

서 론
미래의 경제 흐름을 예측하고 분석하는 것은 오랜 시간 동안 학계에서 다양한 방법으로 시도되고 있고 정책적으로도 중요한 의미를 가지고 있다. 그러한 측면에서 주식 가격이나 원자재(commodity) 가격에 대한 예측 또한 많은 연구가 진행되어 왔다. 원자재 가격 중에서 본 연구에서 예측하고자 하는 천연가스 가격 또한 고유가와 생산기술 혁신으로 인하여 비전통가스 개발 사업이 활발하게 이루어짐에 따라 최근 많은 주목을 받고 있다.
천연가스는 개발 특성과 상대적으로 어려운 운송·보관 문제로 인하여 원유에 비해 시장이 덜 발달되어 있다. 이에 Henry Hub, NBP(National Balancing Point)같이 수요・공급에 따라 가격이 결정되는 시장도 상당 기간 동안 원유 가격과 동조하여(coupling) 가격이 움직여 왔으며, 대표적인 가스가격 지수가 없는 아시아나 유럽의 경우 대부분 원유 가격에 연동되어 가스가격이 결정되어 왔다. 그런데 최근 들어 Henry Hub이 원유가격과 동조화 경향이 약해짐에 따라 천연가스 가격 변동이 지역별로 다르게 나타나고 있으며 국제 유가와 천연가스 가격 사이에 탈동조화(decoupling) 현상이 관찰되고 있다(Hwang et al., 2012). 천연가스의 현물거래나 단기도입의 비중 또한 점차 확대되는 추세를 보이고 있으며, 아시아 지역에도 천연가스 선물 시장이 도입될 것으로 예상되어 앞으로 가스가격 예측이 중요해질 것이라 판단된다(Hartley et al., 2013).
하지만 기존 연구들은 대부분 선형모형을 기반으로 가스 가격을 예측하고 있고, 이는 예측 가능성을 검증 하는데 있어 충분한 모형이 되지 못할 수 있다. 가스가격을 선형모형으로 설명하기에는 거래제도나 규제 등 시장의 불완전성으로 인한 특이패턴이 존재 할 수 있기 때문이다(Jeong and Yun, 1998). 이에 본 연구에서는 비선형 모형 중 하나인 인공신경망(artificial neural network, ANN)을 사용하여 가스가격을 예측하고자 한다. 인공신경망은 주어진 환경에 대해 학습능력을 가지고 있기 때문에 다양한 분야에서 응용되어 왔으며, 가스 가격 같이 명확한 함수 형식으로 규명되지 못한 사례에 적합한 방식이라고 할 수 있다. 본 연구에서 다루고자 하는 Henry Hub 가격은 선물거래소에서 결정되는 만큼 다양한 변수의 영향을 받는다고 판단되는데, 인공신경망을 이용하면 가스 가격에 대한 시계열 자료만을 가지고 우수한 예측력을 가진 예측모형을 만들 수 있으리라 예상된다.
본 연구에서는 단기 천연가스 가격 예측을 위해 역전파(back-propagation) 인공신경망을 사용하여 모형 설계를 하였으며, 보다 적합한 모형을 찾기 위해 전통적인 인공신경망 방식과 연속(cascade) 인공신경망 방식을 비교 분석 하였다. 그리고 학습 자료의 양에 따른 모형 적합도를 판별하고자 학습 기간을 조절하여 모형을 비교하였으며, 마지막으로 전통적인 시계열 예측 모형인 ARIMA (Autoregressive Integrated Moving Average)모형을 이용해 예측력을 비교해보았다.1) 분석 자료는 2000년 1월부터 2013년 9월까지 Henry Hub 가격의 일간 자료를 사용하였으며 예측결과 비교를 위해 RMSE(Root Mean Squared Error)를 중심으로 MAE(Mean Absolute Error)와 MAPE(Mean Absolute Percentage Error)를 살펴보았다.
선행 연구
인공 신경망은 1943년부터 연구가 진행되어 왔으며 인간의 두뇌를 모방한 수학적 모형들이 제안되어왔다. Rosenblatt(1958)는 퍼셉트론(perceptron)이라는 개념을 제안하였으며 학습을 통해 가중치를 설정하여 출력하는 기초적인 인공신경망을 구축하였다. 이는 1980년대에 이르러 다층 퍼셉트론(multilayer perceptron)으로 다시 재조명 되었으며, Rumelhart(1986a)와 Rumelhart(1986b)에서 역전파 알고리즘이 제안되어 다양한 연구가 이루어졌다.
Zhang 등(1998)은 인공신경망을 사용한 예측 방법 전반에 대해 기술하고 있다. 인공신경망 분야의 연구를 총 망라하여 정리하고, 모형 구축 기법을 설명하며 앞으로 나아갈 연구 목표를 제시하였다. 인공신경망 모형을 시계열 자료에 어떻게 적용시켜야 하며, 그 과정에서 생기는 문제점과 해결방법, 그리고 시계열 자료에 따른 인공신경망 예측 모형의 설정 방법 등을 소개하였으며, 특히 그 동안 연구되어 왔던 인공신경망 모형을 정리해 줌으로서 연구자들이 이를 바탕으로 하여 발전된 모형을 구축하는데 도움을 준다. 또한 경험적인 방법을 통하여 매개 변수를 설정해 주어야 하는 인공신경망의 특성상 그 간의 연구에 쓰인 매개 변수들을 참고하여 연구를 진행시켜 나갈 수 있도록 제시해 주고 있다. 이 연구는 각 연구에 사용된 데이터 종류와 크기, 입력 노드(node)와 은닉층(hidden layer) 개수, 학습 알고리즘 등을 정리해 주고 있는데 이 점을 활용하여 분석에 가장 적합한 인공신경망 모형을 찾아내는 것에 쉽게 접근할 수 있다.
Cooper(1999)는 역전파 인공신경망의 기본적인 이론을 설명하고 인공신경망을 통해 국제 경제 분야의 문제점을 해결하기 위한 방향을 제시하고 있다. 인공신경망의 기초가 되는 다층 퍼셉트론의 이론을 설명하고 이를 기반으로 발전시킨 역전파 알고리즘을 설명하였다. 또한 전통적인 다 변량 통계 기법과 비교하여 인공신경망이 잠재적으로 가치가 있음을 보여주었다. Lee 등(2005)은 비상장주식의 가치 평가를 위해 인공신경망을 사용하고 있다. 기존의 보충적 평가방법과 인공신경망 모형 평가방법을 비교하여 분석하며 인공신경망 모형의 우수성을 제시하였다. 이 연구에서는 은닉층을 1개, 은닉 노드는 9개로 설정하고 2001년 말 증권거래소에 상장되어 있는 기업의 재무자료를 이용하여 모형 구축을 하였다. 평가액을 고평가 표본, 유사 평가 표본, 저평가 표본으로 나눈 뒤 보충적 평가방법과 인공신경망을 비교하였으며 모든 부분에서 인공신경망 모형이 더 적합한 평가 방법이라고 결론짓고 있다.
Malik and Nasereddin(2006)은 연속 인공신경망을 이용하여 원유 가격과 미국 실질 GDP의 관계를 규명하고 GDP의 단기 예측을 시행하였다. 이 연구에서는 1947년 1월부터 2004년 12월까지 232개의 자료를 바탕으로 연속 인공신경망을 사용하여 예측하였다. 또한 6가지 다른 예측 방식으로 예측치를 산출해 내고 MAE와 MSE(Mean Squared Error)로 예측 정확도를 비교분석 하였다. 자기회귀 방식 예측, 일반 선형 모형을 이용한 예측, 전통적인 인공신경망 예측, 그리고 원유 가격을 고려하지 않고 GDP 자료만으로 연속 인공신경망을 적용하여 산출해낸 예측값을 산출하여 비교하였다. 단기・장기 예측 두 부분 다 원유가격을 고려한 연속 인공신경망 모형이 가장 적합한 모형으로 결론짓고 있는데, 전통적인 기본 인공신경망은 오히려 자기회귀 방식보다 예측력이 떨어지는 것으로 나와 이전의 연구에서 인공신경망을 통한 예측을 다루지 않았던 점을 설명해주고 있다. 반면 연속 인공신경망은 가장 뛰어난 예측을 보여주어 다양한 예측 부문에서 적용해볼 만한 방식임을 제안하였다.
Lee(2008)는 유전자 알고리즘을 기반으로 로지스틱 회귀분석(logistic regression), 인공신경망, Support Vector Machine을 결합하여 구축한 모형을 Korea Composite Stock Price Index 예측에 적용시켰다. 기존에 연속된 결과를 산출해 낼 수 없었던 위 3가지의 인공지능기법을 유전자 알고리즘으로 통합하여 기존 방법에 비해 높은 정확도를 보이는 모형을 제안하였다. “WAVG+T”로 명명된 이 모형은 각 기존 모형의 가중치와 임계치를 최적화하는 새로운 모형으로 예측 정확도를 비교한 결과 가장 우수한 모형임이 입증되었고 향후 다양한 경제, 경영 분야에서 응용될 수 있음을 시사하였다.
이상의 연구에서 볼 수 있듯이 인공신경망은 시계열 분석과 예측을 위한 다양한 분야에 활용되어 왔다. 앞서 언급한 바와 같이 본 연구에서는 천연가스 가격의 단기 예측을 위하여 인공신경망이 유의하게 활용될 수 있는가를 확인하고, ANN 모형 설정과 입력 노드, 은닉층을 변경하여 최적의 인공신경망 모형을 도출해 보고자 한다.
분석 방법론
인공신경망은 자기 학습능력을 가지고 있기 때문에 재무, 회계, 마케팅 등 다양한 분야에서 응용되고 있다. 또한 복잡하고 다양한 자료를 비교적 쉽게 처리할 수 있으며 질적 변수, 양적 변수에 상관없이 분석이 가능하고 예측력이 우수하다(Kim, 2005). 기본적인 다층 인공신경망의 입력층, 은닉층, 출력층의 관계는 다음의 과정을 거친다(Cooper, 1999).
은닉층의 입력값 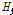 는 다음과 같이 설정할 수 있다.
는 다음과 같이 설정할 수 있다.
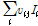 (1)
(1)
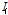 는 입력층의 I 번째 입력값이며
는 입력층의 I 번째 입력값이며 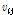 는 I 번째 입력층과 j 번째 은닉층을 연결하는 가중치를 나타낸다. 또한
는 I 번째 입력층과 j 번째 은닉층을 연결하는 가중치를 나타낸다. 또한 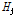 의 출력값은 다음과 같다.
의 출력값은 다음과 같다.
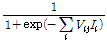 (2)
(2)
이 은닉층에서 출력된 값이 가중치 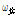 를 통해 출력층에 다음과 같이 입력된다.
를 통해 출력층에 다음과 같이 입력된다.
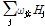 (3)
(3)
최종적으로 k번째 출력층 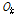 에서 다음과 같이 출력되게 된다.
에서 다음과 같이 출력되게 된다.
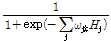 (4)
(4)
즉, 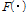 가 로지스틱 함수(logistic function)이라고 할 때
가 로지스틱 함수(logistic function)이라고 할 때
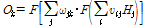 (5)
(5)
위의 식이 성립되며, 출력값이 산출되면 실제값 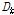 와 차이를 통해 오차를 구하게 된다. 입력층의 각 요소에 입력신호를 주면, 이 신호는 변환되어 은닉요소에 전달되고 마지막으로 출력층에서 신호를 출력하게 된다. 인공신경망은 이 출력값과 기대값을 비교하여 그 오차를 줄여나가는 방향으로 연결강도를 조절한다.
와 차이를 통해 오차를 구하게 된다. 입력층의 각 요소에 입력신호를 주면, 이 신호는 변환되어 은닉요소에 전달되고 마지막으로 출력층에서 신호를 출력하게 된다. 인공신경망은 이 출력값과 기대값을 비교하여 그 오차를 줄여나가는 방향으로 연결강도를 조절한다.
인공신경망에서 가장 많이 사용되는 비선형 함수로 계단함수(hard limiter), 임계논리함수(threshold logic), 시그모이드 함수(sigmoid function) 등이 있으며 이 중 시그모이드 함수가 가장 많이 사용된다(Kim, 2005). 시그모이드 함수는 0~1 사이의 값을 가지며 다음과 같은 식을 가진다.
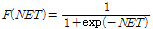 (6)
(6)
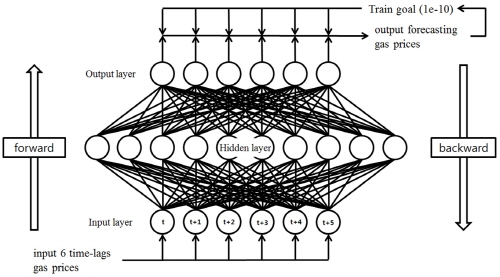
역전파 학습 알고리즘은 다층 퍼셉트론 인공신경망에서 가장 많이 쓰이는 알고리즘으로 입력층과 출력층 사이에 1개 이상의 은닉층을 가진 다층 퍼셉트론 인공신경망에서 오차가 출력 노드로부터 내부 노드로 역 전파하며 연결강도를 조절해 나가는 방법이다. 이 역전파 학습 알고리즘은 학습과정이 수렴되기 까지 많은 양의 학습데이터를 필요로 하고 학습된 패턴의 수정이나 추가적인 학습이 불가능하지만 그럼에도 구현이 쉽고 빠른 학습이 가능하기 때문에 가장 많이 사용되고 있는 알고리즘이다(Kim, 2005). 본 논문에서는 시그모이드 함수를 이용한 다층 퍼셉트론 인공신경망을 역전파 학습 알고리즘으로 학습시켰다. Fig. 1은 6개의 입력 노드, 즉 시계열 자료 상에서는 6개의 과거 천연가스 가격을 입력 자료로 가지는 입력층과 1개의 은닉층, 그리고 10개의 은닉 노드를 가진 가스 가격 예측 모형의 학습 과정을 보이고 있다.
또한 이러한 역전파 알고리즘을 토대로 전통적인 비 연속(non-cascading) 인공신경망 방식과 연속 인공신경망 방식을 사용하여 분석하였다. 연속 방식은 학습 알고리즘에 산출된 예측값이 포함되어 다시 학습 과정을 거쳐 그 다음 시점의 예측값을 산출해 내는 방식으로 계속 학습 과정이 갱신 된다는 장점을 가진다.
본 논문에서는 각 모형의 정확도를 비교하기 위해 시계열 분석 시 대표적으로 사용되는 지표인 RMSE를 중심으로 MAE, MAPE를 사용하였으며 알고리즘 구현은 Matlab 프로그램을 사용하였다.
분석 결과
분석 자료 및 개요
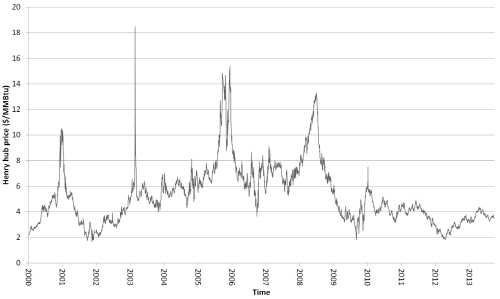
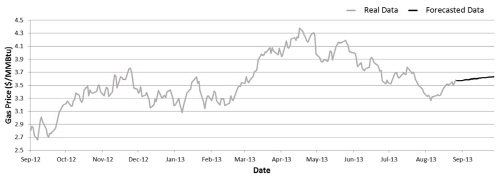
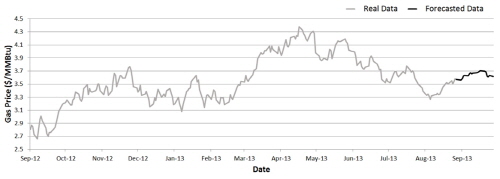
실증분석을 위하여 2000년 1월부터 2013년 9월까지 3439개의 일간 Henry Hub 현물 가격(spot prices)을 사용하였다(Fig. 2). Henry Hub는 미국 루이지애나(Louisiana)주에 위치한 천연가스 배관망의 집결지로 국제석유기업 셰브론(Chevron)의 자회사인 사빈 파이프라인(Sabine pipe line)이 운영하고 있으며, 9개 주 113개의 파이프라인과 연결되어 있다. 북미시장의 Henry Hub 외에 대표적인 세계 천연가스 가격 지수로 런던 국제석유거래소에서 거래되는 NBP가 있다. 하지만 Henry Hub는 2005년, 미국 연간 가스 생산량의 약 44%를 차지하며 현물 시장에서 큰 규모로 거래되고 있고 뉴욕상업거래소(NYMEX)로부터 천연가스선물계약소로 선정된 이래 천연가스선물의 기준가격으로 활용되고 있기 때문에 국제 천연가스 가격 결정에 NBP보다 비교 우위에 놓여있다고 볼 수 있다(Mazighi, 2005). 또한 유가연동 결정방식을 따르는 인도네시아 LNG나 러시아 천연가스 가격은 천연가스의 수급상황 외에도 석유시장의 수급여건 등에 크게 영향을 받는다. 이에 본 논문에서는 Henry Hub 현물 가격을 이용하여 단기 가격예측을 수행하였다.
학습(training) 자료는 2000년 1월부터 2012년 12월까지, 확인(test) 자료는 2013년 1월부터 8월까지로 설정하였다. 그리고 학습된 인공신경망으로 표본 외 예측(out- of-sample forecasting)을 위해 마지막 2013년 9월 한 달을 예측하여 실제 자료와 비교하였다. 은닉층은 1개로 설정하였으며 은닉층 노드 개수와 입력 노드 개수를 각각 변화시켜 최적의 예측 결과를 산출하고자 하였다. Dutta and Shashi(1988)와 Salchenberger 등(1992) 따르면 은닉층을 2개 이상 증가시킨다 하더라도 1개일 때 보다 예측률이 크게 향상되지 않는 것을 보이기 때문에 은닉층은 1개로 고정하였다.
최적 모형을 찾기 위해 전통적인 인공신경망 방식과 연속 인공신경망 방식, 그리고 학습 자료의 기간을 조절하여 모형을 비교・분석하였으며 ARIMA 모형과의 비교도 수행하였다. ARIMA 모형의 경우, Prybutok 등(2000)과 Gutierrez-Estrada 등(2004)에서 ANN 모형과 예측결과를 비교하여 ANN 모형의 우수성을 밝히고 있다. 사실 ARIMA보다 예측력이 뛰어나다고 해당 모형의 예측력이 우수하다는 것을 단정지을 수는 없다. 그러나 본 연구의 목적은 ANN이 천연가스 예측에 활용될 수 있는지를 확인하고, ANN 예측 시 설정해야 하는 여러 변수에 대한 시뮬레이션을 통하여 천연가스 예측을 위한 최적 ANN 모형을 제시하는 것이므로 모형의 예측력 비교는 ARIMA에 한정한다. 단기 천연가스 예측력이 가장 우수한 모형에 대한 연구는 후속 작업으로 남겨둔다.
분석 결과
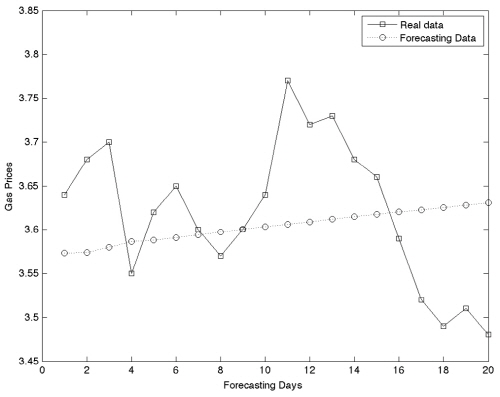
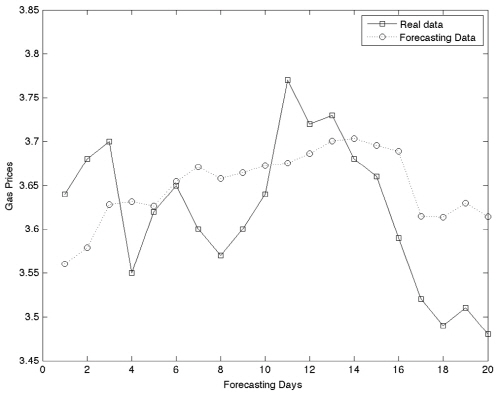
Table 1은 비 연속 방식으로 예측을 수행한 결과이며 은닉층 노드 개수는 2∼10까지, 입력 노드 개수는 4∼10까지 설정하여 분석하였다. 분석 결과 비 연속 방식에서는 2개의 은닉층 노드와 6개의 입력 노드일 경우에 가장 낮은 RMSE인 0.0904를 보이며 MAE는 0.0764, MAPE는 2.1092로 나타났다.
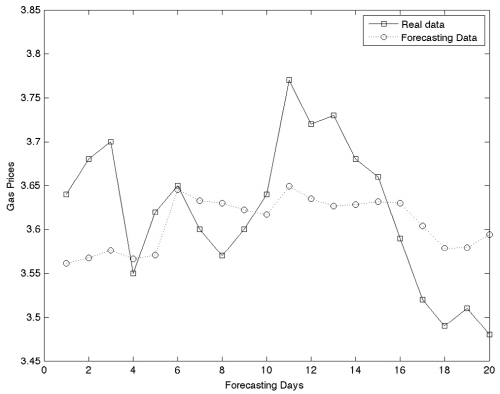
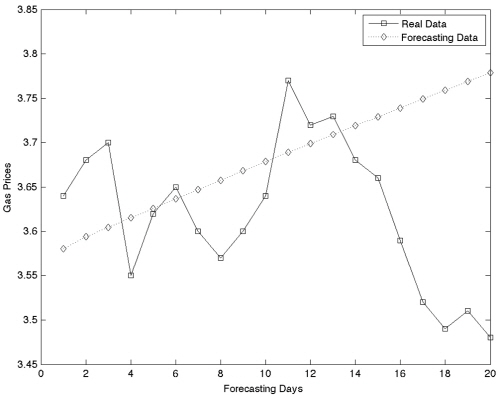
Table 2는 연속 방식으로 산출한 결과이며 10개의 은닉층 노드, 6개의 입력노드일 경우 0.0751로 가장 낮은 RMSE를 보이고 있으며, MAE는 0.0654, MAPE는 1.8049로 산출되었다.
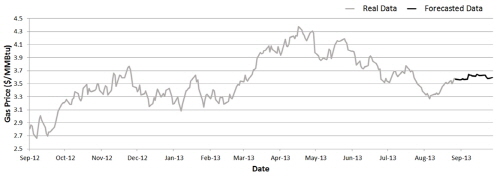
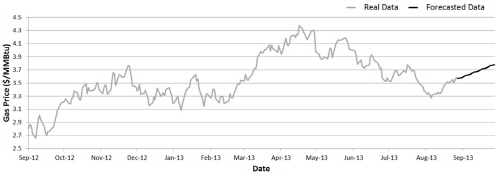
Table 3은 트레이닝 자료를 1년, 즉 2012년 9월부터 2013년 8월까지 기간으로 변경하여 연속 방식으로 분석해 본 결과이다. 이 경우에는 은닉층 노드가 8개, 입력 노드가 5개일 때 가장 낮은 RMSE 값을 보이고 있다. 그리고 이 때의 MAE는 0.0695, MAPE는 1.9352로 나타났다.
3가지 방식으로 훈련을 시킨 뒤 예측결과를 비교해보았을 때 가장 낮은 RMSE 값을 보이는 것은 3,419개의 자료로 학습시킨 연속 방식 모형이며, RMSE 값은 0.0751로 산출되었다. 전체적인 그래프의 양상을 보더라도 비 연속 방식이나 1년의 학습 자료로 훈련시킨 인공신경망 보다 연속 방식이 실제 자료와 더 비슷한 추세를 쫓아가고 있는 것을 볼 수 있다(Fig. 3~5). Kim(2005)에 따르면 역전파 인공신경망의 학습이 수렴되어 완료되기 위해서는 많은 양의 학습 자료가 필요하다. 때문에 251개의 학습자료 보다 3,419개의 학습자료로 훈련시킨 것이 더 좋은 결과를 나타내는 것은 더 효과적인 학습이 이루어 졌다는 의미이며 자연스러운 결과로 볼 수 있다.
본 연구와 마찬가지로 Malik and Nasereddin(2006) 또한 자기회귀 방식과 일반 선형 모형을 통한 예측보다 연속 방식을 사용한 인공신경망 예측이 더 정확함을 보여주고 있다. 여기에 Malik and Nasereddin(2006)에서 고려하지 않았던 ARIMA 모형을 사용한 예측치와 인공신경망 예측치를 추가 비교해보았다. Akaike 정보 기준(information criterion)을 통해 차수를 ARIMA(1, 0, 3)으로 결정하고 1개월 예측치를 산출하였다. 그 결과는 Fig. 6와 같고 RMSE 값은 0.1338로 연속 인공신경망 보다 상당히 큰 값이 산출되었다. 또한 MAE는 0.1002 MAPE는 2.8107으로 나타났다.
비 연속 방식을 사용한 인공신경망은 입력 노드 2개, 은닉 노드 6개에서 RMSE가 0.0904로 가장 낮은 값을 가지고 연속 방식을 사용한 인공신경망은 입력 노드 6개, 은닉 노드 10개에서 0.0751로 가장 낮은 RMSE값을 가진다. 비 연속 방식을 사용한 인공신경망의 경우 특정 시점 예측치(t)가 다음 시점 예측치(t+1)의 출력값 산출에 영향을 끼치지 않기 때문에(비 연속 방식이기 때문에) 예측값이 선형적으로 증가하는 결과를 가진다. 반면 연속 방식은 특정 시점 예측치가 다음 학습에 포함되어 다음 시점 예측값에 영향을 주기 때문에 더 작은 RMSE값을 가지는 모형을 구축할 수 있게 된다. 또한 1년의 자료로 학습한 인공신경망은 입력 노드가 8개, 은닉 노드가 5개 일 때 RMSE가 0.0793으로 산출되었고 12년 8개월의 자료로 학습한 인공신경망과 0.0042밖에 차이가 나지 않는다. 이는 학습과정이 수렴되기 까지 많은 양의 자료를 필요로 하는 인공신경망의 특성을 반영한 결과라
|
|
Fig. 3. ANN forecasting results using the non-cascading method. |
|
|
Fig. 4. ANN forecasting results using the cascading method. |
|
|
Fig. 5. ANN forecasting results using the cascading method (1-year training). |
|
|
Fig. 6. Forecasting results using the ARIMA(1, 0, 3) model. |
할 수 있다. 마지막으로 ARIMA(1, 0, 3)에서 예측한 가스가격 결과는 RMSE가 0.1338로 연속 인공신경망에 비해 높은 RMSE값을 가진다. 또한 ARIMA는 예측기간이 길어질 수록 계속 증가하는 경향을 보여 결국 더 큰 RMSE가 나타날 것으로 판단된다.
결 론
본 연구에서는 천연가스 가격의 단기 예측을 위하여 기존의 통계적 기법 대신 인공신경망을 이용하여 예측을 수행하였다. 모형 설계를 위하여 인공신경망을 3가지 방식으로 프로그래밍하고 각 모형의 정확도를 비교 분석하였으며 가스 가격 예측을 위해 가장 적합한 방식을 선정하였다. 또한 경험적 방법에 의해 모형 변수를 설정해야 하는 인공신경망의 특성 상, 입력 노드 개수를 4∼10개 그리고 은닉 노드 개수는 2∼10개로 변화시켜 가며 최적의 모형을 찾아내었다.
연구 결과 비 연속 방식은 연속 방식에 비해 높은 RMSE값을 가지며 예측 기간이 길어질수록 선형적으로 증가하는 결과를 보였다. 이는 신경망 학습과정에서 바로 전 예측치를 포함하여 다시 학습하느냐 하지 않느냐에 따라 나타난 결과로 연속 방식이 더 정확한 예측값을 산출해 내는 것을 확인할 수 있었다. 학습 기간을 변경하여 분석한 결과, 학습기간이 긴 인공신경망이 더 정확한 예측값을 산출하였다. 하지만 특정 시계열, 즉, 가스 가격 예측에서 많은(3,419개) 자료로 학습시킨 인공신경망이 더 적합하다고 해서 다른 시계열에서도 같은 결과를 보일 것이라고 단정할 수는 없다. 따라서 앞으로 인공신경망을 다양한 에너지 시계열에 적용시켜보는 연구가 필요할 것으로 판단된다. 그리고 ANN 분석 결과의 RMSE가 ARIMA보다 낮은 것으로 나타났지만, 앞서 언급한 바와 같이 이는 ANN이 천연가스 예측에 활용될 수 있음을 의미하는 것이지 ANN 모형이 최적임을 나타내는 것은 아니다. 또한 본 연구에서 사용한 ANN은 다른 외생변수나 가격결정이론 등이 반영되지 않은 모형이기 때문에 이 점 또한 후속 연구가 필요할 것이다.
결론적으로 인공신경망은 다양한 외생 변수에 의해 영향을 받는 정확한 함수 형태의 규명이 어려울 경우, 비교적 적은 변수로 구성된 시계열을 바탕으로 예측을 수행해야 할 때 적절한 방법론이라고 할 수 있다. 따라서 단기 천연가스 가격 예측에 있어서도 ANN은 충분한 활용 가치를 지닌다. 또한 본 연구를 통하여 ANN 적용 시 비 연속식 모형을 지양하고 연속식 모형을 활용해야 함을 밝혔으며, 천연가스 가격 단기 예측에 있어서 ANN 활용 시 최적 입력 노드와 은닉 노드를 제안하였다. 앞으로 천연가스가격의 탈동조화 현상과 더불어 동아시아 지역에 선물시장이 도입되게 되면, 천연가스 가격의 단기 예측이 더욱 중요하게 될 것이다. 따라서 본 연구는 이러한 변화에 선제적으로 대응한다는 의의를 가진다. 또한 이는 향후 천연가스 가격 관련 금융 거래에 있어 수익률 추정 시 유용하게 활용될 수 있다.
다만 인공신경망 방법론은 자료처리 과정이 블랙박스처럼 기능을 하기 때문에 결과의 해석에 한계점을 가지고 있다. 따라서 인공신경망과 함께, 유가, 기후, 계절 효과, 수요・공급량과 같은 외부 변수를 추가할 수 있는 복합 예측 모형의 개발 또한 적극적으로 고려해야 할 것이다. 또한 앞으로 보다 장기적인 가스 가격 예측을 위해서 인공신경망의 입력 요소들을 wavelet같은 방법으로 전처리 해줌으로써 정확도를 높이는 것도 고려해 볼 수 있다.
