

서 론
연구 지역
연구대상지 선정
연구지역 지질 및 기상 현황
연구지역 광산개발 및 수질정화시설 현황
머신러닝 학습자료 준비 및 학습
자료의 특성 평가
학습자료의 선정
Fancy PCA를 이용한 학습자료증대
CNN모델의 구성 및 학습
학습된 머신러닝 모델의 예측 결과 고찰
결 론
서 론
폐광된 석탄, 금속 및 비금속광산은 총 5,137개로 전국에 걸쳐 분포한다(KOMIR MiRe GiS, 2024). 이들 광산에서 유출되는 광산배수는 광산활동으로 인해 갱구로부터 배출되는 갱내수와 광산폐기물 침출수를 포함하며, Fe, Mn 및 Al과 같은 금속 오염 물질 및 부유물질(suspended solids, SS)이 포함되어 있어 인근 하천 및 농경지에 지속적으로 유입됨으로써 수질 및 토양 오염을 초래하고, 인체에도 영향을 미치고 있다(Younger et al., 2002). 이러한 오염 문제로 지역 주민들의 생활 여건이 악화되고 상수원이 오염되며, 농작물들의 생육에도 지장을 초래하여 삶의 터전에 침해가 발생하고 있어 수질정화가 요구되고 있다. 이러한 광산배수를 정화하기 위해, 국내에서는 1992년부터 적극적 처리(active treatment) 또는 소극적 처리(passive treatment) 방식을 통해 정화 처리를 시행해 오고 있다. 국내 광산배수 처리를 위한 수질정화시설은 총 59개소로, 물리화학 처리시설 21개소(semi-active 10개소 포함)와 자연정화시설 38개소를 운영 중이다(Park et al., 2024). 본 연구 지역인 폐탄광 2개소의 광산배수(ST: 폐석장 침출수, HT: 갱내수)로부터 유출되는 금속 오염 물질인 Fe, Mn 및 Al은 적극적 처리공법으로 제거되고 있다(Figs. 1 and 2).
이러한 광산배수 수질정화시설에 사용되는 소석회 투입량에 대한 깊이 있는 연구는 거의 이루어진 바 없지만, 유입수의 pH 및 각종 금속이온 농도로부터의 이론적 계산식 1을 이용하여 소석회 투입량을 계산하는 경우 실 투입량에 비해 86 ~ 5155%만큼 과다하게 계산되는 것으로 알려져 있다(Kim et al., 2023). 이를 보완하기 위해 PHREEQ-N-AMDTreat(Cravotta, 2020) 모델을 사용하여 소석회 투입량을 계산하고 여기에 보정인자 1.19를 곱하여 소석회 투입량을 추정하는 방법은 오차를 크게 낮추는 것으로 제시되었다(Kim et al., 2023). 단, 해당 모델에서 HT 갱내수에 대해 예측한 소석회 투입량은 실제 투입량의 약 60%로 낮게 추정되었는데, 이는 이 모델에서 소석회 투입량에서 알칼리도를 빼기 때문인 것으로 나타났다.
(Dm: pH 및 금속이온 농도에 따른 소석회의 이론적 투입량(mg/L); 각 농도는 활동도(몰농도와 같다고 가정함)로 표현됨)
따라서 본 연구에서는 이러한 광산배수 수질정화시설의 소석회 투입량을 보다 정확히 예측하기 위해 최근 각광받고 있는 인공지능(artificial intelligence, AI) 기술의 하나인 기계학습(machine learning, ML)을 활용하고자 하였다. 1980년대부터 개발되기 시작한 기계학습은 대규모의 훈련자료(training data) 세트에서 패턴과 상관관계를 찾아 분석하여 최적의 예측 결과를 도출하도록 알고리즘을 훈련시키는 기술이다. 기계학습에서 사용되는 학습방법은 크게 지도학습(supervised learning), 준지도학습(semisupervised learning), 비지도학습(unsupervised learning), 강화학습(reinforcement learning)의 4가지로 구분할 수 있다. 이러한 방법들은 각각의 특성과 적용 분야에 따라 다양한 상황에서 활용된다(Lee et al., 2019). 국외의 경우, 인공지능 기술을 기반으로 하는 수질 관련 예측 연구가 2000년대부터 이미 진행되어 왔다. 광산배수를 대상으로 한 연구에 따르면, 다양한 영향 인자에 따른 수질 변화 예측을 위해 인공 신경망(artificial neural network, ANN) 모델을 사용한 결과, 광산배수의 여러 수질 항목(SO42‒, Cl‒, 화학적 산소 요구량(chemical oxygen demand, COD), 총 용존 고형물(total dissolved solids, TDS) 및 총 부유물질(total suspended solids, TSS))의 예측값이 우수한 성능을 보였다고 보고되었다(Khandelwal and Singh, 2005). 또한, 광산지역에서의 광업 활동으로 인해 활성화된 황철석 산화로 발생하는 Fe 및 Ni 농도를 예측하기 위해 서포트 벡터 머신(support vector machine, SVM) 모델이 적용되었으며, 이 모델은 Fe 및 Ni 농도 예측에서 우수한 결과를 보였다고 발표되었다(Gholami et al., 2011). 더 나아가 상수도 및 하수도 등 수처리 공정과 슬러지 처리 공정의 기존 문제점을 개선하기 위한 기계학습 기반 연구가 꾸준히 진행되어 왔으며, 인공지능 기술을 활용한 약품 투입량 최적화와 비용 절감으로 수처리 시설의 운영비용을 20 ~ 30% 절감할 것으로 기대되고 있다(Alam et al., 2022). 한편, 최근 국내에서도 한정된 수자원의 효율적 이용을 위해 환경산업 및 수처리시설에 대한 디지털 모델과 기계학습 적용 사례들이 증가하고 있다. 빅데이터의 수집이 용이한 정수장과 같은 수처리시설에서는 응집제와 같은 약품의 투입 비율에 대한 연구가 주로 이루어졌다. Kim et al.(2021)과 Hyung(2022)는 인공지능 기반의 빅데이터 분석과 예측을 통해 원수의 수온, 탁도, pH, 전기전도도와 같은 다양한 입력변수를 기반으로 정수장에서 사용하는 응집제 투입률을 결정하는 예측 모델을 개발하였으며, 장기적인 응집제 사용 계획 수립에 활용할 수 있을 것으로 전망했다. 한편, 정수장 단위공정의 성능 향상을 위해 혼화-응집 공정과 송수 펌프 시스템의 빅데이터를 기반으로 LSTM(long short-term memory)을 적용한 운영 모델을 구축하고, 빅데이터를 활용한 공정관리 요소의 최적 모델과 정수장 각 공정에의 확장 적용을 통해 운영 시스템의 실무 도입 가능 방안이 제시된 바 있다(Kim, 2021). 또한, 하수 처리 빅데이터를 활용하여 기계학습 모델을 구축하고, 이를 통해 실시간 측정이 어려운 COD와 같은 수질 요소를 사전 예측하는 모델을 개발하여 향후 제어 시스템 개발에 기여할 것으로 전망하였다(Joo, 2022). 하천에 기계학습을 적용한 사례로는, 하천 유량 및 수질 예측을 위해 신경망 알고리즘이 다른 기계학습 알고리즘에 비해 우수한 성능을 보여 수환경 데이터 분석에 보다 범용적으로 적용될 수 있을 것으로 평가되었다(Jun et al., 2020). 이와 같이 국내 환경산업 및 수처리시설에 대한 기계학습 활용 연구가 다수 진행된 반면, 국내 광산배수 수질정화시설에 특화된 공정 정화 효율 추정 및 예측을 위한 기계학습의 적용 연구는 지금까지 보고된 사례가 없어 매우 미흡한 실정이다.
따라서, 본 연구에서는 광산배수 처리시설 내 소석회 투입 공정의 효율적 운영 및 설계를 위하여 기계학습 방법 중 정답(label)을 알고 있는 훈련자료에서 예측 함수를 유추하는 지도학습 방법을 적용하고자 하였다. 이는 결과를 아는 자료로부터 예측 모델을 학습한 후, 이 모델을 새로운 데이터 분석에 적용하는 기술로 입력자료와 정답자료 간의 관계가 수식으로 명확히 표현되지 않을 때 자료들의 대응 관계를 학습하여 입력자료에 대한 정답자료를 예측할 수 있게 하는 방법이다. 한편, 기계학습 기법으로는 여러 다양한 기법들 중 변수들 간의 상관관계성을 자동으로 추출해 줄 수 있는 합성곱 신경망(convolutional neural network, CNN) 기법을 적용하였다. CNN은 매개변수 공유 방식을 통해 모델의 복잡도를 줄이고 효율성을 높일 수 있으며 차원을 축소하여 과적합을 방지할 수 있고, 이동 불변성을 통해 데이터 내 패턴을 위치에 상관없이 인식할 수 있다. 이와 함께 그래픽 처리장치(graphic processing unit, GPU)를 활용한 대규모 데이터 처리에도 적합해 다양한 분야에서 활용 가능한 장점이 있다. 이를 통해 연구 지역인 폐탄광 수질정화시설 2개소(ST와 HT)의 자료를 활용하여 합성 필터(convolutional filters)를 이용해 추출한 특성 맵(feature map)을 기반으로 하는 CNN 기반 소석회 투입량 예측 모델을 개발하였으며, 수질 특성 및 유량 범위가 다른 2개의 탄광을 적용함으로써 다양한 특성을 가지는 광산배수에 확대 적용이 가능한 일반화된 모델을 도출하고자 하였다.
연구 지역
연구대상지 선정
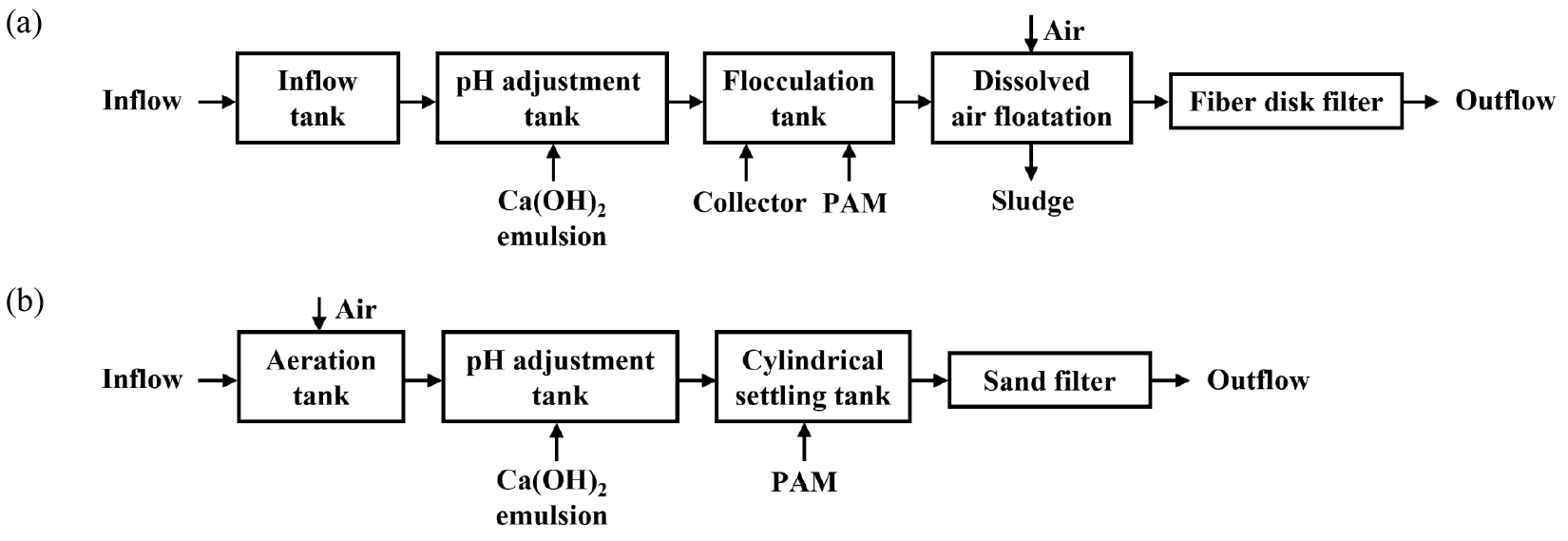
본 연구에서는 국내 광산배수 적극적 처리시설 중 소석회 투입을 적용하는 시설(11개소) 중 2개소(ST와 HT)를 선정하였다(Fig. 1). 첫 번째로, 강원도 정선군에 위치한 폐탄광의 폐석장 침출수를 대상으로 한 적극적 수질정화시설(ST)은 2017년 12월에 완공되어 운영 중이며, 주 오염물질은 Fe, Mn 및 Al이고 6년간 평균 처리유량은 3,052 m3/day이다. 처리공정은 유입수조, pH 조정조, 응집조, 가압 부상조 및 섬유디스크필터로 이루어져 있으며, 알칼리제로는 액상 소석회를 투입하고 있다. 두 번째로, 강원도 태백시에 위치한 폐탄광 갱내수의 적극적 수질정화시설(HT)은 Fe과 Mn를 처리하기 위한 시설로, 평균 처리유량은 6,099 m3/day이며 폭기조, pH 조정조, 원형 침전조 및 사여과기의 단위공정으로 구성되어 있고, 알칼리제로는 분말 소석회를 현장에서 액상으로 만들어 투입하고 있다(Table 1 and Fig. 2). 두 시설 모두 시설 약품비 및 인건비 등의 운영 비용이 지속적으로 발생하고 있으며, 이 중 약품비 등의 절감을 위한 효율적 관리 대책이 요구되고 있다.
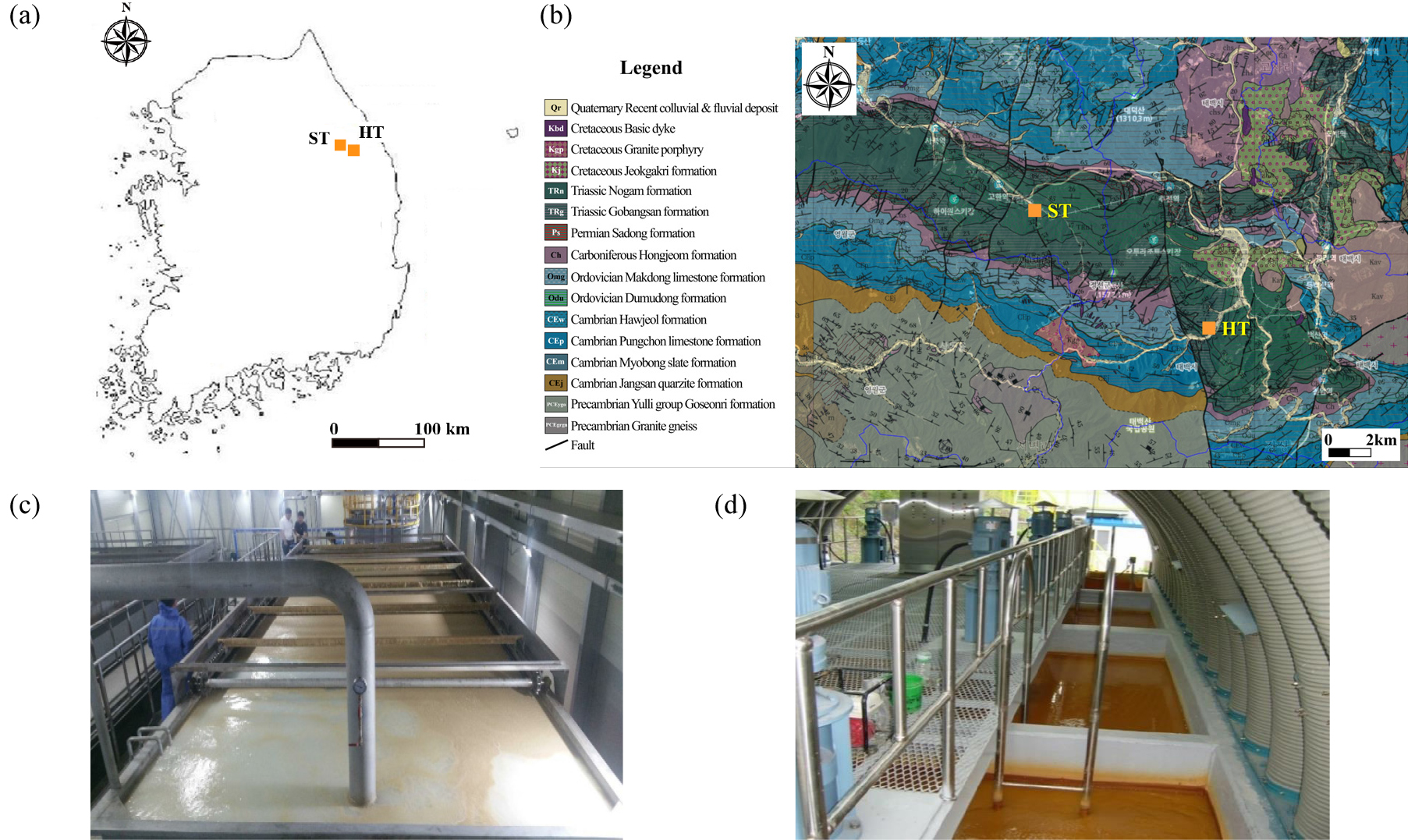
Fig. 1.
(a) Sampling location map, (b) geological map (Geo Big Data Open Platform, 2024), and (c-d) photos of (c) ST and (d) HT mine drainage treatment facilities.
Table 1.
Characteristics of water treatment facilities
연구지역 지질 및 기상 현황
ST와 HT가 위치한 지역의 광역지질은 선캄브리아시대, 고생대 캄브리아기, 오르도비스기, 페름기 및 중생대 트라이아스기, 백악기, 신생대 제4기에 형성된 퇴적암과 변성암으로 주로 구성되어 있다. 이 지역은 태백산 분지에 위치하며, 하부로부터 고생대 조선누층군의 대석회암 상부층, 평안누층군의 홍점층, 사동층, 고방산층, 녹암층이 분포한다. 오랜 지질 시대 동안의 지각운동으로 지질구조가 상당히 복잡하다. 주요 암상은 사암, 셰일, 석회암, 석탄층 등으로 구성되어 있으며, 광물 자원 중 석탄과 기타 금속 자원이 풍부하게 분포한다(Fig. 1b, Geo Big Data Open Platform, 2024). 연구지역인 ST는 중생대 트라이아스기의 평안누층군의 녹암층에 위치하며, 대표암상으로는 암록색 사질 셰일, 황록색 사질 셰일, 암록색 사암이 분포한다. 그리고 HT는 고생대 페름기의 평안누층군의 고방산층에 위치하고 있으며, 대표암상으로는 유백색 사암, 회색 사암, 흑색 셰일로 구성되어 있다. 이 지역은 내륙 산간지대로 대륙성 기후를 나타내며, 봄과 가을은 짧아 식물의 생육 기간이 제한적이며, 겨울은 한랭 건조한 대륙성 고기압의 영향으로 춥고 건조하며 길다. 연평균 강수량은 약 1,352에서 1,429 mm 사이로, 전체 강수량의 약 60 ~ 70%가 6 ~ 9월에 집중적으로 발생한다(Weather and Climate, 2024; Timeanddate, 2024; MIRECO, 2019).
연구지역 광산개발 및 수질정화시설 현황
ST 수질정화시설의 유입수는 SC 탄광의 폐석장에서 유출되며, 이 탄광은 우리나라 최대 탄광으로 1964년 채광인가를 받아 2001년 광업권 소멸 시까지 약 4,198만 톤의 질 좋은 무연탄을 생산하였다. 폐석장에는 운반된 굴진 폐석과 채탄 후 선별 과정을 거쳐 버려진 폐석이 혼합되어 적재되어 있으며, 상부 계곡수와 강수 및 지하수가 폐석을 용출시켜 침출수가 유출된다. 2001년 폐광 이후 폐석장 침출수 수질 개선을 위해 2017년 12월 완공된 수질정화시설을 현재까지 운영하고 있다(MIRECO, 2019). 한편, HT 수질정화시설의 유입수는 HT 탄광 HB 갱으로부터 배출되며, 이 HT 탄광은 1954년 개발되어 1993년 폐광시까지 약 40년 동안 약 1,800만 톤의 양질의 무연탄을 생산한 주요 탄광이었다. 석탄 광산의 경제성이 낮아지면서 폐광하였는데, 그 이후 갱내수의 수질을 개선하고자 2004년부터 조성된 수질정화시설을 현재까지 운영하고 있다(Newsis, 2024).
머신러닝 학습자료 준비 및 학습
자료의 특성 평가
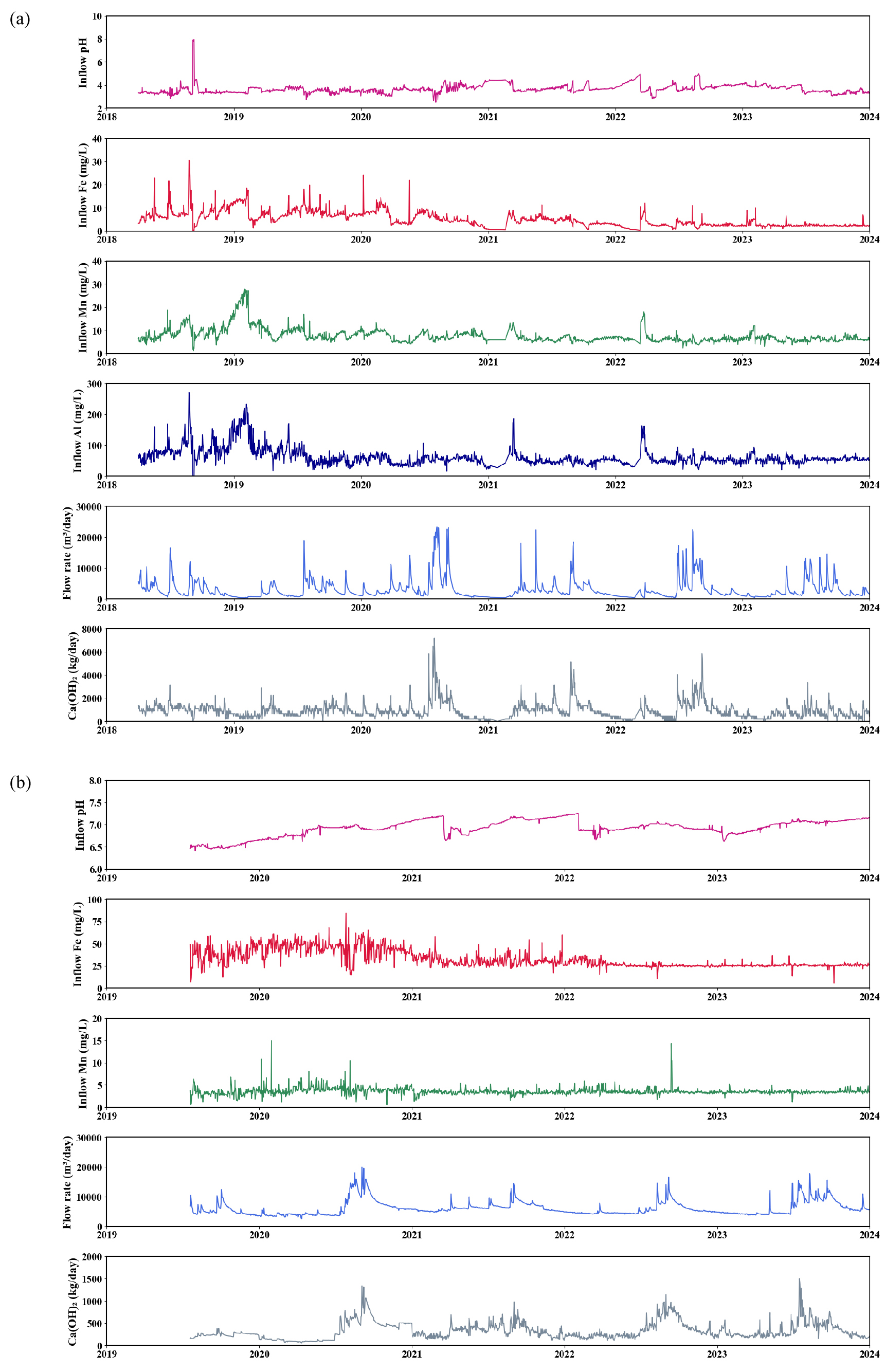
ST 수질정화시설 유입수의 수질을 분석한 결과는 다음과 같았다. pH는 2.51 ~ 7.96까지 넓은 범위를 보이나, 평균 pH는 3.6으로 대부분 강한 산성을 띠고 있었다. 백화현상을 유발하는 주 원인물질인 Al 농도는 0 ~ 274 mg/L의 범위에서 평균 62.2 mg/L로 측정되었고, Mn 농도는 1.1 ~ 27.8 mg/L(평균 7.7 mg/L)로 나타났으며, Fe 농도는 0.1 ~ 30.5 mg/L(평균 5.1 mg/L)로 측정되었다. 이는 철이 효과적으로 산화, 제거되며 pH가 낮고 Al 농도가 높은 전형적인 폐석장 침출수의 특성을 나타낸다. 한편, 우기 시에는 대체로 금속이온 농도가 낮았으나, 겨울철 등 유량이 적은 시기에 금속이온 농도가 공통적으로 높게 나타났다(Fig. 3). 이에 따라 피어슨 상관계수법에 따른 heatmap으로 분석한 ST 수질정화시설 유입수의 Al, Fe, Mn 농도 간의 상관관계도 0.61(Al vs. Fe), 0.81(Al vs. Mn), 0.66(Fe vs. Mn)으로 높게 나타났다(Fig. 4). 유량은 319 ~ 23,351 m3/day(평균 3,052 m3/day)로 넓은 변화 폭을 보였다. 특히 우기에는 SC 폐석장 상부의 계곡수가 집중적으로 폐석장으로 유입되어 침출수량이 증가하는 것으로 보인다. 또한, 소석회를 투입한 이후 ST 정화시설 유출수의 Al, Fe, Mn 농도는 대부분 2 mg/L 이하로 매우 안정적으로 유지되고 있었다. 한편, HT의 경우, 1993년 폐광된 HT 탄광의 갱구로부터 유출된 물로서, pH는 6.41 ~ 7.25 범위(평균 6.9)로 ST에 비해 상대적으로 높은 수치를 보였다. Mn 농도는 0.6 ~ 15.0 mg/L(평균 3.6 mg/L)로 ST보다 약간 낮았으며, Fe 농도는 5.8 ~ 84.2 mg/L(평균 32.6 mg/L)로 ST보다 상당히 높은 값을 나타내었다. 반면, Al은 HT 유입수에서는 검출되지 않았다. 따라서 HT 정화시설 유입수는 석회석 부존 지역에서 중화된 갱내수의 특성을 나타낸다. 유량은 2,550 ~ 20,035 m3/day(평균 6,099 m3/day)로, ST보다 대체로 많았다. 역시 소석회를 투입한 이후 HT 정화시설 유출수의 Fe, Mn 농도도 2 mg/L 이하로 매우 낮게 유지되어 수질이 매우 양호하게 개선되었음을 확인할 수 있었다.
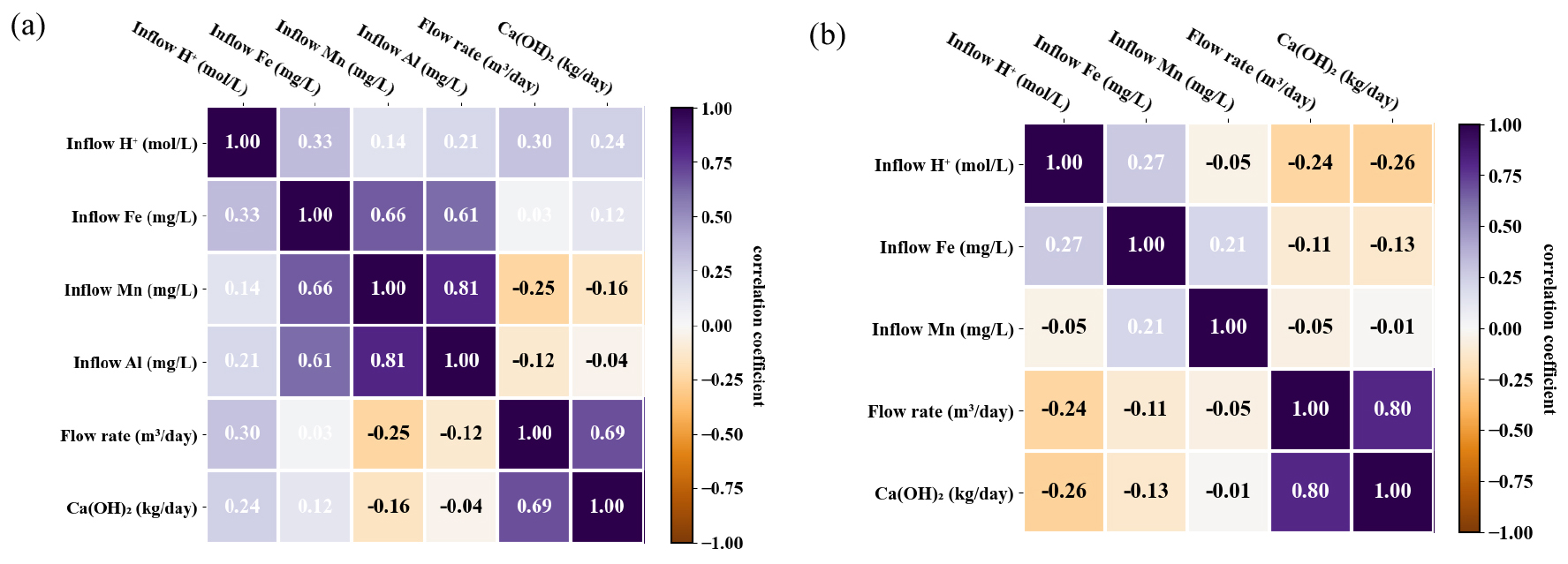
이러한 ST와 HT 자료를 이용해 기계학습 기반 소석회 투입량 예측 성능을 높이기 위해서 소석회 투입량과 상관관계가 있는 입력변수를 선정하고자, 피어슨 상관계수 방법을 사용하여 상관관계분석을 수행하였다(Kim et al., 2018). ST와 HT의 입력변수 간의 상관관계분석 결과를 heatmap으로 비교한 결과, 유량과 소석회 투입량의 상관계수(r)가 각각 0.69, 0.80으로 가장 밀접한 양의 상관관계를 보였다(Fig. 4). 이는 소석회 투입비율(농도)(mg/L)에 유량을 곱하면 소석회 투입량(kg/day)이 되므로 두 변수 사이에는 양의 선형적인 상관관계가 존재하여 상관계수가 높게 나온 것이다. 따라서 확실한 선형적 상관관계를 갖는 유량은 최종 입력변수로 선정하였다. 그러나 유량을 제외하고는 소석회 투입량과 선형적인 상관성을 보이는 다른 변수는 파악되지 않았다. 하지만 기계학습의 경우 여러 다변량 변수들이 복합적으로 갖고 있는 상관관계로부터 그 특성을 파악하여 학습을 수행할 수 있으므로 비록 heatmap에서 낮은 상관관계를 보여도 소석회 투입량과 관계가 있다고 실험적으로 알려진 변수들도 입력변수로 선정하였다. 연구 지역의 광산배수 처리시설에서 특정 pH를 유지하도록 소석회가 자동으로 투입되고 있으며, 이때 해당 pH는 Fe, Mn, Al 농도를 일반적으로 배출허용기준 이하로 모두 제거하기 위해 설정된다. 따라서, 소석회 투입량이 용존 Fe, Mn, Al 이온종들을 각각 Fe, Mn, Al 수산화물로 제거하기 위한 OH‒ 이온의 공급량이므로, 소석회 투입량과 상관성은 낮아 선형적이지는 않지만 이론적 관계가 있는 변수들인 pH와 Fe, Mn, Al 농도 또한 최종 입력변수로 선정하였다.
학습자료의 선정
수질정화시설 현장에서 지난 6년 동안 대부분의 자료가 수기로 기록되었으며, 일부 자료는 지구화학적으로 유효하지 않은 값들이 포함되어 있어 이들 자료를 면밀히 검토하는데 많은 시간이 소요되었으며, 검토 후 이상치를 제거하였다. ST의 경우, 한국광해광업공단에서 제공해 준 2017년 12월 27일 ~ 2023년 12월 31일까지 축적된 측정 자료 중 결측치 및 기록오류 자료를 제외한 자료 개수는 총 2,145개였다. 이때, 유입수의 pH가 4.5 이상임에도 불구하고 Al 농도가 10 mg/L 이상인 115개 중 102개, 양이온 시료 채수 시 여과를 수행했던 시기인 2021년 10월 27일 이전에 pH 4.5 이상 유입수 SS 농도 30 mg/L 이상인 자료 3개, 2023년 자료 중 소석회 투입량이 5 m3/day보다 적은 자료 4개, 2018년 3월 31일 이전 자료 48개, 소석회 투입을 통해 제대로 처리되지 않은 자료 4개까지 합해 총 161개 자료를 제외하여 최종적으로 1,984개의 자료를 학습자료로 선정하였다. 한편, HT의 경우, 한국광해광업공단으로부터 제공받은 6년 동안의 측정 자료(2018년 1월 1일 ~ 2023년 12월 31일) 중 결측치를 제외한 자료 개수는 총 2,160개였다. 이 중 수질정화시설 계측 자동화 이전인 2019년 7월 19일까지의 자료인 565개, 방류수 pH가 6 미만인 자료 2개, 방류수 Fe 농도 2 mg/L 이상 자료 1개, 방류수 Mn 농도 2 mg/L 이상 자료 1개, 방류수 SS 농도 2 mg/L 이상 자료 1개, 유입수 pH 7.5 이상인 2개를 제외하였다. 이때 방류수 pH가 6 미만이면서 Fe 농도가 2mg/L 이상인 자료가 1개 있어 중복되어 1개를 더해주었다. 따라서 총 571개 자료를 제외하여 최종적으로 1,589개의 자료를 학습자료로 선정하였다.
Fancy PCA를 이용한 학습자료증대
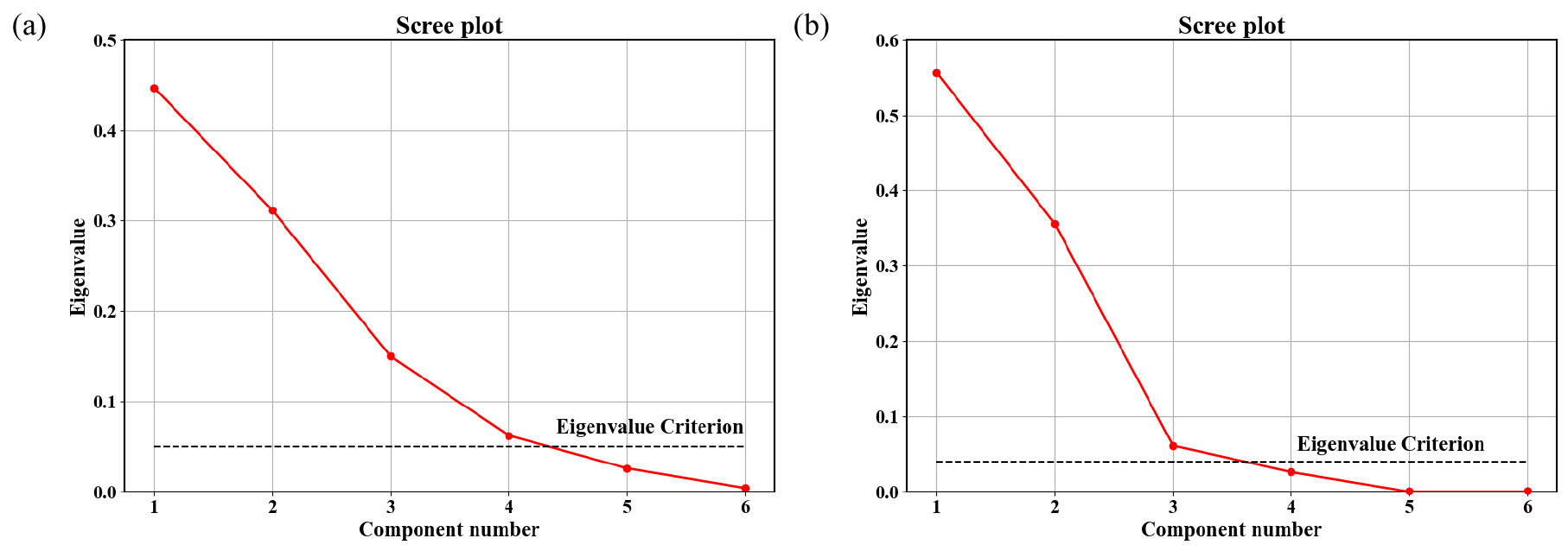
6년 동안 하루에 한 번씩 측정된 자료에서 위에서 설명한 대로 이상치를 제거한 자료는 CNN 모델을 충분히 훈련시키기에는 자료의 절대적인 양도 부족하며, 자료의 편중으로 인해 자료 불균형(data imbalancing) 문제도 존재했다. 따라서 이미지(image) 처리에서 이미지의 특성을 유지하며 유사한 자료를 생성하는 데 사용되는 ImageNet 분류에서 처음 언급된 fancy PCA(principal component analysis) 자료증대 기법(Kim et al., 2020)을 원본 자료의 특성을 유지하면서 제한된 자료의 양을 늘리기 위하여 채택하였다. Fancy PCA 기법은 식 2와 3에 나타낸 것처럼 원본 자료의 PCA 분석을 수행하여 영향력이 큰 고유값(eigenvalue)을 선정한 뒤 이 고유값들에 약간의 변화를 주어 새로운 자료들을 생성하는 방법이다. ST(1,984개)와 HT(1,589개) 중에서 학습 후 성능 평가를 위해 각각 10%의 테스트(test) 자료(ST 199개, HT 159개)를 분리한 후, 남은 90%인 ST 1,785개와 HT 1,430개 자료에 대해 각각 자료증대를 수행하였다(Fig. 5). 2개 시설의 자료증대를 위해 수행한 PCA 분석에 5개의 입력자료(pH, 유량, Fe 농도, Mn 농도 및 Al 농도)와 1개의 정답자료(소석회 투입량)를 사용하였으므로, 증대에 활용될 자료는 ST의 경우 1,785개×6, HT의 경우 1,430개×6의 행렬이다. 이 행렬에서 6개의 고유값을 구해 나타낸 것이 Fig. 6이다. Fig. 6과 같이 ST와 HT는 각각 4개와 3개의 고유값을 자료증대를 위해 선정하였다. 또한 PCA에 의해 구해진 고유벡터(p)와 식 2와 3을 이용하여 자료증대를 수행하였다. 이때 α는 평균 0, 표준편차 0.1인 가우시안 정규 분포를 따르는 무작위 값을 생성하여 사용하였다.
(P: 고유벡터로 구성된 행렬, αi: 평균이 0이고 표준편차가 0.1인 가우시안 정규 분포에서 추출한 i번째 무작위 값, λi: i번째 고유벡터와 대응되는 i번째 고유값)
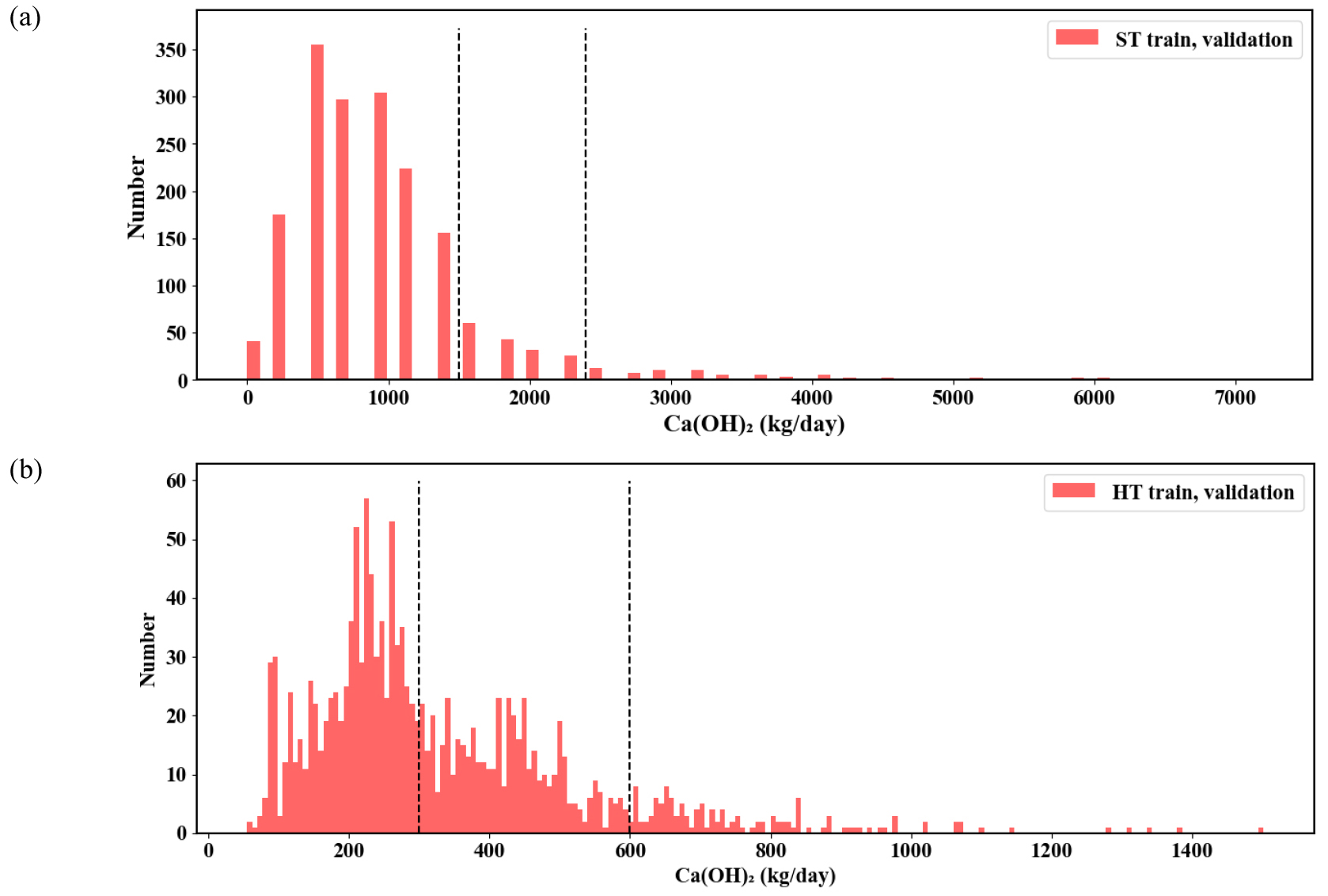
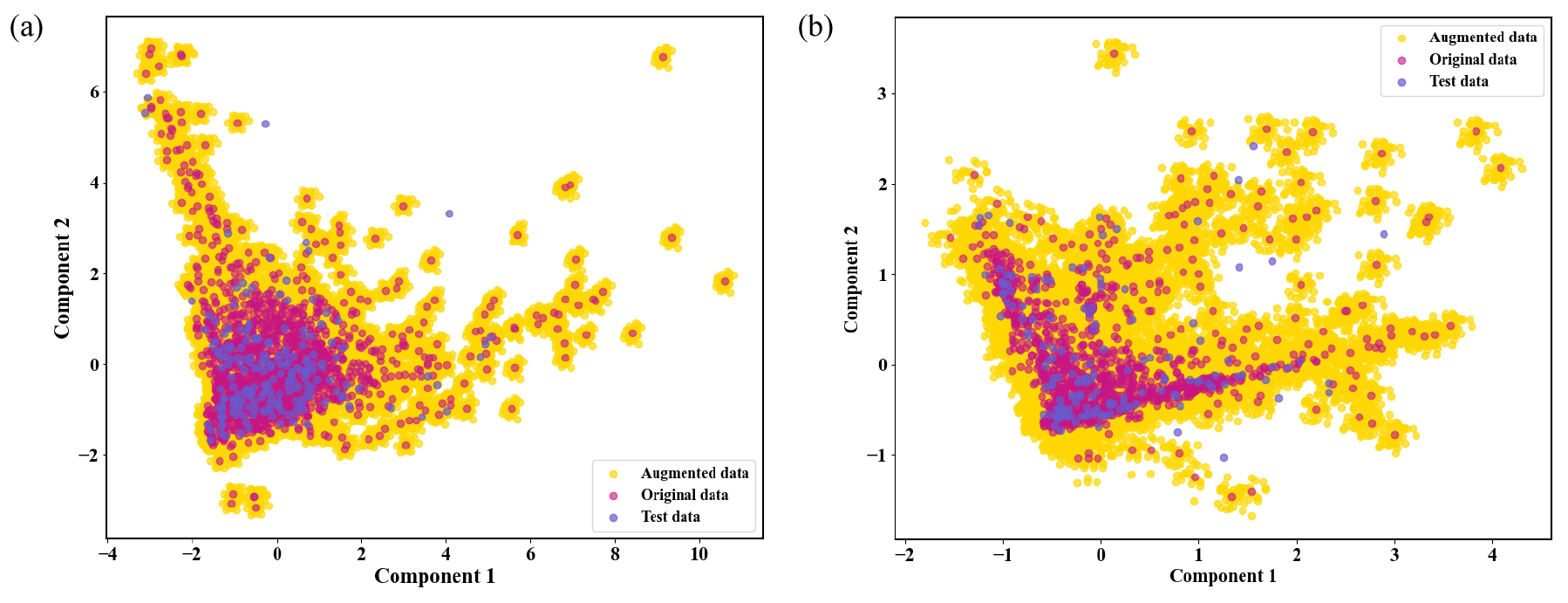
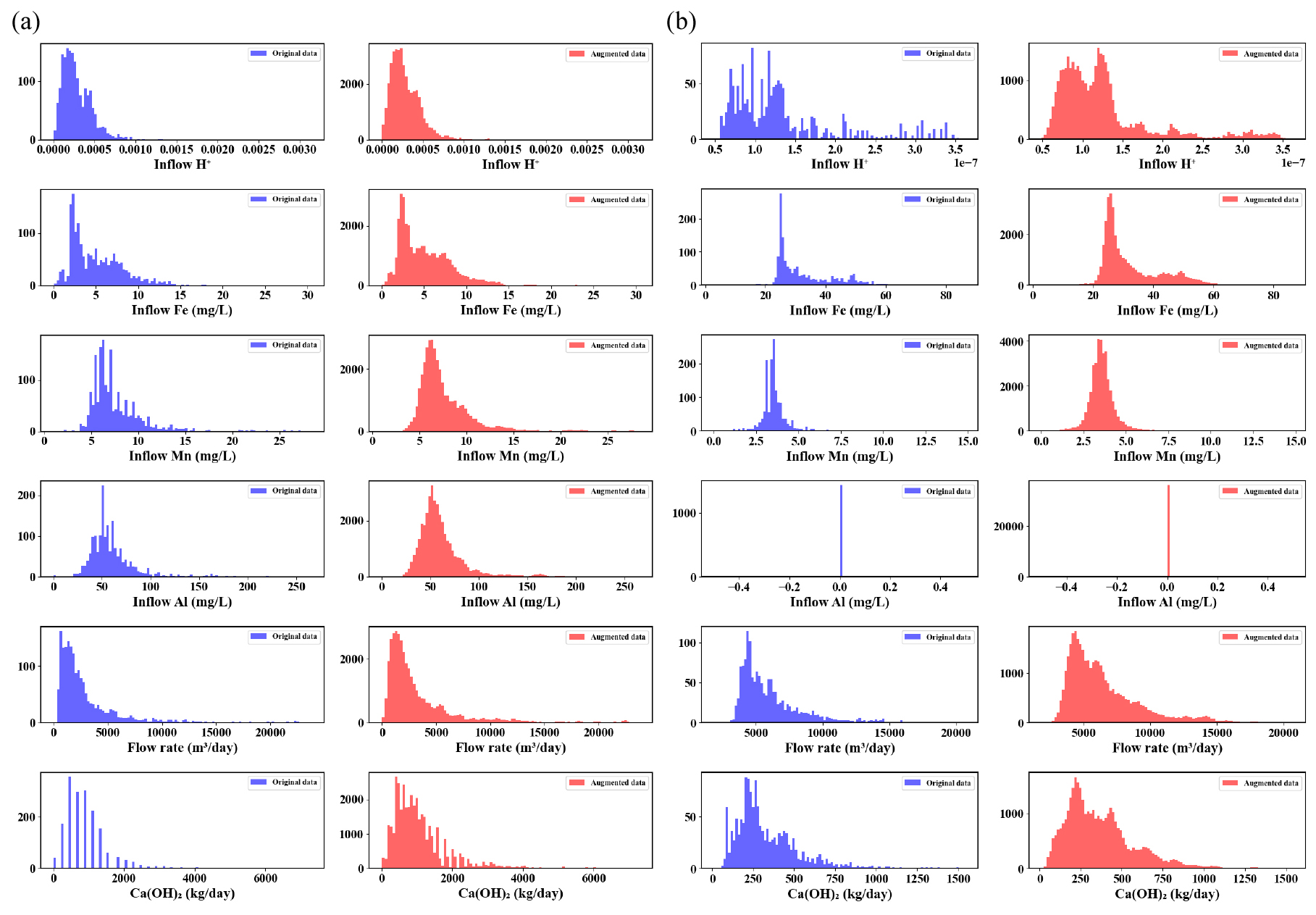
자료증대 시 자료 불균형 문제를 완화하기 위해 ST 자료는 소석회 투입량을 1,500 kg 미만, 1,500 kg 이상 2,400 kg 미만, 2,400 kg 이상의 세 구간으로 나누고(Fig. 5a의 점선), 각 구간의 비율을 20:30:40으로 설정하여 자료증대를 진행했다. 한편, HT의 경우, 소석회 투입량을 300 kg 미만, 300 kg 이상 600 kg 미만, 600 kg 이상으로 나누고(Fig. 5b의 점선), 각 구간의 비율도 20:30:40으로 배분하여 자료증대를 수행했다. ST와 HT의 증대된 자료가 자료증대 시 사용된 원본 자료에 근접하게 잘 증대되었는지를 확인하기 위해 증대된 자료를 원본 자료와 함께 PCA 분석 결과 얻어진 첫 번째와 두 번째의 주성분에 대한 2차원 평면상에 나타내어 보았다(Fig. 7). ST와 HT의 증대된 자료가 원자료 주변에 잘 형성되어 있으며, 테스트 자료도 일부를 제외하고는 증대된 자료 범위 내에 포함됨을 확인할 수 있었다. 또한 Fig. 8과 같이 원본 자료와 증대된 자료의 히스토그램을 비교해 본 결과, 왼쪽의 원본 자료 히스토그램 분포 범위 내에서 증대된 자료가 모든 변수에 대해 자료가 잘 생성되었고, 원본 자료에서 유량과 소석회 투입량이 급격히 낮은 빈도수를 보이는 영역에서 증대 이후 빈도수가 높아져 잘 증대됨을 확인하였다.
CNN모델의 구성 및 학습
일반적으로 머신러닝 모델을 이용한 학습에서 입력자료의 선정은 매우 중요하다. 입력자료의 변수가 너무 상세하고 많을 경우 학습이 잘 이루어지지만 모든 입력 변수들을 오차 없이 측정해야 하는 어려움과 함께 일반화(generalization) 성능이 낮아져 결과 예측력이 떨어지는 반면, 입력자료의 변수가 너무 적으면 적절한 학습 자체가 어려워진다(Duda et al., 2001). 따라서 이 연구에서는 앞서 제시한 대로 상관관계분석을 통한 유량과 금속오염물질을 제거하기 위한 OH‒ 이온의 공급원인 소석회와 이론적 관계가 있는 pH, 금속이온(Fe, Mn, Al) 농도인 총 5개의 입력자료와 1개의 정답자료(소석회 투입량)를 선정하였다. 이때, CNN 모델이 입력변수와 정답 간의 관계를 보다 쉽게 파악하여 학습할 수 있도록 하기 위해 입력자료 중 pH는 정답자료와 선형적인 관계를 갖도록 H+ 농도로 변환한 후 사용하였다. 따라서 CNN 학습 모델의 입력자료는 Fig. 9에 나타낸 바와 같이 5×1의 벡터 형태를 갖게 구성되었다. CNN 모델은 합성곱 필터(convolutional filters)를 이용해 입력자료의 서로 다른 특성들을 추출해 내는 특성 맵(feature map)을 만들고 이러한 과정을 여러 층을 이용하여 수행하며 각 층의 가중치(weighting parameters)들을 학습을 통해 업데이트 해나간다. 이 연구에서는 소석회 투입량 예측을 위해 Fig. 9와 같이 4층의 합성곱 층(convolution layer)과 1층의 밀집 층(dense layer)을 결합하였다. 각 층의 특성 맵(feature map)은 각각 16, 32, 16, 8개로 구성하여 보다 많은 자료의 관계성을 잘 파악할 수 있도록 하였다. CNN 모델에서 입력 자료의 특징을 추출하는 데 사용되는 커널(kernel; 합성곱 필터, convolutional filters) 크기는 3으로, 모델의 과적합을 방지하기 위해 훈련 중 무작위로 일부 뉴런을 생략하는 비율인 드롭아웃 비율(dropout rate)은 10%로 설정하였다. 학습률(learning rate)은 10-3으로, 손실 함수(loss function)로는 L1 norm(평균 절대 오차; mean absolute error, MAE)을 사용하였다. 커널 초기화(kernel initializer)는 he_normal 초기화 방법을 사용하여 초기 가중치를 설정하였고, 합성곱 연산 후에도 입력 크기를 유지하기 위해 제로 패딩(zero-padding)을 적용하였고, 학습을 안정화하고 수렴 속도를 향상시키기 위해 배치 정규화(batch normalization)을 적용하였다. 또한, epoch는 3,000으로 설정하였으며, early stopping 기법을 적용하여 validation이 100회 이상 개선되지 않으면 학습을 중단하도록 설정하였다. 입력자료의 스케일링에는 표준 스케일러(standard scaler)를 사용하였고 서로 단위가 다른 H+ 농도, 유량 및 금속이온(Fe, Mn, Al) 농도는 각각 스케일링하였다. 입력값과 출력값이 비슷한 범위의 값을 가져 학습이 효율적으로 이루어지도록 정답자료인 소석회 투입량 또한 표준 스케일러(standard scaler)를 사용하여 스케일링하였다.
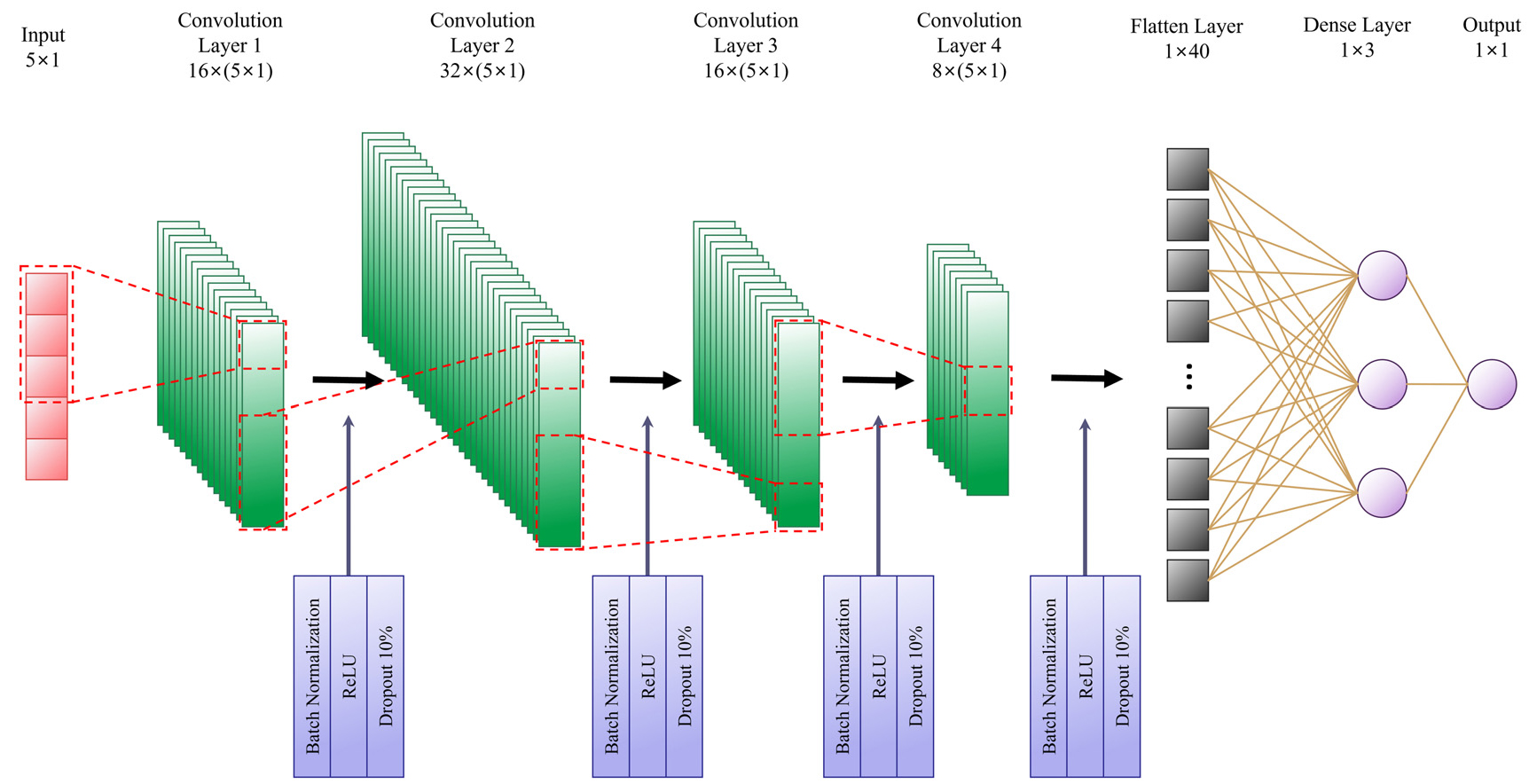
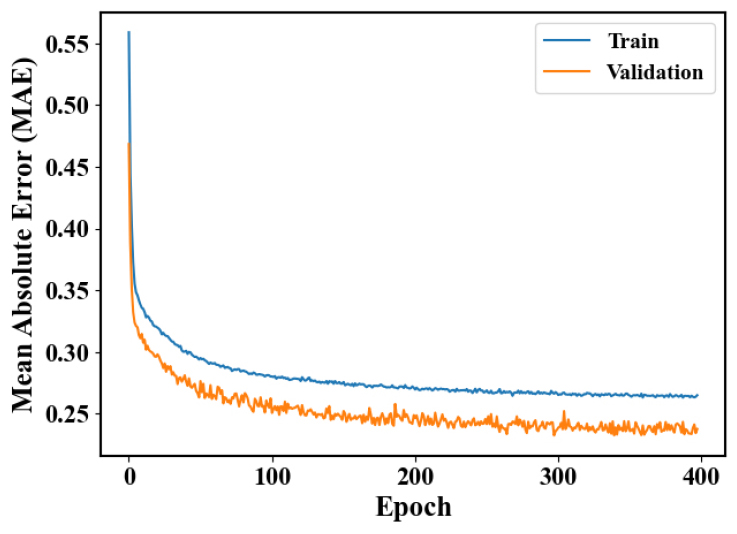
최종적으로 fancy PCA로 증대된 학습자료를 이용하여 소석회 투입량 예측 CNN 모델의 학습을 진행하였다. Fancy PCA를 이용하여 증대된 자료 중 테스트 자료를 분리한 나머지 ST 1,785개와 HT 1,430개 자료에 대해 80%를 훈련(train) 자료, 20%를 검증(validation) 자료로 분리하여 CNN 모델의 훈련을 수행하였다. 총 398회까지 학습이 진행되었으며, validation 과정에서 평균 절대 오차(MAE)가 가장 낮았던 298번째 모델이 최적(best) 모델로 저장되었고, 최종적으로 이 모델이 사용되었다. 결과적으로, Fig. 10에서 확인할 수 있는 것과 같이 손실 곡선은 과적합(overfitting)없이 잘 수렴하였고, 학습이 성공적으로 완료되었음을 확인할 수 있었다.
학습된 머신러닝 모델의 예측 결과 고찰
유입수의 pH 및 금속이온 농도에 기반한 단순 이론적 계산(식 1)에 의한 소석회 투입량의 예측값은 실제 현장에서 투입된 소석회량과 큰 차이를 보였다. 이론적 계산식에 의해 계산된 소석회 투입량보다 2개 시설의 실제 소석회 투입량이 산점도(scatter diagram)에서 많은 자료가 X축에 치우쳐 분포하는 양상을 나타내었다(Fig. 11a, b). 특히 ST의 경우 산점도에서 자료들이 뚜렷한 선형성을 보이지 않고 1:1라인에서 상당히 많이 벗어나는 자료들이 다수 관측되었으나, HT의 경우는 1:1라인 부근에 모여있는 것을 알 수 있었다. 또한 테스트 자료(ST 199개, HT 159개) 중 ST 154개, HT 97개가 실제로 투입된 양에 비해 이론적으로 계산된 값이 적게 예측되고 있다는 것을 보여주었다. 이로 보아 어느 정도 관계성을 보였주었다고 할 수 있다. 그리고 R2인 결정계수 값이 일반적인 범위인 0 ~ 1를 벗어나는 값인 –0.6565를 나타냈는데, 이는 앞의 서론에서 이미 언급된 바와 같이 현장측정치인 알칼리도의 미측정 등과 같은 근본적인 이유에 의해 알칼리도 값을 뺐기 때문에, 이론적 계산식의 소석회투입량의 예측치가 매우 낮게 예측되는 한계점으로 인해 결정계수 값이 일반적인 범위를 벗어나는 값을 가지게 되었을 것으로 사료된다(Fig. 11a, b). 반면, 이 연구에서 제안한 fancy PCA를 이용하여 증대된 자료로 훈련된 CNN 모델은 훈련 과정에서 사용되지 않은 테스트 자료 세트에 대해 더 낮은 평균 절대 오차(MAE)와 높은 결정계수(R2)를 나타내어 좋은 성능을 보였다(Table 2). 소석회 투입량에 따른 자료 불균형을 해결하기 위해 사용된 서로 다른 비율의 자료증대는 이 연구에서 사용된 자료들처럼 자료의 불균형 문제가 발생했을 때 이를 보완할 수 있는 좋은 대안이 될 수 있다. 그러나 실제로 이런 방법으로의 자료증대는 실제 원본 자료가 없을 시 자료의 생성이 불가능하므로 원본 자료가 전체 자료를 대표할 수 있도록 발생가능한 모든 범위 내의 특성을 대표할 수 있는 최소한의 자료로는 구성되어 있어야 한다. 훈련된 CNN 모델은 평균 절대 오차(MAE) 0.2773, 결정계수(R2) 0.6568을 나타내어 기존의 단순 이론적 계산식에 비해 훨씬 좋은 예측 성능을 보여주었으나, 앞서 언급한 대로 원본 자료가 소석회 투입량에 따라 자료 불균형이 심하고 특히 소석회 투입량이 많은 자료의 양이 현저히 작게 측정되어 이 부분에 대한 예측 성능이 다소 떨어지는 것으로 판단된다. 또한 자료 측정의 자동화가 이루어지지 않은 자료가 대부분이어서 기록된 자료 자체의 오차가 다수 존재하는 것이 학습 성능을 저하시키는 가장 큰 원인으로 생각된다.
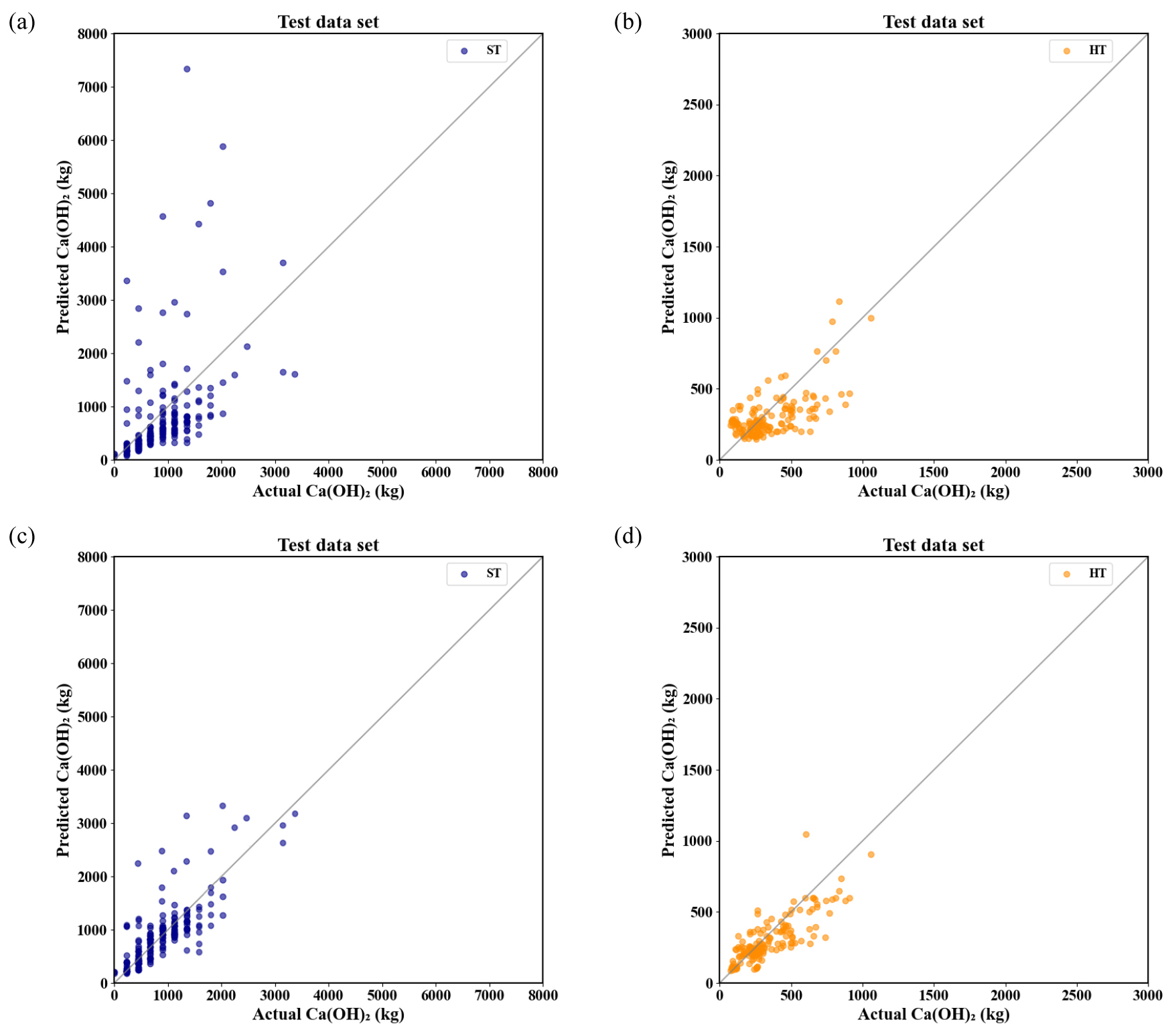
Table 2.
MAE and R2 values for theoretical calculation equation and CNN
| Test | Theoretical calculation equation | CNN |
| MAE | 0.5393 | 0.2773 |
| R2 | ‒0.6565 | 0.6568 |
예측한 소석회 투입량과 실제 현장에서의 소석회 투입량을 비교한 결과, 이론적 계산식에서 예측한 값보다 CNN 모델에서 예측한 값들 중 ST의 경우 소석회 투입량이 1,500 kg 이상인 일부 경우 다소 차이가 있었으나, 1:1 선에 상당히 근접해 있음을 확인할 수 있었다. HT는 대부분 1:1 선에 가까운 결과를 보였다(Fig. 11). 따라서 CNN 모델의 예측 결과는 현장에서의 실제 투입량과 유사하게 나타나, 소석회 투입량 관리에 있어 유용한 도구가 될 것으로 판단된다.
결 론
이 연구에서는 광산배수 처리시설 내 소석회 투입공정의 효율적인 운영 및 설계를 위하여, 데이터 기반 인공 지능 접근 방식 중 주목받고 있는 기계학습 기법을 사용하여 서로 다른 특성을 가지는 2개의 국내 광산배수 처리시설(ST와 HT)에 대하여 통합 모델을 도출하여 소석회 투입량을 예측하였다.
6년 동안 축적된 자료의 기계학습 모델 학습자료 적용성에 대한 면밀한 검토를 통하여 ST의 경우 2,145개, HT의 경우 2,160개의 원본 자료 중 이상치(ST 161개, HT 571개)를 제외하였다. 또한, 상관관계분석을 통하여 소석회 투입량(정답변수)과 양의 관계성을 보이는 유량과 광산배수 처리시설에서 특정 pH를 유지하도록 소석회가 자동으로 투입되는데 이때 해당 pH는 금속이온(Fe, Mn, Al) 농도를 일반적으로 배출 허용기준 이하로 모두 제거하기 위한 것이여서 소석회 투입량은 용존 Fe, Mn, Al 이온종들을 각각 Fe, Mn, Al 수산화물로 제거하기 위한 OH‒ 이온의 공급량이므로 이론적 관계를 가지는 금속이온(Fe, Mn, Al) 농도와 pH를 기계학습 모델의 입력자료로 최종 선정하였다. 다음으로, 소석회 투입량 예측을 위한 CNN 모델을 개발하고 훈련하고자 하였다. 이때, 학습에 사용가능한 자료 자체가 가지는 자료의 양 및 불균형으로 인한 문제를 해결하기 위하여 fancy PCA 자료증대 기법을 이용하여 자료의 증대를 실시하였다. Fancy PCA 자료증대 기법으로 증대된 자료들은 PCA 분석 및 히스토그램 비교를 통하여 원본 자료의 특성을 유지하면서도 제한된 자료의 양을 효과적으로 증대시켜줬음이 확인되었다. 이렇듯 성격이 다른 두 광산배수를 대상으로 상당한 소석회 투입량의 차이를 보였음에도 2개의 시설에 대한 주어진 시계열 자료를 최대한 활용하여 하나로 통합된 모델을 수립하였다. 이러한 광산배수 수질정화시설의 자료를 이용한 기계학습 기법의 적용은 그 자체로도 큰 의미가 있으며 특히 기존에 정확도가 많이 떨어지는 이론적 계산식에 비해 MAE가 48.6% 감소하여 오차를 상당히 줄일 수 있었다.
따라서 기계학습 기법을 활용하여 적정 소석회 투입량을 실시간으로 예측함으로써, 장기적으로는 적극적 광산배수 수질정화시설의 운영 효율을 높이고, 비용 절감에 기여할 수 있을 것으로 보인다. 향후 현재 확보되지 않은 다수의 정화시설들을 현대화하고 양질의 운영 빅데이터를 추가로 확보하여 이 연구에서 사용한 방법을 바탕으로 여러 적극적 광산배수 수질정화시설에 적용할 수 있는 통합 모델을 보완할 필요가 있다. 이러한 통합 모델의 개발은 향후 신규 시설 설계 시에도 소석회 투입량 등을 예측해 줌으로써 설계 정보를 제공할 수 있을 것이다.
