수 있다(Karpatne et al., 2018).
일반적으로 지질자원 분야에서 다루는 대상의 형태, 구조, 패턴은 시공간 상에서 연속적으로 변화하고 다양한 스케일로 존재한다. 따라서 그 현상 혹은 대상의 경계를 명확히 정의 내리기 어려운 경우가 많은데 이를 경계의 무정형성이라 한다. 현상의 형태, 패턴 및 동적 정보와 이와 관련한 불확실성을 함께 고려할 수 있는 새로운 기법들이 제안되고 있지만(Ravela, 2012; 2015), 무정형성을 지닌 대상이나 현상의 특성을 추출하기 위한 보다 진일보한 방법이 필요하다.
시공간 상에서 발생하는 현상들은 대부분 시공간적 자기상관성(autocorrelation)을 보이는 경우가 많은데 이는 현상마다 시공간 구조(spatiotemporal structure)가 내재하고 있음을 의미한다. 따라서 지구물리학적 현상의 효과적인 모델링을 위해서는 데이터의 시공간적 자기상관성의 이해가 중요하다. 전통적인 AI는 관측된 변수의 독립동일분포(independent identically distributed, iid) 가정 하에서 작동하며, 이는 지질자원 분야에서는 더 이상 유효하지 않을 수 있다.
매우 복잡한 지구시스템 현상의 정확한 예측을 위해서는 서로 영향을 미칠 수 있는 많은 수의 잠재적인 변수들을 동시에 고려해야 한다(Wunsch, 2006). 이들 변수들의 영향을 정밀하게 분석하고 파악하는 과정은 지질자원 분야 데이터의 차원수를 필연적으로 증가시킨다.
대부분의 지질자원 분야 데이터는 시공간적 이질성(heterogeneity)을 보인다. 이는 시공간적 자기상관성 모델이 지역 및 시간에 따라 다를 수 있다는 것을 의미한다. 이는 모든 시공간에서 좋은 성능을 보이도록 AI 모델을 학습시키는 것은 매우 어려운 문제라는 사실을 의미한다.
대부분의 지질자원 분야의 관심 현상은 시공간적으로 드물게 발생하기 때문에 지질자원 분야 데이터를 통해 변화나 현상을 분류하거나 파악하는 것은 현상 관측치 혹은 모니터링 데이터 수가 부족하다는 문제와 직결된다. 또한 현상의 희소성 문제는 데이터의 불확실성 및 편향성 문제를 발생시킬 수 있다.
지질자원 분야 데이터 특성은 다중 해상도(multi-resolution), 불완전성(incompleteness), 한정된 데이터 샘플 수 등을 들 수 있다.
지질자원 분야 데이터 세트는 여러 소스를 통해 다양한 시공간적 해상도로 제공되는데, 이로 인해 샘플링 속도, 정확도, 불확실성과 같은 특성에서도 차이를 보인다. 일반적으로 다양한 해상도의 데이터 세트는 다운스케일링(downscaling)을 적용하여 높은 해상도로 일치시킨다. 하지만 이 과정에서 예기치 못한 불확실성이 개입될 가능성이 있기 때문에 다중 해상도 환경 하에서 주어진 데이터 세트의 패턴을 찾을 수 있게 하는 알고리즘이 필요하다.
지질자원 분야의 관측, 계측, 센싱 환경은 다양한 잡음원에 항상 노출되어 있다. 또한 관심 변량은 직접 측정하기 어려운 경우가 많기 때문에 관련성이 있는 다른 변량을 측정하거나 모델링의 결과로부터 유추하는 경우가 많다. 따라서 지질자원 분야 데이터는 불확실성이 있는 불완전한 데이터이다. 또한 현상의 희소성과 관측 방법의 특성으로 인해 시공간적 데이터 샘플 수가 한정적일 수밖에 없다. 게다가 지구시스템에 발생하는 많은 현상들을 완전하게 규명 혹은 검증할 수 있는 실측자료가 존재하지 않는 경우도 많다.
지질자원 분야에서 다루는 현상(혹은 프로세스)과 데이터가 지닌 특성 및 환경으로 인하여 전통적 AI는 샘플링 편향, 주변 영향 인자의 영향 고려 부족, 통계적 연관성 및 인과관계의 불명확성, 다중가설검증의 근본적 결함 등 여러 한계점을 보인다. 특히 계측 기술의 발달로 시공간 자료에 대한 해석 및 예측의 필요성이 높아지고 있고 탐사기술과 모델링 기술의 발전으로 소프트데이터3)(soft data)의 활용이 매우 중요해지고 있다. 최근 딥러닝 알고리즘의 발전으로 이미지 인식과 같은 공간학습(spatial learning)과 음성인식과 같은 시퀀스학습(sequence learning)은 지구시스템의 2차원 혹은 3차원 현장자료 및 시계열 형태의 동적 자료 처리에 있어 유사 적용이 가능하다.
그런데 딥러닝과 같은 최근의 AI 기술을 지질자원 분야에서 성공적으로 적용하기 위해서는 몇 가지 해결해야 할 과제가 있다. 이에는 인과관계 규명 및 모델 해석(interpretability)의 어려움, 물리적 일관성(physical consistency) 문제, 데이터의 복잡성과 불확실성 문제, 레이블된 자료의 부족, 높은 연산 비용 등을 들 수 있다(Reichstein et al., 2019). 이와 같은 지질자원 분야의 현상과 데이터 환경 특성을 효과적으로 고려할 수 있는 AI 활용 체계를 GeoAI라고 정의할 수 있다.
지질자원 분야의 GeoAI 활용방안으로는 nowcasting(매우 근접한 미래의 예측, 시간 단위의 예측), forecasting(장기간 미래의 예측), 이상감지, 시공간 자료 기반의 지하물성 분류 등을 들 수 있다. 이에는 한정된 자료로부터 최대 학습을 이끌어 내고 최적화된 예측을 수행하면서 동시에 물리적으로도 설명이 가능한 모델을 만드는 것이 필수적으로 동반된다. 이를 가능케 하는 하나의 방안으로 물리모델과 AI가 결합한 융합모델이 있다.
물리모델과 AI의 결합: 이론기반 데이터과학모델
일반적인 과학 영역 문제는 물리적 변수와 물리현상 간의 관계를 표현하는 데 집중되어 있다. 이러한 관계를 표현하는 기존 접근법은 물리모델을 사용하는 것으로서 실험적으로 입증되었거나 원리에서 추론된 변수 간의 인과관계로 정리하는 것이다. 이러한 물리모델은 자연현상과 관련된 지배방정식(governing equation)의 해를 찾는 것을 의미하며, 분석적 접근법과 수치해석과 같은 전산 시뮬레이션 등의 방법이 존재한다. 다른 접근법은 AI모델을 사용하는 것으로 입력(원인) 및 출력(결과) 변수와 관련된 일련의 데이터를 이용하여 변수 사이의 관계를 자동으로 추출할 수 있는 데이터 과학모델을 학습하는 것이다. 물리모델은 자연현상을 설명할 수 있는 알려진 과학적 원리에 기초하여 모델링하기 때문에 개념적으로 이해하기 쉬운 프로세스를 표현하는 데 적합한 반면, 데이터과학모델은 주로 데이터에 포함된 정보에 의존하기 때문에 데이터 샘플이 풍부하게 제공되는 분야에서 광범위하게 적용할 수 있다.
물리모델에 기초한 접근법은 현상에 대한 자연법칙 하에서 직접적인 해석이 가능하며, 모델링의 제약조건을 넘어서는 부분에 대해서는 자연 법칙에 입각한 외삽이 가능하다. 반면에 데이터과학모델은 주어진 데이터에 맞추어 매우 유연하게 모델링할 수 있으며 이론적으로 규명되지 않은 현상을 발견할 수 있다.
각각의 장점에도 불구하고 물리모델과 데이터과학모델은 지질자원 분야에서 다루는 현상(혹은 프로세스)과 데이터가 지닌 특성 및 환경으로 인해 한계성을 보이는 경우가 종종 있다. 특히 지구시스템에 벌어지는 현상들은 본질적인 복잡성으로 인해 현재의 물리모델로는 완전히 설명되지 않는 과정들을 포함하며, 물리적 프로세스에 대한 여러 가지 단순화 가정을 요구하는 어려움이 동반한다. 이는 부정확성을 초래할 뿐만 아니라 모델을 이해하고 분석하기 어렵게 만든다. 데이터과학모델도 모델의 복잡성에 비해 데이터가 부족하고 높은 불확실성으로 인하여 과학적 원리와는 동떨어진 결과를 초래할 수 있다. 또한 다양한 매개변수들의 시공간적 변화는 데이터과학모델의 효과를 저하시킨다.
따라서 물리모델과 데이터과학모델이 상호 보완하기 위해 이론기반 데이터과학모델(theory-guided data science)과 같은 결합된 모델이 필요하다(Karpatne et al., 2017). 이론기반 데이터과학모델은 문제의 일부를 물리모델의 구성 요소로 처리하고 나머지는 데이터과학모델의 구성 요소로 분리하여 모델링하는 방식과 현재 누락되었거나 부정확하게 추정된 물리모델의 중간 결과를 데이터과학 방법으로 예측하여 접근하는 방식으로 구분할 수 있다. 후자의 경우 데이터과학모델의 결과를 편미분방정식(partial differential equation)로 표현되는 물리모델에 제공함으로써 더 나은 예측 성능을 보여줄 뿐만 아니라 기존 물리모델의 결함을 개선할 수 있는데 이를 융합전산해석(physical based and data driven model)으로 정의할 수 있다. 또한 물리모델의 결과를 데이터과학모델의 구성 요소 학습 샘플로 사용될 수도 있으므로 이들 사이에 양방향 시너지 효과를 얻을 수 있다(Sadowski et al., 2016; Long et al., 2018)(Fig. 8).
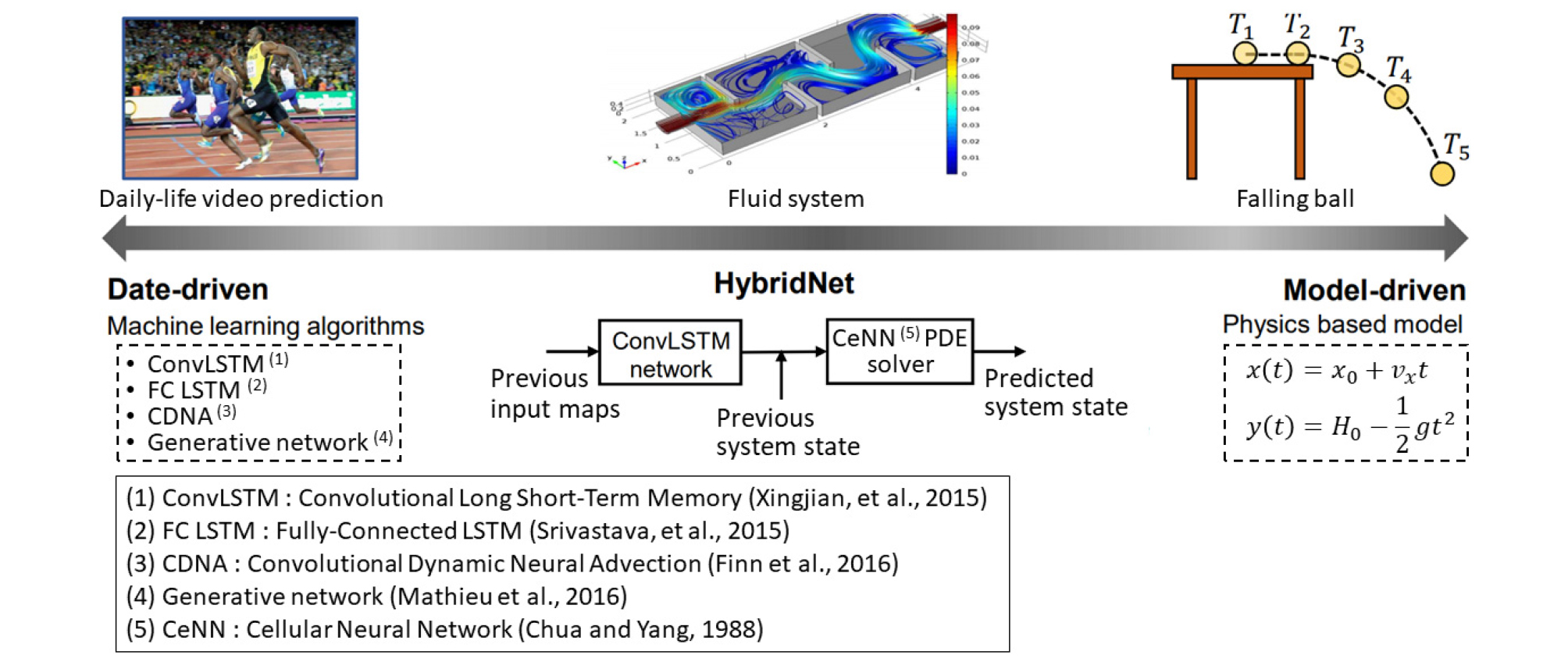
Fig. 8.
An illustration of different modeling approaches for dynamical systems (modified from Long et al., 2018).
지질자원 분야의 특수성을 고려하는 방법으로 이론기반 데이터과학모델 혹은 융합전산해석을 고려할 수 있다. 이를 통해 얻을 수 있는 잠재적 시너지 효과를 다음과 같이 정리할 수 있다(Reichstein et al., 2019).
(1) 매개변수화 개선(improving parameterization): 물리모델은 매개변수가 필요하며, 매개변수는 공리(axiom)로 부터 쉽게 유도하기 힘든 경우가 많다. AI는 공리에 기초한 모델로부터 생성되거나 직접 관측된 데이터로부터 매개변수를 유도하고 학습할 수 있다. 또한 고해상도의 데이터나 모델로부터 적절한 해상도의 매개변수로 변환할 수 있어 모델의 연산효율을 높일 수도 있다.
(2) AI로 하위모델 대체(replacing a ‘physical’ sub-model with AI): 물리모델을 구성하는 하위모델이 물리적 의미에서의 일관성이 부족하고 대신 데이터가 충분할 경우 이를 AI로 대체할 수 있다. 이를 통해 이론적 근거와 데이터를 동시에 만족하는 하이브리드 모델을 생성할 수 있다.
(3) 모델과 관측치의 불일치 분석(analysis of model- observation mismatch): 관찰편향(observational biases)이 없다는 가정 하에서는 물리모델 예측치와 관측치의 차이를 물리모델의 불완전성에 기인하는 모델 오류로 인식할 수 있다. AI를 통해 물리모델에서는 명확히 정의하기 힘든 오류의 패턴을 식별하고 시각화함으로써 모델 결과를 동적으로 보정할 수 있다.
(4) 하위모델 상호조건화(constraining sub-models): 하나의 하위모델을 통해 생성된 데이터는 다른 매개변수 학습을 위한 다른 하위모델의 입력 자료로 활용할 수 있으며, 각 하위모델에서 생성된 자료를 교차하여 입력 자료로 활용함으로써 편향성 감소 효과와 모델 인자의 보정효과를 얻을 수 있다.
(5) 근사 모델 혹은 에뮬레이션(surrogate modelling or emulation): 물리모델이 통합된 AI 에뮬레이터는 물리모델의 정확성을 유지하면서 모델 시뮬레이션 속도를 수십~수백 배 향상시킬 수 있다. 이로써 민감도 분석 모델 생성, 모델의 파라미터 조정, 모델 평가를 위한 신뢰구간 도출 등의 작업이 가능하다.
결 론
4차 산업혁명이 일으킨 새로운 패러다임 변화는 지질자원 분야 기술 및 산업에 있어 기회이자 도전이 될 수 있다. 4차 산업혁명의 혁신 기술과 지질자원 분야 지식의 융합화는 지질자원 기술과 시민사회의 공진화뿐만 아니라 지질자원 분야가 지닌 공공성을 강화시킬 수 있는 기회를 제공한다.
특히 지질자원 분야의 특수성과 기능성을 충족할 수 있는 CPS와 AI의 확장 모델로서 GeoCPS 및 GeoAI의 개념을 제시하였다. 나아가 지질자원 분야 기술 및 산업을 위한 지질자원 기술과 ICT의 학제 간 융합 분야로의 Geo-ICT 발전 가능성을 확인하였다.
디지털 마이닝/스마트 마이닝은 전주기 지질자원 분야 지식과 IoT 및 AI 기술이 적절한 통신환경 하에서 융합되어 하나로 체계화되는 과정을 통해 구현할 수 있다. 국내 자원산업의 환경을 고려할 때 공정 단계별로 맞춤식 스마트화를 진행시키는 것이 효과적일 것이며, 완전 무인화의 목표보다는 장비 간 혹은 장비와 작업자 간 맞춤형 커넥티드 마이닝(connected mining)의 구현이 보다 현실적이다. 이를 위해 현재 구축되어 있는 유선망과 무선 네크워크 간 통합화와 같은 갱내 통신 네트워크 효율화 및 갱내 무선 통신 가이드라인 재정이 선행되어야 한다.
딥러닝과 같은 최근의 AI 기술을 지질자원 분야에서 성공적으로 적용하기 위해서는 인과관계 규명 및 모델 해석의 어려움, 물리적 일관성 문제, 데이터의 복잡성과 불확실성 문제, 레이블된 자료의 부족, 높은 연산 비용 등의 도전적인 과제를 선결해야 한다. 지질자원 이론기반 데이터과학모델은 전통적 AI가 지질자원 분야에 적용될 시 지닌 한계성을 극복하기 위한 AI 활용 모델이 될 수 있으며, 매개변수화 개선, AI로 하위모델 대체, 모델과 관측치의 불일치 분석, 하위모델 상호조건화, 에뮬레이션 등의 시너지 효과를 기대할 수 있다.
지질자원 분야는 지구물리, 지구화학, 석유공학, 암석역학, 자원처리, 지구통계학, 지오메카닉스, 자원경제학 등과 같이 학제 간 융합 형태로 발전해 왔다. GeoCPS와 GeoAI 등 Geo-ICT가 ICT를 단순히 지질자원 분야에 적용하는 활용기술에 머물지 않고 하나의 융합 학문 분야로 발전을 위해서는 지구과학 및 자원공학의 이론과 기술, 즉 지질자원 분야의 학제를 유지시켜 온 기초 분야의 지속적인 발전이 함께 이루어져야만 가능하다.
